Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP

0
👨🏫
Sign in to get full access
Overview
- This paper proposes a novel two-stage pipeline for automatically annotating prosodic features in text-to-speech (TTS) systems.
- The first stage uses contrastive pretraining of speech-silence and word-punctuation pairs to enhance prosodic information in latent representations.
- The second stage builds a multi-modal prosody annotator with pretrained encoders, a text-speech fusion scheme, and a sequence classifier.
- Experiments on English prosodic boundaries show the method achieves state-of-the-art performance while being robust to data scarcity.
Plain English Explanation
Prosody refers to the rhythm, stress, and intonation of speech, which is crucial for making synthetic voices sound natural and expressive. However, manually adding prosodic information to text-to-speech (TTS) systems is time-consuming and inconsistent.
This paper proposes an automated two-step approach to annotate prosody. First, the system is pretrained to recognize patterns between speech/silence and words/punctuation, which helps it learn important prosodic cues. Then, the system uses multiple data sources (text and audio) and machine learning models to automatically identify prosodic boundaries in speech, such as where sentences or clauses begin and end.
The key benefit of this method is that it can generate high-quality prosodic annotations without needing as much human-labeled training data, making it more scalable and robust than previous approaches. This could enable the development of more expressive and controllable text-to-speech systems.
Technical Explanation
The proposed pipeline has two main stages:
-
Prosodic Representation Learning: The first stage uses contrastive pretraining to enhance prosodic information in the latent representations. Specifically, it trains the model to distinguish between speech/silence and word/punctuation pairs, which helps capture important prosodic cues.
-
Prosody Annotation: The second stage builds a multi-modal prosody annotator that takes both text and speech as input. It uses pretrained text and speech encoders, fuses the modalities, and applies a sequence classifier to identify prosodic boundaries at the word and phrase level.
Experiments on English data show this approach achieves state-of-the-art performance, with F1 scores of 0.72 for prosodic word boundaries and 0.93 for prosodic phrase boundaries. Notably, the system exhibits strong robustness to limited training data, which is a common challenge in prosody modeling.
Critical Analysis
The paper presents a compelling approach for automating prosodic annotation, which is a key enabler for building more expressive and controllable text-to-speech systems. The two-stage architecture with contrastive pretraining is a novel and effective way to leverage multiple data modalities and learn meaningful prosodic representations.
However, the paper does not discuss potential limitations or future research directions in depth. For example, it is unclear how well the method would generalize to other languages or speaking styles beyond read English speech. Additionally, the paper does not explore the impact of the prosodic annotations on the perceived quality and controllability of the final synthesized speech.
Further research could investigate cross-lingual prosody transfer techniques, as well as ways to more tightly integrate the prosody modeling into the overall TTS pipeline for end-to-end optimization. Incorporating user studies and subjective evaluations would also help validate the real-world benefits of this approach.
Conclusion
This paper presents a novel two-stage pipeline for automatically annotating prosodic features in text-to-speech systems. By using contrastive pretraining and multi-modal modeling, the approach can generate high-quality prosodic annotations without requiring as much human-labeled data.
The demonstrated state-of-the-art performance and robustness to data scarcity suggest this method could be a valuable tool for developing more expressive and controllable text-to-speech systems. Further research exploring cross-lingual capabilities and end-to-end integration could unlock additional benefits and expand the real-world impact of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👨🏫
0
Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP
Jinzuomu Zhong, Yang Li, Hui Huang, Korin Richmond, Jie Liu, Zhiba Su, Jing Guo, Benlai Tang, Fengjie Zhu
In expressive and controllable Text-to-Speech (TTS), explicit prosodic features significantly improve the naturalness and controllability of synthesised speech. However, manual prosody annotation is labor-intensive and inconsistent. To address this issue, a two-stage automatic annotation pipeline is novelly proposed in this paper. In the first stage, we use contrastive pretraining of Speech-Silence and Word-Punctuation (SSWP) pairs to enhance prosodic information in latent representations. In the second stage, we build a multi-modal prosody annotator, comprising pretrained encoders, a text-speech fusing scheme, and a sequence classifier. Experiments on English prosodic boundaries demonstrate that our method achieves state-of-the-art (SOTA) performance with 0.72 and 0.93 f1 score for Prosodic Word and Prosodic Phrase boundary respectively, while bearing remarkable robustness to data scarcity.
Read more6/12/2024
0
Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
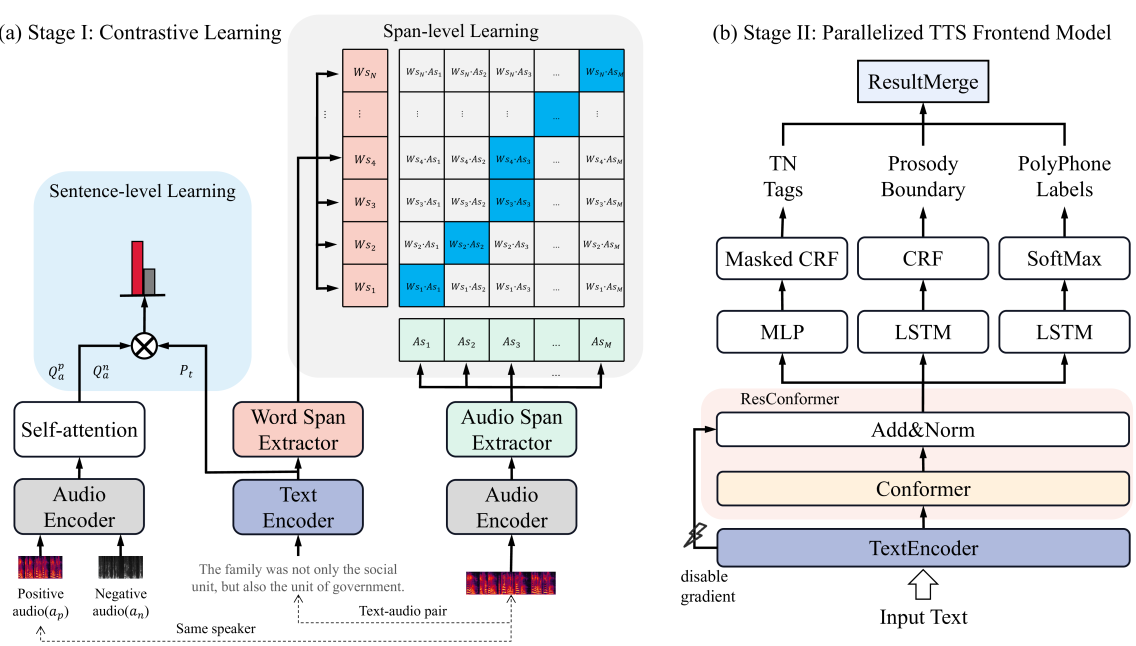
Quanxiu Wang, Hui Huang, Mingjie Wang, Yong Dai, Jinzuomu Zhong, Benlai Tang
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Read more4/16/2024
0
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
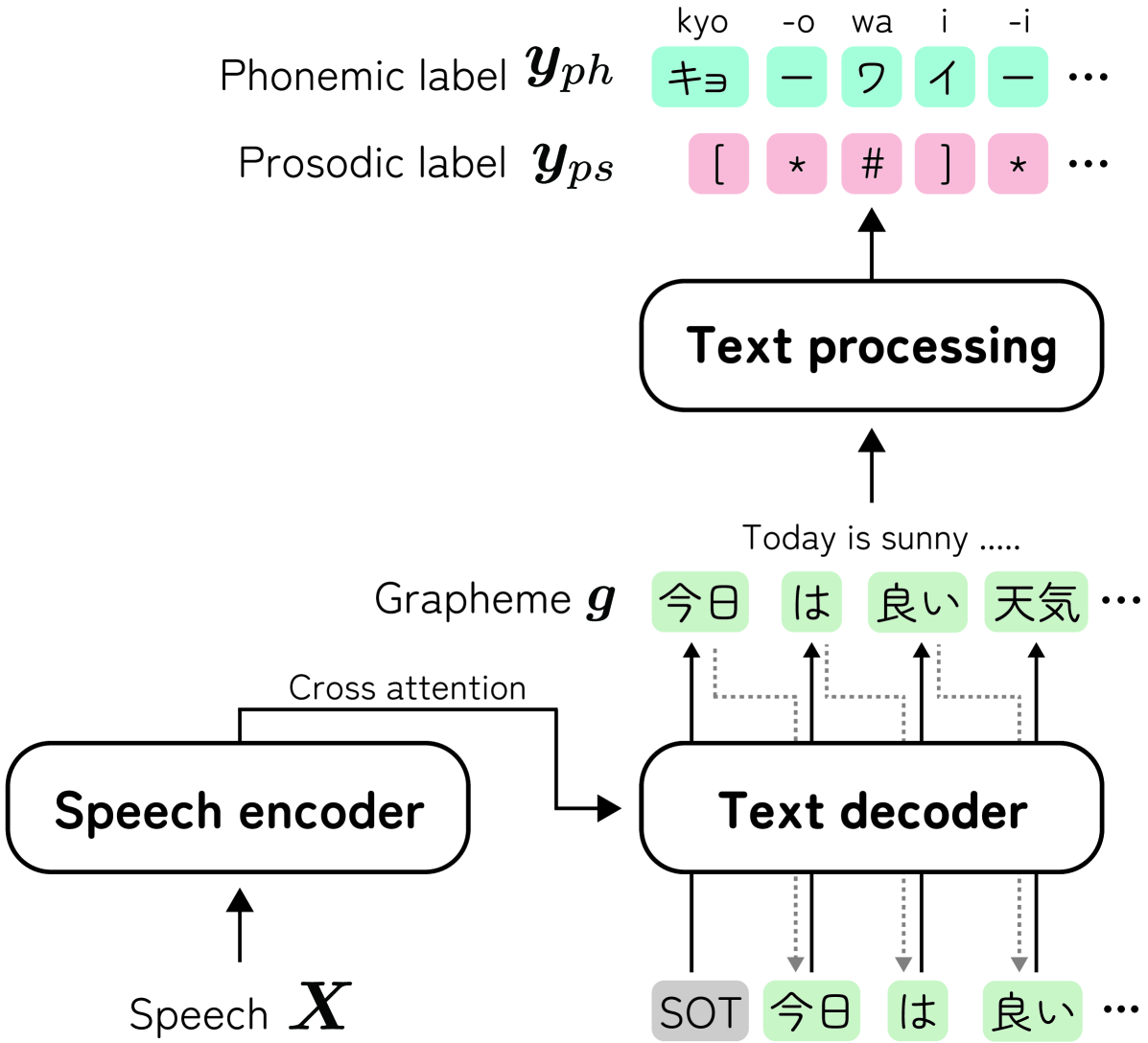
Yuma Shirahata, Byeongseon Park, Ryuichi Yamamoto, Kentaro Tachibana
This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
Read more6/13/2024

0
Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
Read more6/13/2024