Speech Emotion Recognition Via CNN-Transformer and Multidimensional Attention Mechanism
2403.04743
0
0

Abstract
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods.
Create account to get full access
Overview
- Presents a novel approach for speech emotion recognition using a CNN-Transformer architecture and a multidimensional attention mechanism.
- Aims to improve on existing methods by capturing both temporal and spatial features in speech data.
- Introduces a lightweight convolution Transformer and a local-global feature fusion strategy to achieve efficient and accurate emotion recognition.
Plain English Explanation
The researchers have developed a new way to recognize emotions in speech. Their approach uses a combination of convolutional neural networks (CNNs) and transformers, which are types of machine learning models. The key innovation is the use of a "multidimensional attention mechanism" that allows the model to focus on the most relevant parts of the speech data, both in terms of time (when certain sounds occur) and frequency (which pitches or tones are important).
The researchers claim this helps the model better understand the emotional content of speech, compared to previous methods. They also use a "lightweight" version of the transformer model, which is more efficient and can run on devices with limited computing power, like smartphones. Finally, the model fuses "local" features (details within the speech signal) with "global" features (overall patterns) to get a more complete understanding of the emotion.
Overall, the goal is to create a speech emotion recognition system that is accurate, efficient, and can be deployed in real-world applications, like virtual assistants or mental health monitoring apps. By understanding the emotions behind someone's voice, these systems could provide more natural and empathetic interactions.
Technical Explanation
The paper proposes a novel speech emotion recognition (SER) approach that combines a CNN-based feature extractor with a lightweight convolution Transformer and a multidimensional attention mechanism.
The architecture first uses a CNN to extract low-level features from the speech spectrogram. These features are then fed into a convolution Transformer, which captures both temporal and spatial relationships in the data through its self-attention mechanism. The key innovation is the multidimensional attention module, which allows the model to focus on the most relevant parts of the speech along both the time and frequency dimensions.
This is combined with a local-global feature fusion strategy, where the model integrates fine-grained, local features with more holistic, global features to get a comprehensive understanding of the emotional content. The authors claim this approach outperforms previous SER methods on benchmark datasets.
The use of a lightweight convolution Transformer, rather than a standard Transformer, makes the model more efficient and suitable for deployment on edge devices. The authors also demonstrate the model's robustness to adversarial attacks, an important consideration for real-world applications.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed SER system. The authors compare it against multiple baseline models on several public datasets, showing consistent improvements in accuracy. They also provide ablation studies to understand the contributions of the key components, like the multidimensional attention and local-global fusion.
However, the paper does not discuss potential limitations or caveats of the approach. For example, it is unclear how the model would perform on more diverse or challenging datasets, or how it would scale to real-world applications with noisy, unconstrained speech data. Additionally, the authors do not address potential biases or fairness issues that could arise in emotion recognition systems, which is an important consideration for real-world deployment.
Further research could explore the generalization of the method to other audio-based tasks, such as speech enhancement or multimodal emotion recognition. Investigating the model's robustness to adversarial attacks and exploring efficient eye movement recognition techniques could also be fruitful directions for future work.
Conclusion
This paper presents a novel approach to speech emotion recognition that combines a CNN feature extractor, a lightweight convolution Transformer, and a multidimensional attention mechanism. The authors demonstrate improved performance on benchmark datasets compared to previous methods, while also achieving efficiency and robustness.
The key contributions of this work are the novel architecture design, the multidimensional attention module, and the local-global feature fusion strategy. These innovations allow the model to capture both temporal and spatial relationships in speech data, leading to more accurate emotion recognition.
The potential impact of this research is the development of more natural and empathetic voice-based interfaces, such as virtual assistants or mental health monitoring apps. By understanding the emotional state of users through their speech, these systems could provide more personalized and supportive interactions.
Overall, this paper represents a significant advancement in the field of speech emotion recognition and could pave the way for more intelligent and intuitive voice-based technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Speech Emotion Recognition Using CNN and Its Use Case in Digital Healthcare
Nishargo Nigar
0
0
The process of identifying human emotion and affective states from speech is known as speech emotion recognition (SER). This is based on the observation that tone and pitch in the voice frequently convey underlying emotion. Speech recognition includes the ability to recognize emotions, which is becoming increasingly popular and in high demand. With the help of appropriate factors (such modalities, emotions, intensities, repetitions, etc.) found in the data, my research seeks to use the Convolutional Neural Network (CNN) to distinguish emotions from audio recordings and label them in accordance with the range of different emotions. I have developed a machine learning model to identify emotions from supplied audio files with the aid of machine learning methods. The evaluation is mostly focused on precision, recall, and F1 score, which are common machine learning metrics. To properly set up and train the machine learning framework, the main objective is to investigate the influence and cross-relation of all input and output parameters. To improve the ability to recognize intentions, a key condition for communication, I have evaluated emotions using my specialized machine learning algorithm via voice that would address the emotional state from voice with the help of digital healthcare, bridging the gap between human and artificial intelligence (AI).
6/18/2024

Multi-Microphone Speech Emotion Recognition using the Hierarchical Token-semantic Audio Transformer Architecture
Ohad Cohen, Gershon Hazan, Sharon Gannot
0
0
Most emotion recognition systems fail in real-life situations (in the wild scenarios) where the audio is contaminated by reverberation. Our study explores new methods to alleviate the performance degradation of Speech Emotion Recognition (SER) algorithms and develop a more robust system for adverse conditions. We propose processing multi-microphone signals to address these challenges and improve emotion classification accuracy. We adopt a state-of-the-art transformer model, the Hierarchical Token-semantic Audio Transformer (HTS-AT), to handle multi-channel audio inputs. We evaluate two strategies: averaging mel-spectrograms across channels and summing patch-embedded representations. Our multimicrophone model achieves superior performance compared to single-channel baselines when tested on real-world reverberant environments.
6/6/2024
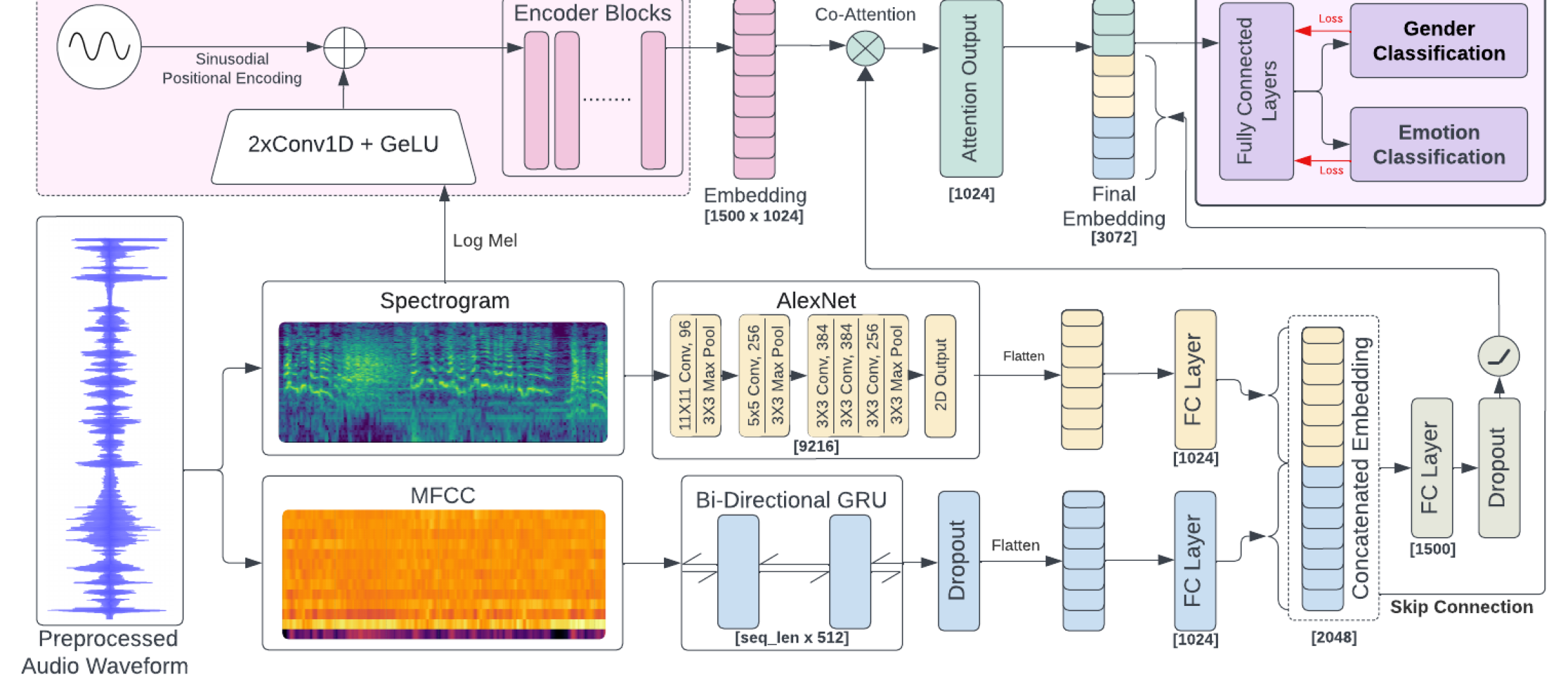
Exploring Multilingual Unseen Speaker Emotion Recognition: Leveraging Co-Attention Cues in Multitask Learning
Arnav Goel, Medha Hira, Anubha Gupta
0
0
Advent of modern deep learning techniques has given rise to advancements in the field of Speech Emotion Recognition (SER). However, most systems prevalent in the field fail to generalize to speakers not seen during training. This study focuses on handling challenges of multilingual SER, specifically on unseen speakers. We introduce CAMuLeNet, a novel architecture leveraging co-attention based fusion and multitask learning to address this problem. Additionally, we benchmark pretrained encoders of Whisper, HuBERT, Wav2Vec2.0, and WavLM using 10-fold leave-speaker-out cross-validation on five existing multilingual benchmark datasets: IEMOCAP, RAVDESS, CREMA-D, EmoDB and CaFE and, release a novel dataset for SER on the Hindi language (BhavVani). CAMuLeNet shows an average improvement of approximately 8% over all benchmarks on unseen speakers determined by our cross-validation strategy.
6/21/2024
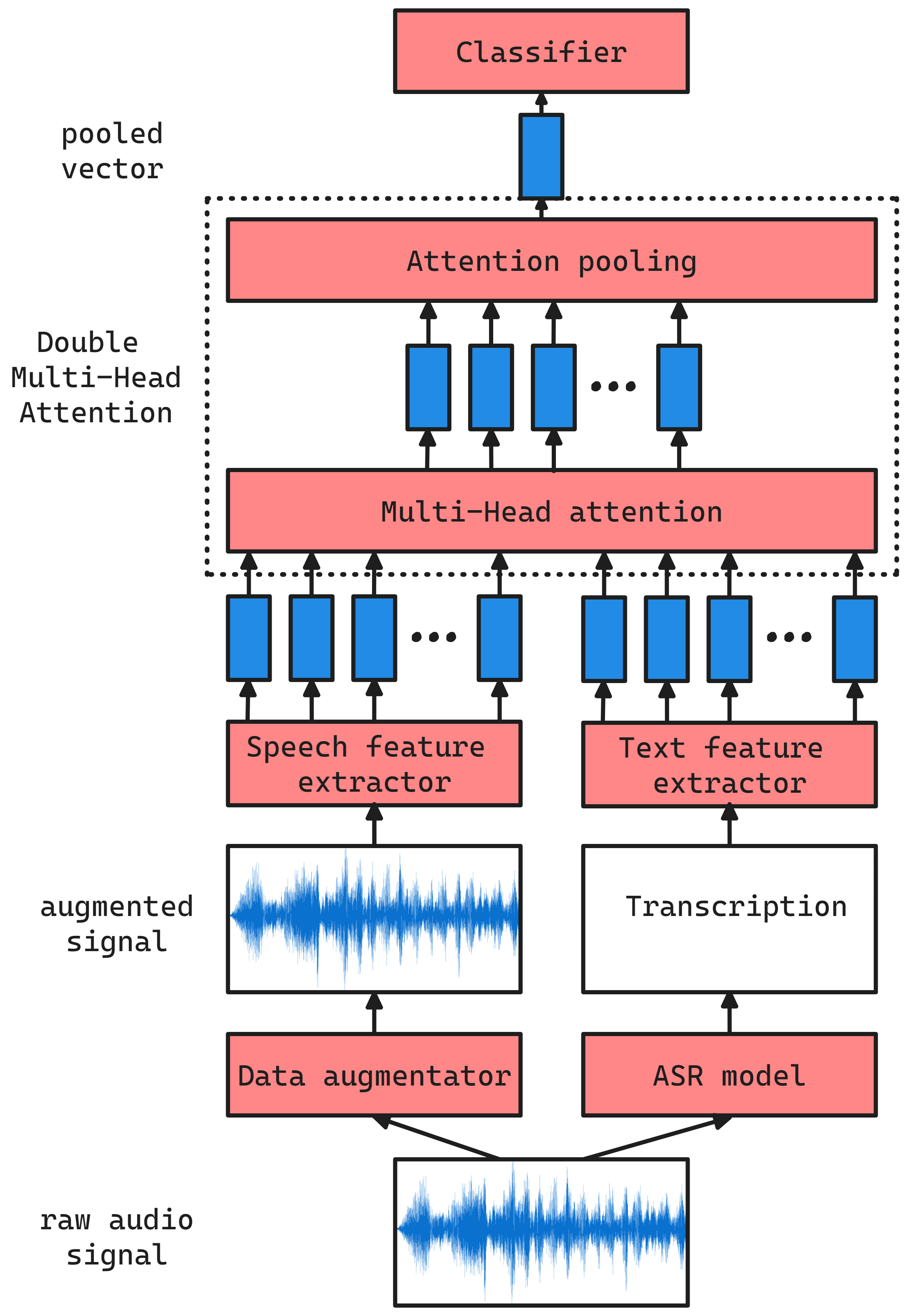
Double Multi-Head Attention Multimodal System for Odyssey 2024 Speech Emotion Recognition Challenge
Federico Costa, Miquel India, Javier Hernando
0
0
As computer-based applications are becoming more integrated into our daily lives, the importance of Speech Emotion Recognition (SER) has increased significantly. Promoting research with innovative approaches in SER, the Odyssey 2024 Speech Emotion Recognition Challenge was organized as part of the Odyssey 2024 Speaker and Language Recognition Workshop. In this paper we describe the Double Multi-Head Attention Multimodal System developed for this challenge. Pre-trained self-supervised models were used to extract informative acoustic and text features. An early fusion strategy was adopted, where a Multi-Head Attention layer transforms these mixed features into complementary contextualized representations. A second attention mechanism is then applied to pool these representations into an utterance-level vector. Our proposed system achieved the third position in the categorical task ranking with a 34.41% Macro-F1 score, where 31 teams participated in total.
6/18/2024