Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
2403.19838
0
0
📈
Abstract
Vision-Language Models (VLMs) and Multi-Modal Language models (MMLMs) have become prominent in autonomous driving research, as these models can provide interpretable textual reasoning and responses for end-to-end autonomous driving safety tasks using traffic scene images and other data modalities. However, current approaches to these systems use expensive large language model (LLM) backbones and image encoders, making such systems unsuitable for real-time autonomous driving systems where tight memory constraints exist and fast inference time is necessary. To address these previous issues, we develop EM-VLM4AD, an efficient, lightweight, multi-frame vision language model which performs Visual Question Answering for autonomous driving. In comparison to previous approaches, EM-VLM4AD requires at least 10 times less memory and floating point operations, while also achieving higher CIDEr and ROUGE-L scores than the existing baseline on the DriveLM dataset. EM-VLM4AD also exhibits the ability to extract relevant information from traffic views related to prompts and can answer questions for various autonomous driving subtasks. We release our code to train and evaluate our model at https://github.com/akshaygopalkr/EM-VLM4AD.
Create account to get full access
Introduction
The paper introduces EM-VLM4AD, an efficient and lightweight vision-language model designed for autonomous driving applications. Vision-Language Models (VLMs) have shown promise in solving tasks at the intersection of vision and language, making them useful for autonomous driving. However, current research in this area predominantly uses large models with over one billion parameters, which require expensive hardware and longer inference times. EM-VLM4AD addresses this issue by developing a smaller model that consumes at least 10x less memory and floating point operations (FLOPs) compared to current AD-VLMs. The model is trained on the DriveLM dataset and can respond to questions conditioned on multiple frames. The authors explore two lightweight language model backbones for EM-VLM4AD: a finetuned T5-Base and an 8-bit quantized T5-Large finetuned using LoRA. They compare the model's efficiency and performance on various metrics to the DriveLM dataset baseline, demonstrating stronger performance with superior efficiency using a much smaller model.
Related Research
The paper discusses the development of Vision-Language Models (VLMs) that combine natural language processing and computer vision techniques. These models encode images and text into a combined latent representation and learn correlations between them through cross-modal pre-training tasks. VLMs like CLIP, BLIP-2, and VL-T5 have shown strong performance across various tasks but are computationally expensive to deploy for real-time applications.
Researchers have begun integrating multimodal data to train language models for autonomous driving tasks. Models like DriveGPT4, DriveMLM, and GPT-Driver leverage large language models and visual encoders to generate answers and control signals for driving scenarios. However, these models use billion-parameter LLMs and expensive image encoders, making them unsuitable for real-time inference.
Processing multiple modalities and text is a challenge for most VLMs, which are pre-trained for single-image single-text problems. Techniques like pooling visual encodings of video frames, using QFormer to embed video and LiDAR data, and employing gated attention pooling across individual image embeddings have been explored to consolidate multiple modalities into a single embedding that can be used by a VLM.
The paper introduces a model that responds to multi-view image input and question prompts for autonomous driving tasks. It uses a frozen T5 language model during the first stage of training, allowing the image embedding network to align with the T5 embeddings. The model demonstrates the ability to perform visual question answering for perception, planning, and traffic agent behavior prediction tasks.
Methods
The paper introduces EM-VLM4AD, a model for Visual Question Answering in Autonomous Driving. It consists of a custom image embedding network and a pre-trained T5 language model.
The image embedding network uses a ViT patch projection embedding scheme to create latent image representations. These individual image embeddings from multiple views are combined using gated pooling attention to produce a single embedding. This is then concatenated with a text embedding and input into the language model to generate answer text.
For the language model, the authors use pre-trained T5 models (T5-Base and 8-bit quantized T5-Large) to reduce computational costs. They fine-tune these models to adapt them to the concatenated multi-view image and text embeddings.
EM-VLM4AD is trained on the DriveLM dataset using a two-stage approach. In the first stage, the image patch encoder and language model are frozen, and only the gated pooling attention and projection layer are trained. In the second stage, only the image patch encoder remains frozen while the language model is fine-tuned.
The models are trained for six epochs each, using specific hardware and hyperparameters. EM-VLM4AD outperforms the DriveLM-Agent baseline in all evaluation metrics.
Experiments
The paper analyzes the quantitative, qualitative, and computational performance of EM-VLM4AD using common image captioning metrics such as BLEU-4, ROUGE-L, METEOR, and CIDEr. The model is compared to DriveLM-Agent, the only existing approach on the DriveLM dataset. Both versions of EM-VLM4AD outperform DriveLM-Agent on all metrics, despite having significantly fewer parameters. The T5-Base version of EM-VLM4AD is the top-performing model.
The computational analysis shows that EM-VLM4AD is more efficient than other multimodal LMs for autonomous driving, requiring fewer parameters, FLOPs, and memory. The T5-Base backbone has the least parameters and FLOP count, while the T5-Large backbone has the least memory requirements due to 8-bit quantization.
Qualitative results demonstrate EM-VLM4AD's ability to accurately respond to various questions related to perception, traffic agent behavior, planning, and scene understanding. The model leverages general knowledge from pretrained components and can understand the c-tag format used in DriveLM. However, it occasionally generates grammatically incorrect answers and struggles with behavior-related questions that may require temporal context from multiple frames.
Conclusion
EM-VLM4AD is a compact multi-frame vision-language model designed for Visual Question Answering in autonomous driving applications. It offers advantages in memory efficiency and computational requirements compared to other language models tailored for autonomous driving. EM-VLM4AD outperforms DriveLM-Agent in BLEU-4, METEOR, ROUGE, and CIDEr metrics on a DriveLM test dataset. The model effectively answers various autonomous driving questions and focuses on relevant camera views using a gated pooling attention layer that integrates view embeddings.
Future research aims to develop EM-VLM4AD into a video-language model that can generate responses from multi-view video inputs, enhancing its capability to handle temporal-related questions. Incorporating multimodal retrieval augmented generation will enable the model to extract insights from similar traffic scenarios, providing additional context for improved performance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024
👀
Vision Language Models in Autonomous Driving: A Survey and Outlook
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, Alois C. Knoll
0
0
The applications of Vision-Language Models (VLMs) in the field of Autonomous Driving (AD) have attracted widespread attention due to their outstanding performance and the ability to leverage Large Language Models (LLMs). By incorporating language data, driving systems can gain a better understanding of real-world environments, thereby enhancing driving safety and efficiency. In this work, we present a comprehensive and systematic survey of the advances in vision language models in this domain, encompassing perception and understanding, navigation and planning, decision-making and control, end-to-end autonomous driving, and data generation. We introduce the mainstream VLM tasks in AD and the commonly utilized metrics. Additionally, we review current studies and applications in various areas and summarize the existing language-enhanced autonomous driving datasets thoroughly. Lastly, we discuss the benefits and challenges of VLMs in AD and provide researchers with the current research gaps and future trends.
6/26/2024
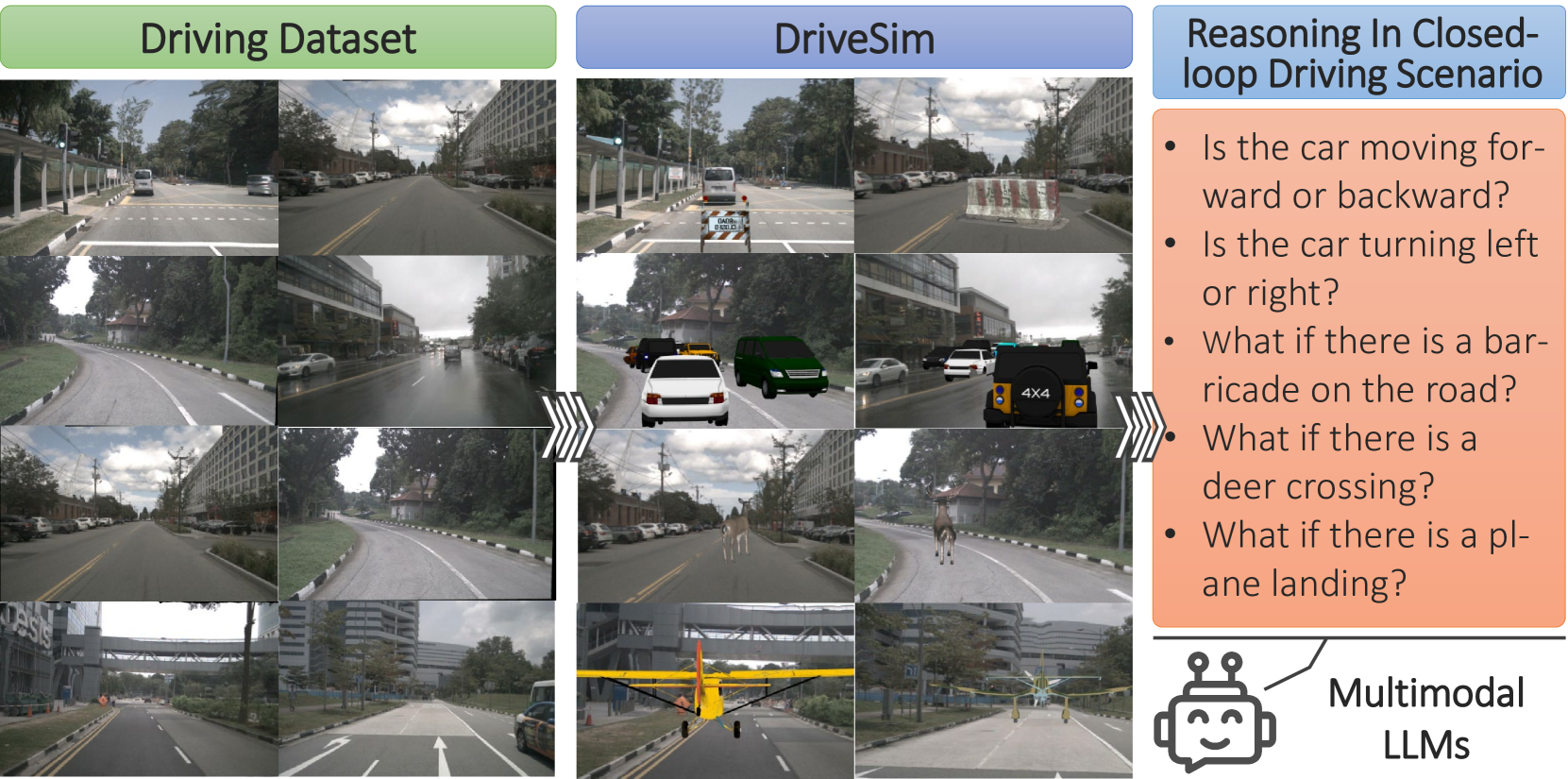
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
0
0
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
5/10/2024
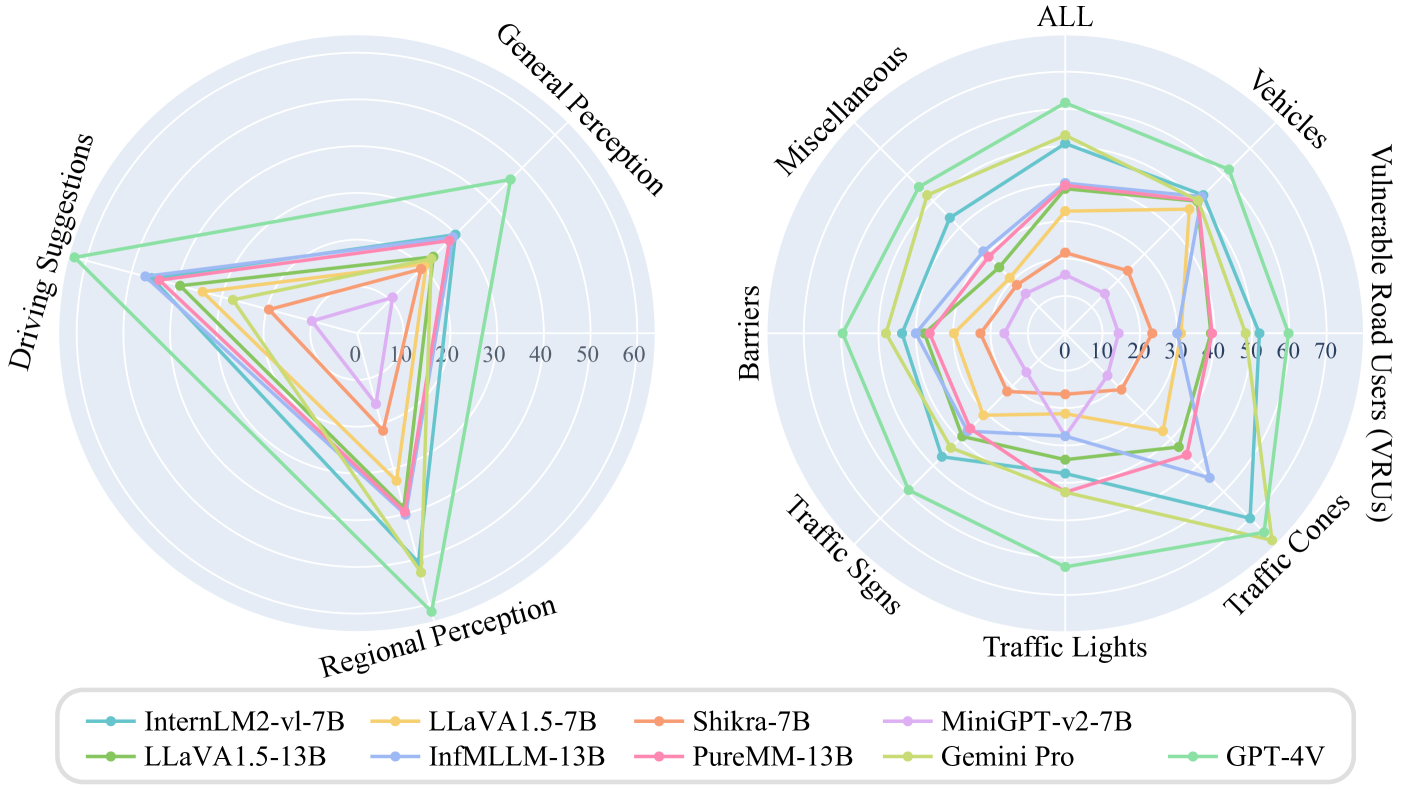
Automated Evaluation of Large Vision-Language Models on Self-driving Corner Cases
Kai Chen, Yanze Li, Wenhua Zhang, Yanxin Liu, Pengxiang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, Dit-Yan Yeung, Huchuan Lu, Xu Jia
0
0
Large Vision-Language Models (LVLMs) have received widespread attention in advancing the interpretable self-driving. Existing evaluations of LVLMs primarily focus on the multi-faceted capabilities in natural circumstances, lacking automated and quantifiable assessment for self-driving, let alone the severe road corner cases. In this paper, we propose CODA-LM, the very first benchmark for the automatic evaluation of LVLMs for self-driving corner cases. We adopt a hierarchical data structure to prompt powerful LVLMs to analyze complex driving scenes and generate high-quality pre-annotation for human annotators, and for LVLM evaluation, we show that using the text-only large language models (LLMs) as judges reveals even better alignment with human preferences than the LVLM judges. Moreover, with CODA-LM, we build CODA-VLM, a new driving LVLM surpassing all the open-sourced counterparts on CODA-LM. Our CODA-VLM performs comparably with GPT-4V, even surpassing GPT-4V by +21.42% on the regional perception task. We hope CODA-LM can become the catalyst to promote interpretable self-driving empowered by LVLMs.
6/28/2024