Multi-Level Attention Aggregation for Language-Agnostic Speaker Replication
2403.04111
0
0
🤷
Abstract
This paper explores the task of language-agnostic speaker replication, a novel endeavor that seeks to replicate a speaker's voice irrespective of the language they are speaking. Towards this end, we introduce a multi-level attention aggregation approach that systematically probes and amplifies various speaker-specific attributes in a hierarchical manner. Through rigorous evaluations across a wide range of scenarios including seen and unseen speakers conversing in seen and unseen lingua, we establish that our proposed model is able to achieve substantial speaker similarity, and is able to generalize to out-of-domain (OOD) cases.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores a novel task called "language-agnostic speaker replication," which aims to replicate a speaker's voice regardless of the language they are speaking.
- The researchers introduce a multi-level attention aggregation approach that systematically analyzes and amplifies various speaker-specific attributes in a hierarchical manner.
- The proposed model is evaluated across a wide range of scenarios, including seen and unseen speakers conversing in seen and unseen languages, and it is able to achieve substantial speaker similarity and generalize to out-of-domain cases.
Plain English Explanation
The paper focuses on a new challenge in voice technology called "language-agnostic speaker replication." The goal is to be able to recreate a person's voice, no matter what language they are speaking. To do this, the researchers developed a multi-level approach that looks at different aspects of a speaker's voice and combines them in a strategic way.
The key idea is to identify and amplify the unique characteristics of a speaker's voice, even if they're speaking a language the system hasn't encountered before. This could be useful for applications like universal spoken language understanding or augmented audio generation.
The researchers tested their approach across a wide range of scenarios, including speakers and languages the system had seen before, as well as completely new ones. The results show that the model can effectively replicate a speaker's voice, even when faced with unfamiliar languages. This suggests the approach has the potential to generalize well and be applied in diverse real-world settings.
Technical Explanation
The paper introduces a novel multi-level attention aggregation approach for the task of language-agnostic speaker replication. The key idea is to systematically probe and amplify various speaker-specific attributes in a hierarchical manner, enabling the model to capture both low-level acoustic features and higher-level speaker characteristics.
The proposed architecture consists of multiple attention-based modules that operate at different levels of granularity. These modules analyze various aspects of the input speech, such as spectro-temporal patterns, phoneme-level features, and speaker-specific embeddings. The outputs of these modules are then combined through a multi-level attention mechanism to generate the final speaker-replicated output.
The model is evaluated on a wide range of test cases, including seen and unseen speakers conversing in seen and unseen languages. The results demonstrate the model's ability to achieve substantial speaker similarity and its capacity to generalize to out-of-domain scenarios, suggesting its potential for practical applications.
Critical Analysis
The paper presents a novel and promising approach to the task of language-agnostic speaker replication. The multi-level attention aggregation method appears to be an effective way to capture and preserve the unique characteristics of a speaker's voice, even when the underlying language changes.
One potential limitation of the research is the lack of a detailed analysis of the individual attention modules and their contributions to the overall performance. It would be interesting to understand the relative importance of the different levels of feature extraction and how they interact to achieve the final result.
Additionally, the paper does not discuss the potential challenges or limitations of the approach in real-world scenarios, such as noisy environments, accented speech, or speaker variability. Further research may be needed to explore the robustness and practical applicability of the proposed system.
Another area for further exploration could be the integration of the language-agnostic speaker replication model with other related tasks, such as universal spoken language understanding or cost-effective attention reuse, to unlock synergies and expand the potential applications of the technology.
Conclusion
This paper presents a novel approach to the task of language-agnostic speaker replication, which aims to replicate a speaker's voice regardless of the language they are speaking. The researchers introduce a multi-level attention aggregation method that systematically analyzes and amplifies various speaker-specific attributes in a hierarchical manner.
The proposed model is shown to be capable of achieving substantial speaker similarity and generalizing to out-of-domain scenarios, suggesting its potential for practical applications in areas such as universal spoken language understanding and augmented audio generation. Further research may be needed to address potential limitations and explore synergies with related tasks to unlock the full potential of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
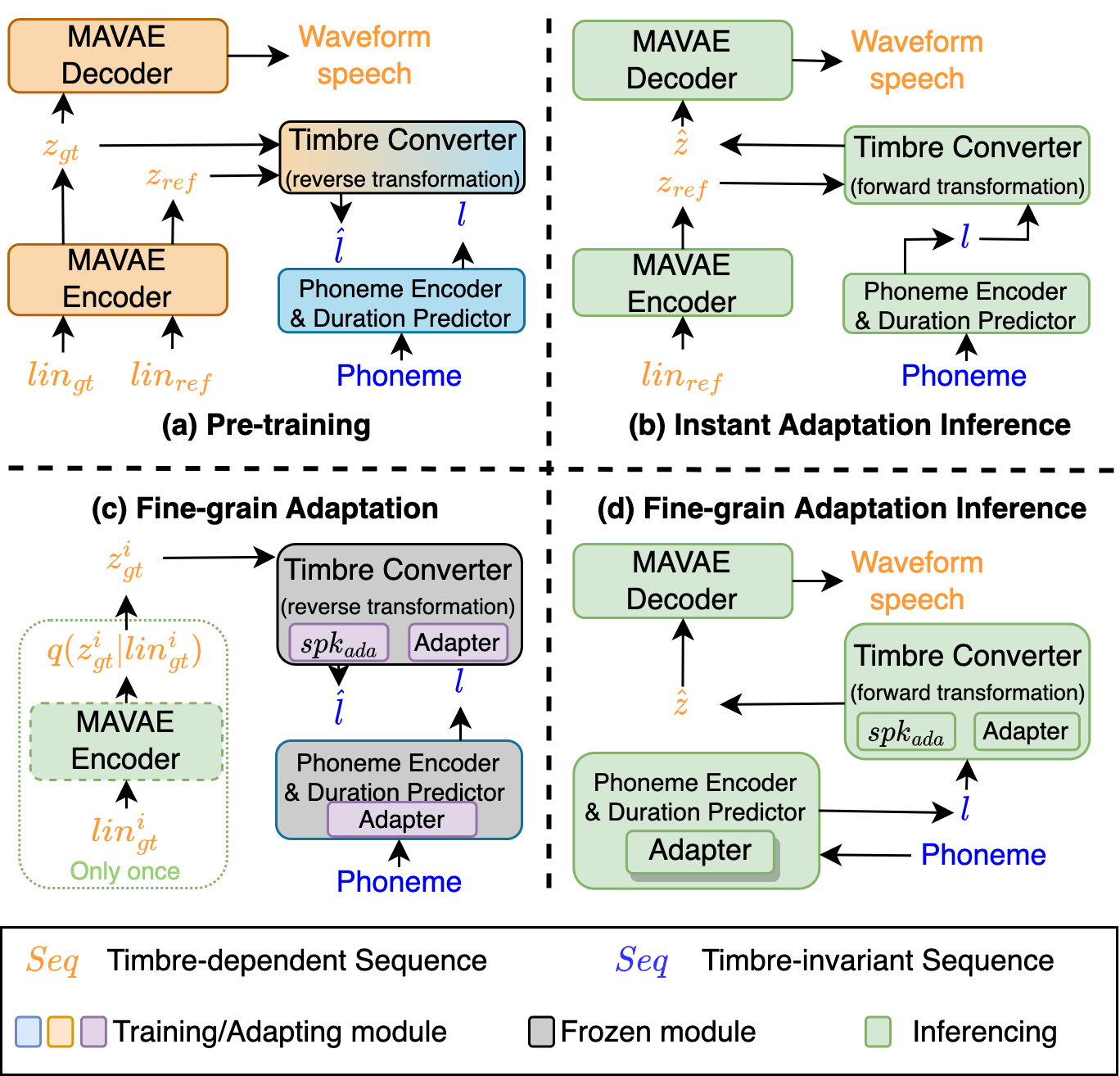
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024
🗣️
SSHR: Leveraging Self-supervised Hierarchical Representations for Multilingual Automatic Speech Recognition
Hongfei Xue, Qijie Shao, Kaixun Huang, Peikun Chen, Jie Liu, Lei Xie
0
0
Multilingual automatic speech recognition (ASR) systems have garnered attention for their potential to extend language coverage globally. While self-supervised learning (SSL) models, like MMS, have demonstrated their effectiveness in multilingual ASR, it is worth noting that various layers' representations potentially contain distinct information that has not been fully leveraged. In this study, we propose a novel method that leverages self-supervised hierarchical representations (SSHR) to fine-tune the MMS model. We first analyze the different layers of MMS and show that the middle layers capture language-related information, and the high layers encode content-related information, which gradually decreases in the final layers. Then, we extract a language-related frame from correlated middle layers and guide specific language extraction through self-attention mechanisms. Additionally, we steer the model toward acquiring more content-related information in the final layers using our proposed Cross-CTC. We evaluate SSHR on two multilingual datasets, Common Voice and ML-SUPERB, and the experimental results demonstrate that our method achieves state-of-the-art performance.
4/30/2024

Speaker Characterization by means of Attention Pooling
Federico Costa, Miquel India, Javier Hernando
0
0
State-of-the-art Deep Learning systems for speaker verification are commonly based on speaker embedding extractors. These architectures are usually composed of a feature extractor front-end together with a pooling layer to encode variable-length utterances into fixed-length speaker vectors. The authors have recently proposed the use of a Double Multi-Head Self-Attention pooling for speaker recognition, placed between a CNN-based front-end and a set of fully connected layers. This has shown to be an excellent approach to efficiently select the most relevant features captured by the front-end from the speech signal. In this paper we show excellent experimental results by adapting this architecture to other different speaker characterization tasks, such as emotion recognition, sex classification and COVID-19 detection.
5/8/2024
The THU-HCSI Multi-Speaker Multi-Lingual Few-Shot Voice Cloning System for LIMMITS'24 Challenge
Yixuan Zhou, Shuoyi Zhou, Shun Lei, Zhiyong Wu, Menglin Wu
0
0
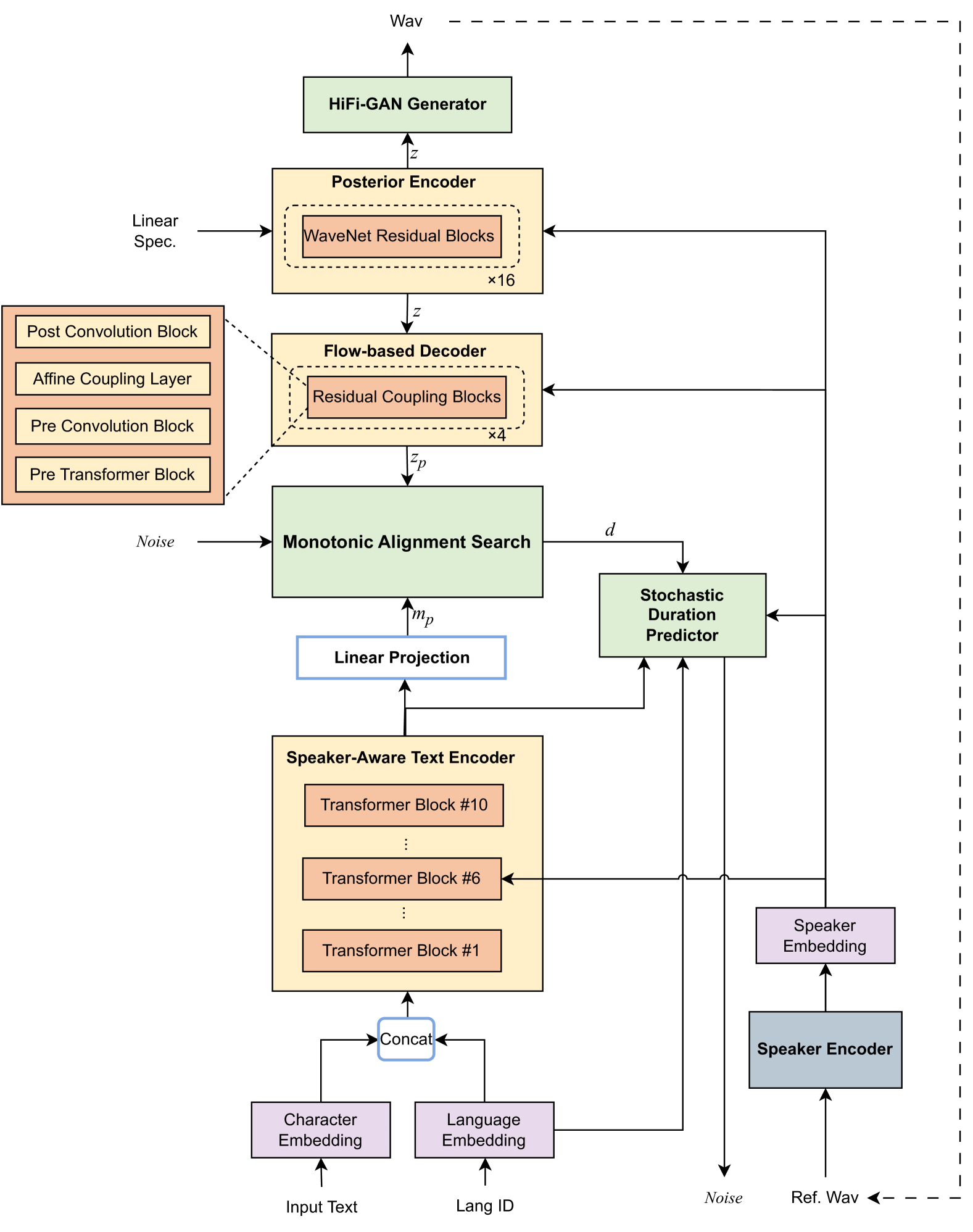
This paper presents the multi-speaker multi-lingual few-shot voice cloning system developed by THU-HCSI team for LIMMITS'24 Challenge. To achieve high speaker similarity and naturalness in both mono-lingual and cross-lingual scenarios, we build the system upon YourTTS and add several enhancements. For further improving speaker similarity and speech quality, we introduce speaker-aware text encoder and flow-based decoder with Transformer blocks. In addition, we denoise the few-shot data, mix up them with pre-training data, and adopt a speaker-balanced sampling strategy to guarantee effective fine-tuning for target speakers. The official evaluations in track 1 show that our system achieves the best speaker similarity MOS of 4.25 and obtains considerable naturalness MOS of 3.97.
4/26/2024