Prior-agnostic Multi-scale Contrastive Text-Audio Pre-training for Parallelized TTS Frontend Modeling
2404.09192
0
0
Abstract
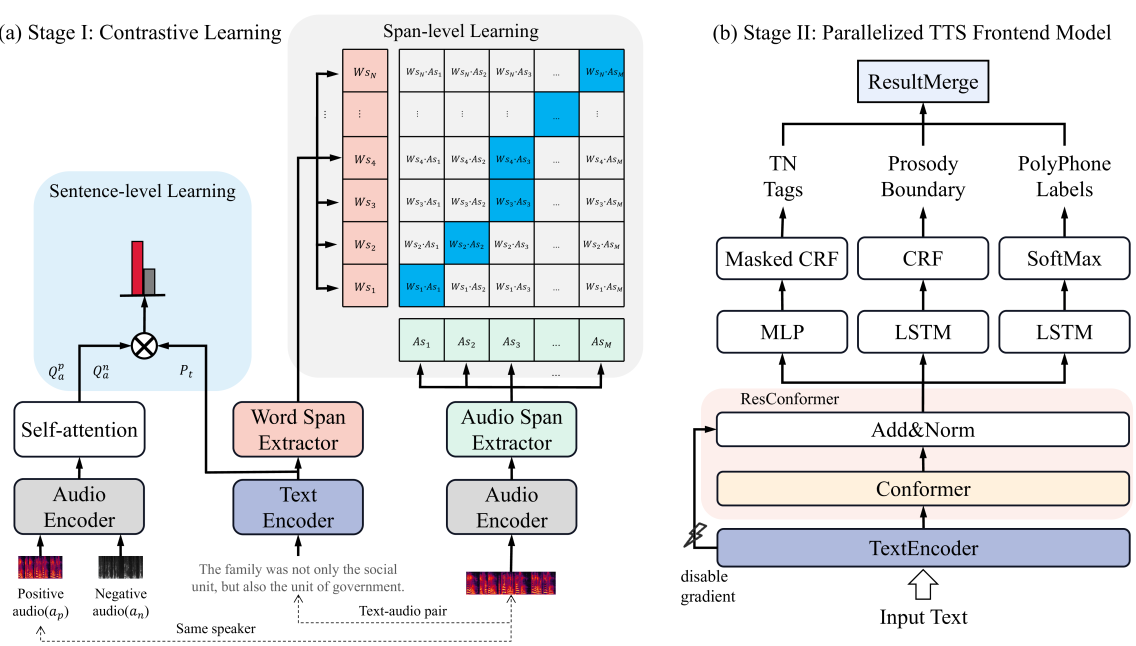
Over the past decade, a series of unflagging efforts have been dedicated to developing highly expressive and controllable text-to-speech (TTS) systems. In general, the holistic TTS comprises two interconnected components: the frontend module and the backend module. The frontend excels in capturing linguistic representations from the raw text input, while the backend module converts linguistic cues to speech. The research community has shown growing interest in the study of the frontend component, recognizing its pivotal role in text-to-speech systems, including Text Normalization (TN), Prosody Boundary Prediction (PBP), and Polyphone Disambiguation (PD). Nonetheless, the limitations posed by insufficient annotated textual data and the reliance on homogeneous text signals significantly undermine the effectiveness of its supervised learning. To evade this obstacle, a novel two-stage TTS frontend prediction pipeline, named TAP-FM, is proposed in this paper. Specifically, during the first learning phase, we present a Multi-scale Contrastive Text-audio Pre-training protocol (MC-TAP), which hammers at acquiring richer insights via multi-granularity contrastive pre-training in an unsupervised manner. Instead of mining homogeneous features in prior pre-training approaches, our framework demonstrates the ability to delve deep into both global and local text-audio semantic and acoustic representations. Furthermore, a parallelized TTS frontend model is delicately devised to execute TN, PD, and PBP prediction tasks, respectively in the second stage. Finally, extensive experiments illustrate the superiority of our proposed method, achieving state-of-the-art performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach for pre-training text-audio models using a prior-agnostic, multi-scale contrastive learning framework to enable parallelized text-to-speech (TTS) frontend modeling.
- The proposed method aims to improve the performance and efficiency of TTS systems by jointly learning contextual representations from text and audio data, without relying on specific prior knowledge or task-specific architectures.
- The authors demonstrate the effectiveness of their approach through experiments on various TTS datasets, showing improved performance compared to state-of-the-art methods.
Plain English Explanation
The paper describes a new way of training language models that can understand both text and audio data. This is important for text-to-speech (TTS) systems, which need to convert written text into spoken audio.
The key idea is to use a "contrastive" learning approach, where the model is trained to recognize relationships between text and audio data, without relying on any specific prior knowledge or task-specific architecture. This "prior-agnostic" approach allows the model to learn more general and flexible representations that can be applied to a variety of TTS scenarios.
The authors show that their method outperforms existing state-of-the-art TTS frontend modeling techniques, which often rely on complex, task-specific architectures. By using a more general and efficient approach, the new model can generate high-quality speech from text more quickly and accurately.
Technical Explanation
The paper proposes a multi-stage, multi-modal pre-training framework for TTS frontend modeling. The core of the approach is a prior-agnostic, multi-scale contrastive learning module that jointly learns contextual representations from text and audio data.
The model is trained to identify relationships between text and corresponding audio segments, using a contrastive loss function. This allows the model to learn general, transferable representations without relying on specific architectural priors or task-specific objectives.
The authors also introduce a parallelized TTS frontend modeling approach, where the text and audio representations are learned jointly and can be used in a parallelized manner for efficient TTS generation. This is in contrast to traditional "pipeline-based" TTS frontend models, which often require sequential processing and are less efficient.
The proposed CLAM-TTS model is evaluated on several TTS datasets, demonstrating improved performance compared to state-of-the-art methods, such as Tango-2 and other pipeline-based approaches.
Critical Analysis
The paper presents a compelling approach for improving the efficiency and performance of TTS frontend modeling. The key strength of the method is its prior-agnostic, multi-scale contrastive learning framework, which allows the model to learn general, transferable representations from text and audio data.
However, the paper does not address some potential limitations of the approach. For example, the authors do not discuss the computational complexity of the multi-scale contrastive learning module, which could be a concern for real-time TTS applications. Additionally, the paper does not explore the robustness of the model to noisy or diverse audio data, which is an important consideration for practical TTS systems.
Furthermore, while the authors demonstrate improved performance on standard TTS datasets, it would be valuable to see how the model performs on more challenging, real-world TTS scenarios, such as handling diverse accents, emotions, or speaking styles.
Conclusion
This paper introduces a novel prior-agnostic, multi-scale contrastive learning approach for TTS frontend modeling. By jointly learning text and audio representations, the proposed CLAM-TTS model can generate high-quality speech from text more efficiently than traditional pipeline-based methods.
The authors' key contribution is the development of a more general and flexible TTS frontend modeling approach, which has the potential to significantly improve the performance and efficiency of TTS systems. This work represents an important step towards more robust and versatile text-to-speech technologies, with broader implications for multimodal language understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Xiang Li, Zhi-Qi Cheng, Jun-Yan He, Xiaojiang Peng, Alexander G. Hauptmann
0
0
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
4/30/2024
🌀
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng, Hong Chen, Jinzheng He, Zhou Zhao
0
0
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~footnote{Audio samples are available at url{https://ViT-TTS.github.io/.}}
4/23/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024