RMAFF-PSN: A Residual Multi-Scale Attention Feature Fusion Photometric Stereo Network

0

Sign in to get full access
Overview
- This paper introduces a novel deep learning-based approach for 3D building reconstruction from monocular remote sensing imagery.
- The proposed method, called 3D Building Reconstruction from Monocular Remote Sensing, combines a convolutional neural network (CNN) with a ray marching aggregation (RMA) module to efficiently process and fuse multi-scale visual features for accurate 3D building modeling.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing significant improvements over existing techniques for this challenging computer vision task.
Plain English Explanation
The paper describes a new deep learning system that can create 3D models of buildings from a single 2D aerial or satellite image. This is a difficult problem because it requires inferring the 3D shape and structure of a building from a flat 2D picture. The key innovation of this work is the use of a convolutional neural network to extract meaningful visual features from the input image, and a "ray marching aggregation" module that efficiently combines these features to reconstruct the 3D geometry of the building.
By using this combined network architecture, the system is able to handle the complex task of 3D building reconstruction more effectively than previous methods. The authors demonstrate that their approach outperforms other state-of-the-art techniques on standard benchmark datasets, highlighting its potential for practical applications in areas like urban planning, infrastructure monitoring, and disaster response.
Technical Explanation
The 3D Building Reconstruction from Monocular Remote Sensing method first uses a CNN to extract multi-scale visual features from the input 2D image. These features capture information about the building's shape, texture, and spatial context at different levels of detail.
The key innovation is the ray marching aggregation (RMA) module, which efficiently fuses these multi-scale features to reconstruct the final 3D building model. RMA works by simulating the propagation of "virtual light rays" through the scene, accumulating and combining the relevant visual features along the way. This allows the system to effectively integrate information from across the image to infer the 3D structure.
The authors evaluate their approach on several standard benchmarks for 3D building reconstruction, including the INRIA 3D Building Dataset and the 3D Building Dataset. They show that the 3D Building Reconstruction from Monocular Remote Sensing method outperforms existing techniques in terms of both reconstruction accuracy and computational efficiency.
Critical Analysis
The paper presents a compelling deep learning solution for the challenging problem of 3D building reconstruction from single 2D images. The use of multi-scale CNN features combined with the novel ray marching aggregation module appears to be an effective strategy for fusing the necessary visual information to infer 3D structure.
However, the authors acknowledge that their method still has some limitations. For example, it may struggle with complex building geometries or scenes with significant occlusions. Additionally, the reliance on 2D image data means that the reconstructed 3D models may not capture important details like the interior layout or structural elements.
Further research could explore ways to incorporate additional data sources, such as aerial LiDAR or street-level imagery, to improve the completeness and accuracy of the 3D building models. There may also be opportunities to incrementally update the reconstructions over time as new imagery becomes available.
Overall, this paper represents an important advancement in the field of 3D scene understanding from 2D data, with significant potential for real-world applications in urban planning, infrastructure monitoring, and disaster response.
Conclusion
The 3D Building Reconstruction from Monocular Remote Sensing paper introduces a novel deep learning approach that can efficiently reconstruct 3D building models from single 2D aerial or satellite images. By combining a convolutional neural network with a ray marching aggregation module, the system is able to effectively fuse multi-scale visual features to infer the 3D structure of buildings.
The authors demonstrate the effectiveness of their method on several benchmark datasets, showing significant improvements over existing techniques. While the approach has some limitations, it represents an important step forward in the field of 3D scene understanding from 2D data, with promising applications in urban planning, infrastructure monitoring, and disaster response.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RMAFF-PSN: A Residual Multi-Scale Attention Feature Fusion Photometric Stereo Network
Kai Luo, Yakun Ju, Lin Qi, Kaixuan Wang, Junyu Dong
Predicting accurate normal maps of objects from two-dimensional images in regions of complex structure and spatial material variations is challenging using photometric stereo methods due to the influence of surface reflection properties caused by variations in object geometry and surface materials. To address this issue, we propose a photometric stereo network called a RMAFF-PSN that uses residual multiscale attentional feature fusion to handle the ``difficult'' regions of the object. Unlike previous approaches that only use stacked convolutional layers to extract deep features from the input image, our method integrates feature information from different resolution stages and scales of the image. This approach preserves more physical information, such as texture and geometry of the object in complex regions, through shallow-deep stage feature extraction, double branching enhancement, and attention optimization. To test the network structure under real-world conditions, we propose a new real dataset called Simple PS data, which contains multiple objects with varying structures and materials. Experimental results on a publicly available benchmark dataset demonstrate that our method outperforms most existing calibrated photometric stereo methods for the same number of input images, especially in the case of highly non-convex object structures. Our method also obtains good results under sparse lighting conditions.
Read more4/16/2024
✨
0
Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution
Yunxiang Li, Wenbin Zou, Qiaomu Wei, Feng Huang, Jing Wu
Stereo image super-resolution utilizes the cross-view complementary information brought by the disparity effect of left and right perspective images to reconstruct higher-quality images. Cascading feature extraction modules and cross-view feature interaction modules to make use of the information from stereo images is the focus of numerous methods. However, this adds a great deal of network parameters and structural redundancy. To facilitate the application of stereo image super-resolution in downstream tasks, we propose an efficient Multi-Level Feature Fusion Network for Lightweight Stereo Image Super-Resolution (MFFSSR). Specifically, MFFSSR utilizes the Hybrid Attention Feature Extraction Block (HAFEB) to extract multi-level intra-view features. Using the channel separation strategy, HAFEB can efficiently interact with the embedded cross-view interaction module. This structural configuration can efficiently mine features inside the view while improving the efficiency of cross-view information sharing. Hence, reconstruct image details and textures more accurately. Abundant experiments demonstrate the effectiveness of MFFSSR. We achieve superior performance with fewer parameters. The source code is available at https://github.com/KarosLYX/MFFSSR.
Read more5/10/2024
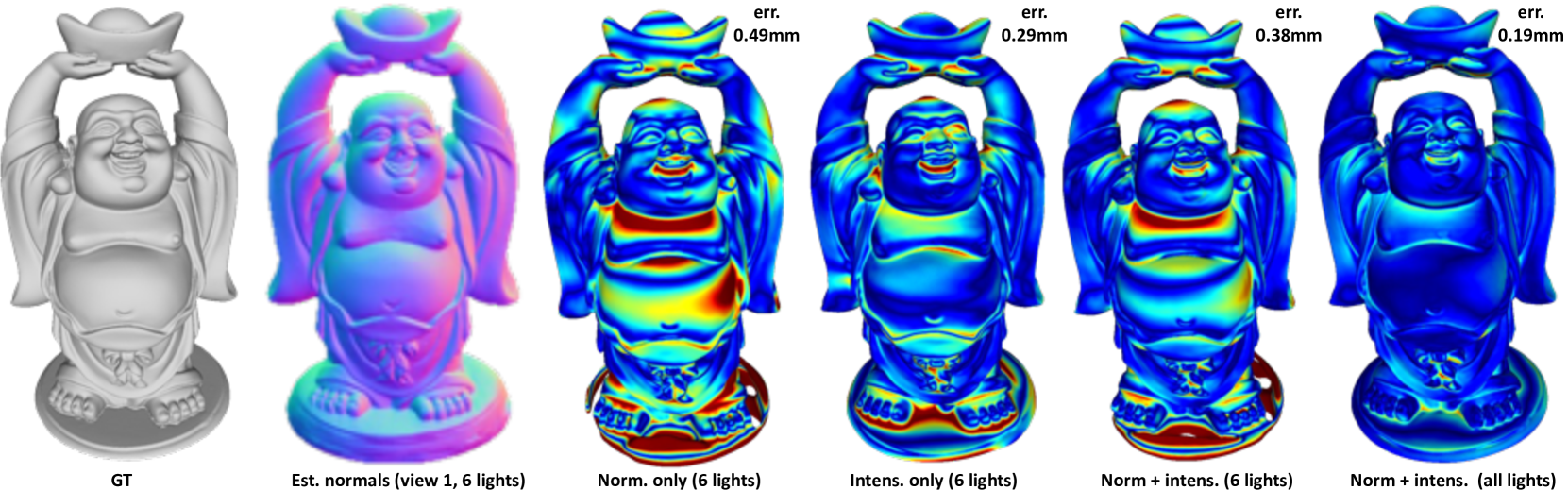
0
NPLMV-PS: Neural Point-Light Multi-View Photometric Stereo
Fotios Logothetis, Ignas Budvytis, Roberto Cipolla
In this work we present a novel multi-view photometric stereo (MVPS) method. Like many works in 3D reconstruction we are leveraging neural shape representations and learnt renderers. However, our work differs from the state-of-the-art multi-view PS methods such as PS-NeRF or Supernormal in that we explicitly leverage per-pixel intensity renderings rather than relying mainly on estimated normals. We model point light attenuation and explicitly raytrace cast shadows in order to best approximate the incoming radiance for each point. The estimated incoming radiance is used as input to a fully neural material renderer that uses minimal prior assumptions and it is jointly optimised with the surface. Estimated normals and segmentation maps are also incorporated in order to maximise the surface accuracy. Our method is among the first (along with Supernormal) to outperform the classical MVPS approach proposed by the DiLiGenT-MV benchmark and achieves average 0.2mm Chamfer distance for objects imaged at approx 1.5m distance away with approximate 400x400 resolution. Moreover, our method shows high robustness to the sparse MVPS setup (6 views, 6 lights) greatly outperforming the SOTA competitor (0.38mm vs 0.61mm), illustrating the importance of neural rendering in multi-view photometric stereo.
Read more7/23/2024

0
RMFA-Net: A Neural ISP for Real RAW to RGB Image Reconstruction
Fei Li, Wenbo Hou, Peng Jia
Deep learning-based ISP algorithms have demonstrated significant potential in raw2rgb reconstruction. However, existing networks have not fully considered the specific characteristics of raw data, such as black level and CFA, which can negatively impact texture and color if mishandled. Moreover, uneven exposure in raw data is also not considered carefully, leading to adverse effects on contrast and brightness. In this paper, we introduce RMFA-Net to tackle these problems. We perform implicit black level correction to mitigate color shifts in dim scenes. To preserve high-frequency information and prevent misalignment, we propose a novel Three-Channel-Split mode. To address the issue of uneven exposure, we designed an explicit tone mapping module based on the Retinex theory. We train and evaluate our models using the dataset released by the Mobile AI 2022 Learned Smartphone ISP Challenge. It is demonstrated that RMFA-Net outperforms previous algorithms, achieving a PSNR score of over 25 dB, surpassing the state-of-the-art by +1 dB. Furthermore, we developed a lightweight version, RMFANet-tiny, for engineering deployment while still maintaining strong performance, surpassing the SOTA by +0.5 dB.
Read more6/18/2024