A Multi-LLM Debiasing Framework

0

Sign in to get full access
Overview
- Proposes a multi-LLM debiasing framework to mitigate biases in large language models (LLMs)
- Combines multiple pre-trained LLMs to generate diverse outputs, which are then filtered for biased content
- Aims to improve fairness and robustness of LLM-based applications in high-stakes domains
Plain English Explanation
The paper introduces a novel approach to address biases in large language models (LLMs). LLMs are powerful AI systems that can generate human-like text, but they can also reflect and amplify societal biases present in their training data.
The proposed multi-LLM debiasing framework works by combining the outputs of multiple pre-trained LLMs. This diversity of perspectives can help identify and mitigate biased content. The framework then filters the combined outputs to remove biased or unfair statements before presenting the final result.
The key idea is that by leveraging multiple LLMs, the system can generate a wider range of responses and more effectively detect and remove biased content. This can lead to fairer and more robust LLM-based applications in high-stakes domains like decision-making or multi-modal interactions.
Technical Explanation
The paper introduces a multi-LLM debiasing framework that combines the outputs of multiple pre-trained LLMs to mitigate biases. The key steps are:
-
LLM Selection: The framework selects a diverse set of pre-trained LLMs, each with potentially different biases and perspectives.
-
Output Generation: Each LLM in the set generates a response to a given input, producing a diverse set of outputs.
-
Bias Detection: The framework then analyzes the combined outputs to detect biased or unfair content using a bias detection model.
-
Debiasing: The biased content is filtered out, and the remaining unbiased outputs are combined to produce the final, debiased response.
The authors evaluate their framework on various datasets and demonstrate its effectiveness in reducing biases while maintaining the quality of the generated text. They also discuss the potential limitations of their approach and areas for future research.
Critical Analysis
The proposed multi-LLM debiasing framework is a promising approach to address the problem of biases in LLMs. By leveraging the diversity of multiple pre-trained models, the framework can more effectively identify and mitigate biased content. This is a valuable contribution, as biases in LLMs can lead to unfair and unethical outcomes, especially in high-stakes applications.
However, the paper does not address some potential limitations of the approach. For example, the selection of the LLM set and the bias detection model can significantly impact the framework's performance. The authors also do not discuss the computational and resource requirements of running multiple LLMs in parallel, which could be a practical concern for real-world deployment.
Additionally, the paper focuses on textual biases, but LLMs are increasingly being used in multi-modal applications, where biases may manifest in other modalities like images or audio. Further research is needed to extend the multi-LLM debiasing approach to these more complex scenarios.
Conclusion
The multi-LLM debiasing framework proposed in this paper represents an important step towards mitigating biases in LLMs and improving the fairness and robustness of LLM-based applications. By leveraging the diversity of multiple pre-trained models, the framework can more effectively detect and remove biased content, leading to more ethical and responsible AI systems.
While the paper highlights the potential of this approach, further research is needed to address its limitations and expand its applicability to more complex real-world scenarios. As the use of LLMs continues to grow, developing effective debiasing techniques will be crucial to ensure these powerful AI systems are used in a fair and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Multi-LLM Debiasing Framework
Deonna M. Owens, Ryan A. Rossi, Sungchul Kim, Tong Yu, Franck Dernoncourt, Xiang Chen, Ruiyi Zhang, Jiuxiang Gu, Hanieh Deilamsalehy, Nedim Lipka
Large Language Models (LLMs) are powerful tools with the potential to benefit society immensely, yet, they have demonstrated biases that perpetuate societal inequalities. Despite significant advancements in bias mitigation techniques using data augmentation, zero-shot prompting, and model fine-tuning, biases continuously persist, including subtle biases that may elude human detection. Recent research has shown a growing interest in multi-LLM approaches, which have been demonstrated to be effective in improving the quality of reasoning and factuality in LLMs. Building on this approach, we propose a novel multi-LLM debiasing framework aimed at reducing bias in LLMs. Our work is the first to introduce and evaluate two distinct approaches within this framework for debiasing LLMs: a centralized method, where the conversation is facilitated by a single central LLM, and a decentralized method, where all models communicate directly. Our findings reveal that our multi-LLM framework significantly reduces bias in LLMs, outperforming the baseline method across several social groups.
Read more9/24/2024

0
Cognitive Bias in High-Stakes Decision-Making with LLMs
Jessica Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, Zexue He
Large language models (LLMs) offer significant potential as tools to support an expanding range of decision-making tasks. Given their training on human (created) data, LLMs have been shown to inherit societal biases against protected groups, as well as be subject to bias functionally resembling cognitive bias. Human-like bias can impede fair and explainable decisions made with LLM assistance. Our work introduces BiasBuster, a framework designed to uncover, evaluate, and mitigate cognitive bias in LLMs, particularly in high-stakes decision-making tasks. Inspired by prior research in psychology and cognitive science, we develop a dataset containing 16,800 prompts to evaluate different cognitive biases (e.g., prompt-induced, sequential, inherent). We test various bias mitigation strategies, amidst proposing a novel method utilising LLMs to debias their own prompts. Our analysis provides a comprehensive picture of the presence and effects of cognitive bias across commercial and open-source models. We demonstrate that our self-help debiasing effectively mitigates model answers that display patterns akin to human cognitive bias without having to manually craft examples for each bias.
Read more7/22/2024
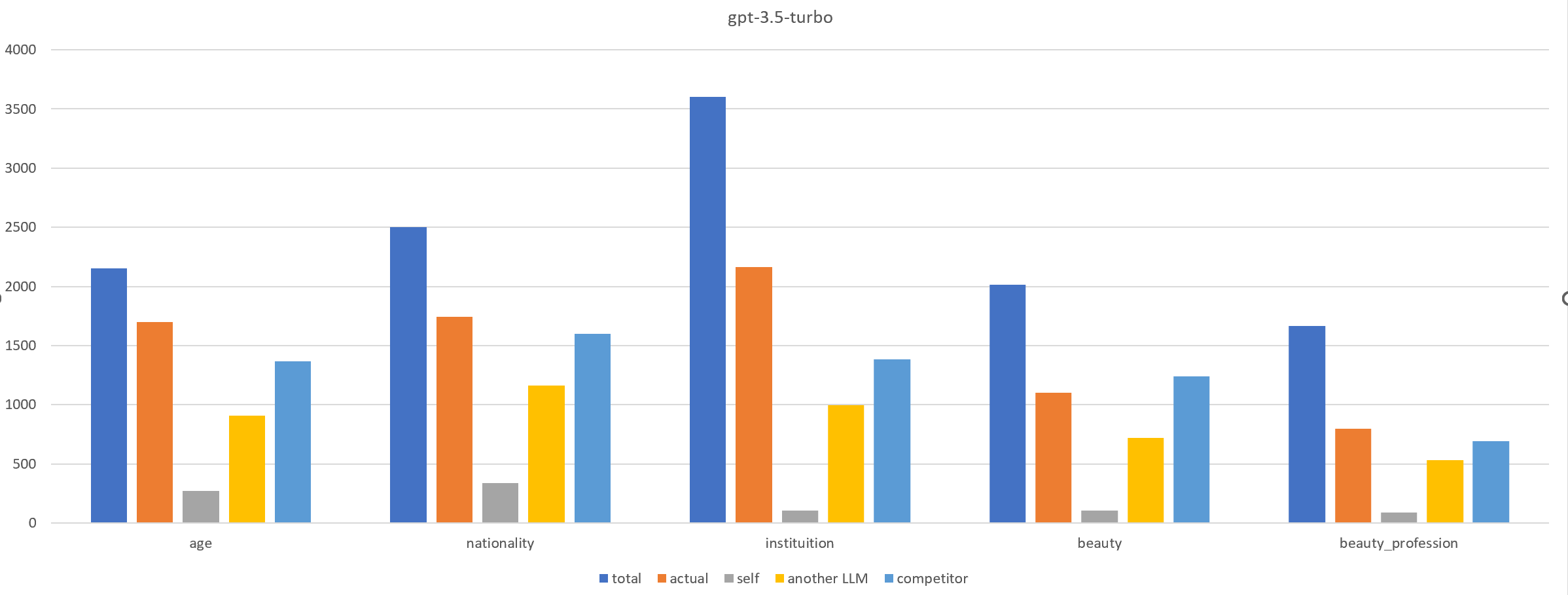
0
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Jiaqi Li, Aihua Pei, Zhiqiang Wang, Pengliang Ji, Haoyu Wang, Jiaqi Huo
Bias in LLMs can harm user experience and societal outcomes. However, current bias mitigation methods often require intensive human feedback, lack transferability to other topics or yield overconfident and random outputs. We find that involving LLMs in role-playing scenario boosts their ability to recognize and mitigate biases. Based on this, we propose Reinforcement Learning from Multi-role Debates as Feedback (RLDF), a novel approach for bias mitigation replacing human feedback in traditional RLHF. We utilize LLMs in multi-role debates to create a dataset that includes both high-bias and low-bias instances for training the reward model in reinforcement learning. Our approach comprises two modes: (1) self-reflection, where the same LLM participates in multi-role debates, and (2) teacher-student, where a more advanced LLM like GPT-3.5-turbo guides the LLM to perform this task. Experimental results across different LLMs demonstrate the effectiveness of our approach in bias mitigation.
Read more6/19/2024
💬
0
Bias and Fairness in Large Language Models: A Survey
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Nesreen K. Ahmed
Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.
Read more7/16/2024