TRNet: Two-level Refinement Network leveraging Speech Enhancement for Noise Robust Speech Emotion Recognition
2404.12979
0
0

Abstract
One persistent challenge in Speech Emotion Recognition (SER) is the ubiquitous environmental noise, which frequently results in diminished SER performance in practical use. In this paper, we introduce a Two-level Refinement Network, dubbed TRNet, to address this challenge. Specifically, a pre-trained speech enhancement module is employed for front-end noise reduction and noise level estimation. Later, we utilize clean speech spectrograms and their corresponding deep representations as reference signals to refine the spectrogram distortion and representation shift of enhanced speech during model training. Experimental results validate that the proposed TRNet substantially increases the system's robustness in both matched and unmatched noisy environments, without compromising its performance in clean environments.
Create account to get full access
Overview
- This paper proposes a two-level refinement network called TRNet for noise-robust speech emotion recognition.
- TRNet leverages a speech enhancement module to improve the quality of input speech, which is then used by an emotion recognition module.
- The authors demonstrate that this approach outperforms existing methods for speech emotion recognition in noisy environments.
Plain English Explanation
The goal of this research is to improve the ability of computers to recognize human emotions from speech, even when the speech is recorded in noisy environments.
The key idea is to use a two-step process. First, a speech enhancement module is used to clean up the noisy speech signal. This helps remove background noise and other distortions that could make it harder to detect the emotional content of the speech.
Then, the enhanced speech is fed into an emotion recognition module, which analyzes the acoustic features of the speech to determine the underlying emotion being expressed, such as anger, happiness, sadness, etc.
By separating the speech enhancement and emotion recognition into two distinct components, the researchers were able to show that this "two-level refinement network" outperforms approaches that try to do both tasks together. The speech enhancement step helps improve the overall accuracy of the emotion recognition.
This kind of technique could be useful in applications like virtual assistants, customer service chatbots, and mental health monitoring, where accurately detecting a person's emotional state from their voice is an important capability.
Technical Explanation
The TRNet architecture consists of two main components: a speech enhancement module and an emotion recognition module.
The speech enhancement module uses a two-stage refinement network to denoise the input speech signal. This leverages techniques like BARK-scale neural networks to effectively capture the acoustic features relevant for emotion recognition.
The cleaned-up speech is then passed to the emotion recognition module, which uses a multi-blank transducer architecture to classify the emotional state expressed in the speech. This module is trained on a dataset of emotional speech samples.
The authors demonstrate that this two-level refinement approach outperforms end-to-end models that try to perform speech enhancement and emotion recognition simultaneously. The speech enhancement step appears to be crucial for improving robustness to noise.
Critical Analysis
The authors acknowledge that their evaluation was limited to certain noise conditions and that further testing on more diverse noise types would be beneficial. Additionally, the speech enhancement module could potentially be improved by incorporating more advanced techniques like speech scene graph grounding.
While the results are promising, real-world deployment of such a system would likely require further refinement and validation, especially in terms of computational efficiency and generalization to unseen environments.
Conclusion
This paper presents a novel two-level refinement network called TRNet that leverages speech enhancement to improve the accuracy of speech emotion recognition in noisy conditions. By separating the speech enhancement and emotion recognition tasks, the authors were able to demonstrate significant performance gains over end-to-end approaches.
The proposed technique has the potential to enhance the capabilities of various applications that rely on detecting human emotions from speech, such as virtual assistants, customer service, and mental health monitoring. Further research is needed to fully explore the limits and practical deployment of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
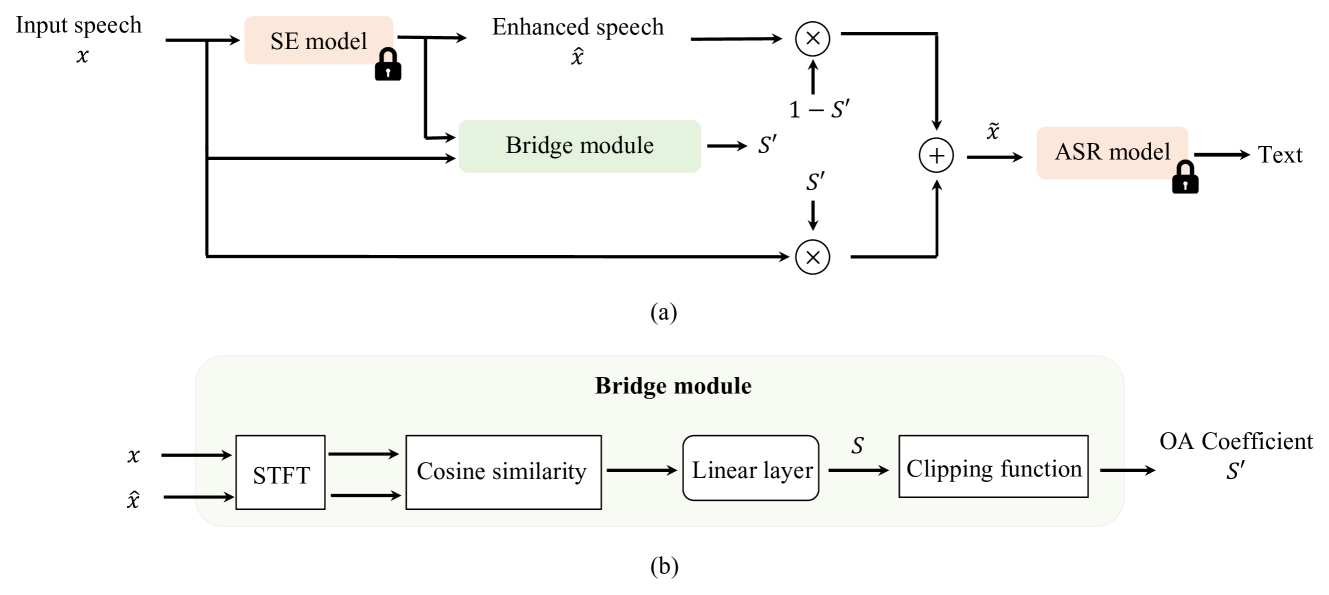
Bridging the Gap: Integrating Pre-trained Speech Enhancement and Recognition Models for Robust Speech Recognition
Kuan-Chen Wang, You-Jin Li, Wei-Lun Chen, Yu-Wen Chen, Yi-Ching Wang, Ping-Cheng Yeh, Chao Zhang, Yu Tsao
0
0
Noise robustness is critical when applying automatic speech recognition (ASR) in real-world scenarios. One solution involves the used of speech enhancement (SE) models as the front end of ASR. However, neural network-based (NN-based) SE often introduces artifacts into the enhanced signals and harms ASR performance, particularly when SE and ASR are independently trained. Therefore, this study introduces a simple yet effective SE post-processing technique to address the gap between various pre-trained SE and ASR models. A bridge module, which is a lightweight NN, is proposed to evaluate the signal-level information of the speech signal. Subsequently, using the signal-level information, the observation addition technique is applied to effectively reduce the shortcomings of SE. The experimental results demonstrate the success of our method in integrating diverse pre-trained SE and ASR models, considerably boosting the ASR robustness. Crucially, no prior knowledge of the ASR or speech contents is required during the training or inference stages. Moreover, the effectiveness of this approach extends to different datasets without necessitating the fine-tuning of the bridge module, ensuring efficiency and improved generalization.
6/19/2024

Multi-Microphone Speech Emotion Recognition using the Hierarchical Token-semantic Audio Transformer Architecture
Ohad Cohen, Gershon Hazan, Sharon Gannot
0
0
Most emotion recognition systems fail in real-life situations (in the wild scenarios) where the audio is contaminated by reverberation. Our study explores new methods to alleviate the performance degradation of Speech Emotion Recognition (SER) algorithms and develop a more robust system for adverse conditions. We propose processing multi-microphone signals to address these challenges and improve emotion classification accuracy. We adopt a state-of-the-art transformer model, the Hierarchical Token-semantic Audio Transformer (HTS-AT), to handle multi-channel audio inputs. We evaluate two strategies: averaging mel-spectrograms across channels and summing patch-embedded representations. Our multimicrophone model achieves superior performance compared to single-channel baselines when tested on real-world reverberant environments.
6/6/2024
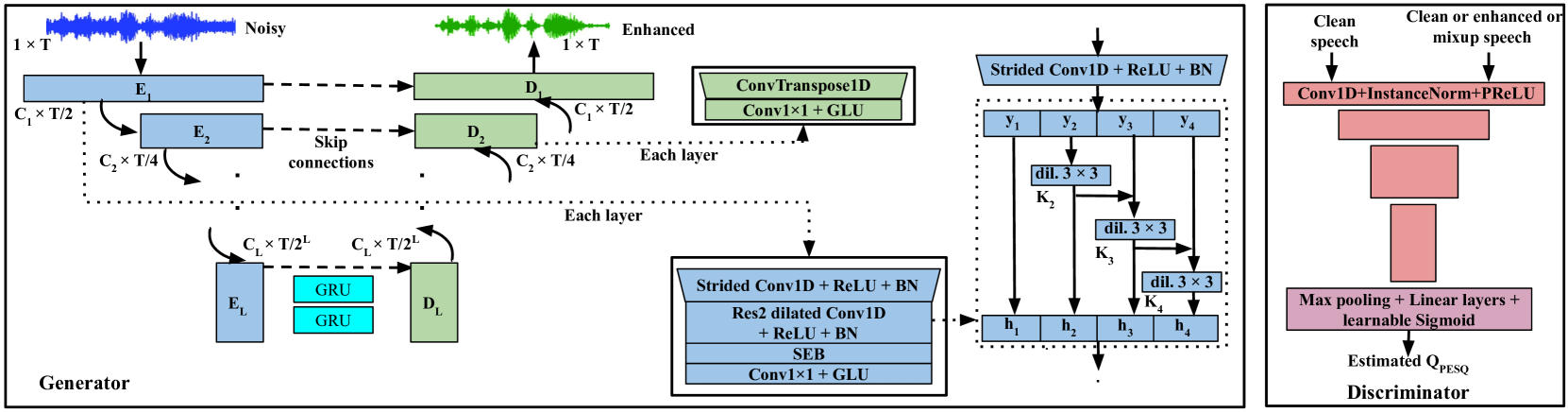
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
0
0
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
5/28/2024

Speech Emotion Recognition Via CNN-Transformer and Multidimensional Attention Mechanism
Xiaoyu Tang, Yixin Lin, Ting Dang, Yuanfang Zhang, Jintao Cheng
0
0
Speech Emotion Recognition (SER) is crucial in human-machine interactions. Mainstream approaches utilize Convolutional Neural Networks or Recurrent Neural Networks to learn local energy feature representations of speech segments from speech information, but struggle with capturing global information such as the duration of energy in speech. Some use Transformers to capture global information, but there is room for improvement in terms of parameter count and performance. Furthermore, existing attention mechanisms focus on spatial or channel dimensions, hindering learning of important temporal information in speech. In this paper, to model local and global information at different levels of granularity in speech and capture temporal, spatial and channel dependencies in speech signals, we propose a Speech Emotion Recognition network based on CNN-Transformer and multi-dimensional attention mechanisms. Specifically, a stack of CNN blocks is dedicated to capturing local information in speech from a time-frequency perspective. In addition, a time-channel-space attention mechanism is used to enhance features across three dimensions. Moreover, we model local and global dependencies of feature sequences using large convolutional kernels with depthwise separable convolutions and lightweight Transformer modules. We evaluate the proposed method on IEMOCAP and Emo-DB datasets and show our approach significantly improves the performance over the state-of-the-art methods.
6/5/2024