Multi-modal Relation Distillation for Unified 3D Representation Learning

0

Sign in to get full access
Overview
- This paper proposes a multi-modal relation distillation approach for unified 3D representation learning.
- The key idea is to leverage the complementary information from different modalities, such as images and text, to enhance the learned 3D representations.
- The method distills the relational knowledge between modalities to improve the 3D object understanding and downstream tasks.
Plain English Explanation
The paper introduces a new technique called "multi-modal relation distillation" for improving how computers understand 3D objects. Computers often struggle to fully comprehend the properties and relationships of 3D objects, which is important for tasks like 3D object recognition.
The main insight is that different data sources, like images and text descriptions, can provide complementary information about 3D objects. By distilling the relational knowledge between these modalities, the method can enhance the 3D representations learned by the computer. This helps the computer better grasp the structure, properties, and interactions of 3D objects.
The technique aims to create a unified 3D representation that combines insights from multiple data sources. This can improve the computer's 3D object understanding and enable better performance on downstream tasks that rely on 3D perception, like 3D shape analysis.
Technical Explanation
The paper proposes a multi-modal relation distillation framework for unified 3D representation learning. The core idea is to leverage the complementary information from different modalities, such as images and text, to enhance the learned 3D representations.
The method consists of two key components:
-
Multi-modal Feature Extraction: The system extracts features from multiple modalities, including 2D images and text descriptions, using pre-trained models. This allows it to capture diverse information about the 3D objects.
-
Relation Distillation: The method then distills the relational knowledge between the multi-modal features. This is done by training a relation network to predict the relationships between the features from different modalities. The learned relational knowledge is used to refine the 3D representations, improving the computer's understanding of the objects.
The refined 3D representations can be used for downstream tasks such as 3D object recognition and part segmentation. Experiments on benchmark datasets demonstrate the effectiveness of the proposed approach, with significant improvements over unimodal and existing multi-modal baselines.
Critical Analysis
The paper presents a well-designed and principled approach to leveraging multi-modal information for 3D representation learning. The key strength of the method is its ability to distill the relational knowledge between modalities, which helps to capture a more comprehensive understanding of 3D objects.
One potential limitation is the reliance on pre-trained models for the initial feature extraction. While this allows the system to benefit from existing knowledge, it may also introduce biases or limit the ability to learn truly novel representations. Further research could explore end-to-end training approaches that learn the multi-modal feature extraction and relation distillation jointly.
Additionally, the paper focuses on images and text as the primary modalities. Exploring the integration of other modalities, such as point clouds or depth maps, could further enhance the 3D understanding and broaden the applicability of the approach.
Overall, the proposed multi-modal relation distillation framework is a promising direction for advancing the state-of-the-art in 3D representation learning and should inspire further research in this area.
Conclusion
This paper presents a novel multi-modal relation distillation approach for unified 3D representation learning. By distilling the relational knowledge between features extracted from different modalities, such as images and text, the method is able to enhance the learned 3D representations and improve the computer's understanding of 3D objects.
The improved 3D representations can benefit a wide range of downstream tasks, including 3D object recognition, part segmentation, and shape analysis. The promising results demonstrate the potential of leveraging multi-modal information for advancing 3D perception capabilities, which is crucial for applications in areas like robotics, augmented reality, and autonomous systems.
Future research directions may include exploring end-to-end training, integrating additional modalities, and investigating the generalization of the approach to other 3D understanding tasks. Overall, this work represents an important step towards more unified and comprehensive 3D representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-modal Relation Distillation for Unified 3D Representation Learning
Huiqun Wang, Yiping Bao, Panwang Pan, Zeming Li, Xiao Liu, Ruijie Yang, Di Huang
Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning heterogeneous features across 3D shapes and their corresponding 2D images and language descriptions. However, current straightforward solutions often overlook intricate structural relations among samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pre-training framework, which is designed to effectively distill reputable large Vision-Language Models (VLM) into 3D backbones. MRD aims to capture both intra-relations within each modality as well as cross-relations between different modalities and produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering new state-of-the-art performance.
Read more7/22/2024

0
Image-to-Lidar Relational Distillation for Autonomous Driving Data
Anas Mahmoud, Ali Harakeh, Steven Waslander
Pre-trained on extensive and diverse multi-modal datasets, 2D foundation models excel at addressing 2D tasks with little or no downstream supervision, owing to their robust representations. The emergence of 2D-to-3D distillation frameworks has extended these capabilities to 3D models. However, distilling 3D representations for autonomous driving datasets presents challenges like self-similarity, class imbalance, and point cloud sparsity, hindering the effectiveness of contrastive distillation, especially in zero-shot learning contexts. Whereas other methodologies, such as similarity-based distillation, enhance zero-shot performance, they tend to yield less discriminative representations, diminishing few-shot performance. We investigate the gap in structure between the 2D and the 3D representations that result from state-of-the-art distillation frameworks and reveal a significant mismatch between the two. Additionally, we demonstrate that the observed structural gap is negatively correlated with the efficacy of the distilled representations on zero-shot and few-shot 3D semantic segmentation. To bridge this gap, we propose a relational distillation framework enforcing intra-modal and cross-modal constraints, resulting in distilled 3D representations that closely capture the structure of the 2D representation. This alignment significantly enhances 3D representation performance over those learned through contrastive distillation in zero-shot segmentation tasks. Furthermore, our relational loss consistently improves the quality of 3D representations in both in-distribution and out-of-distribution few-shot segmentation tasks, outperforming approaches that rely on the similarity loss.
Read more9/4/2024
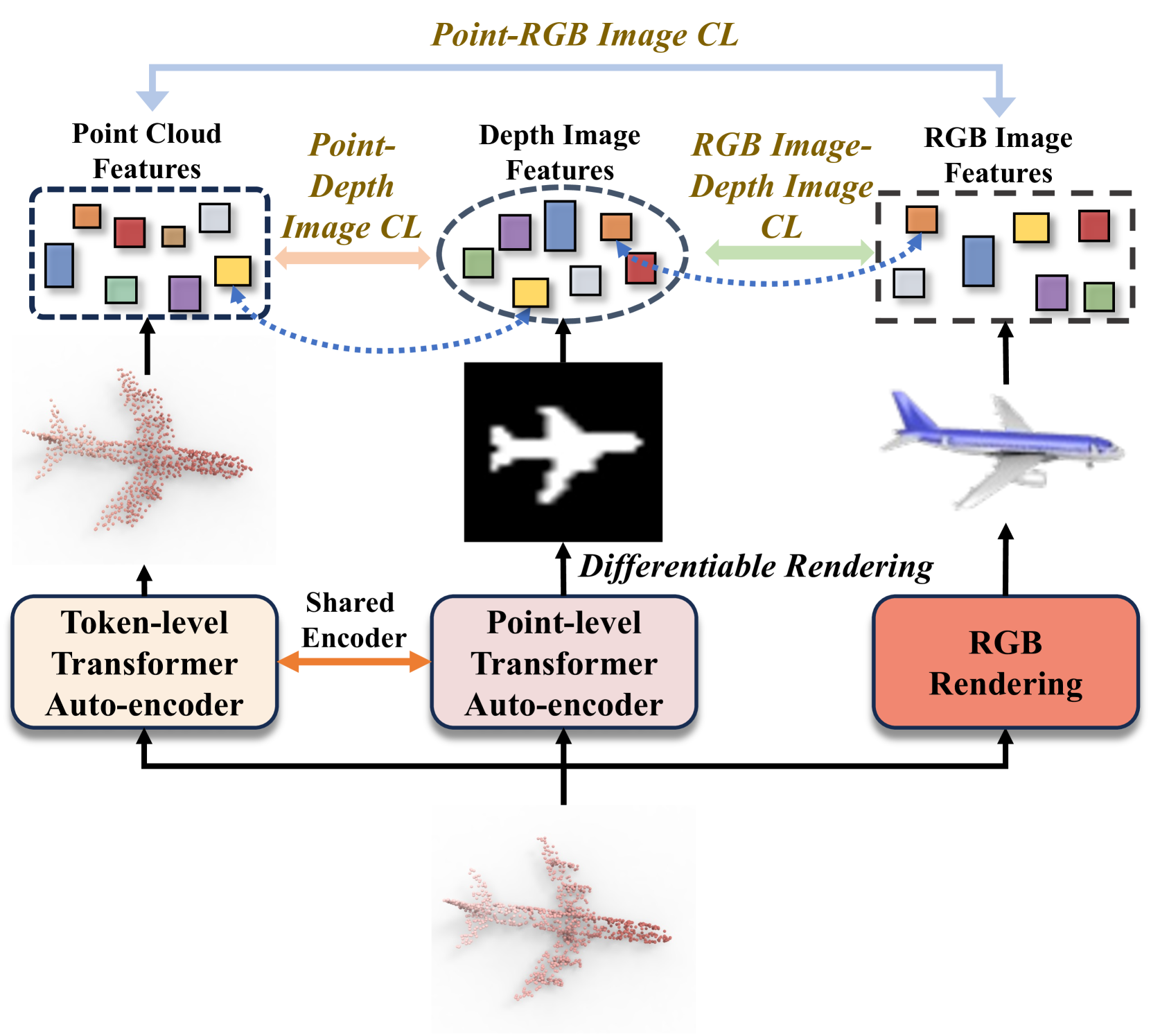
0
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
Read more4/23/2024
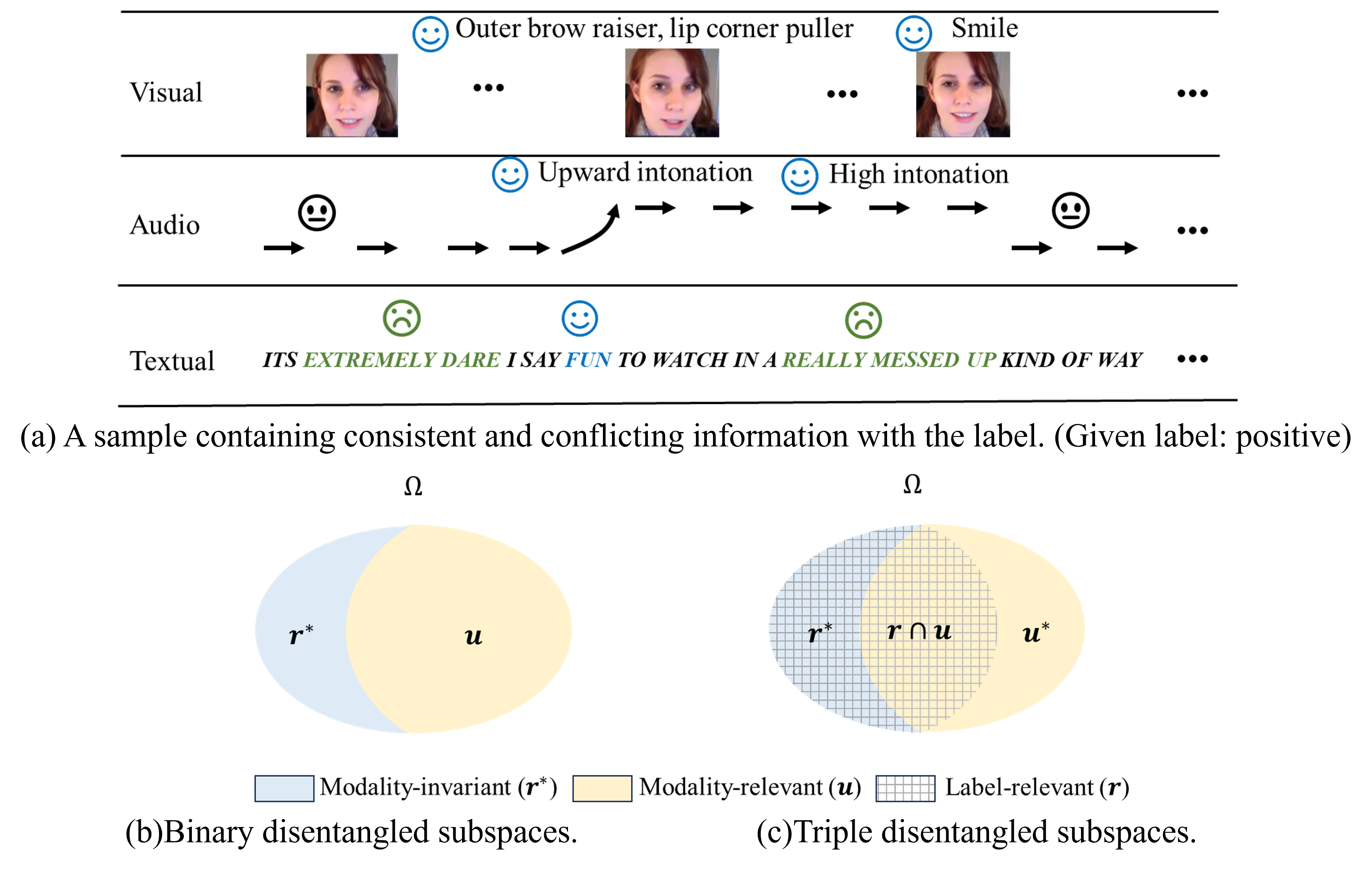
0
Triple Disentangled Representation Learning for Multimodal Affective Analysis
Ying Zhou, Xuefeng Liang, Han Chen, Yin Zhao, Xin Chen, Lida Yu
Multimodal learning has exhibited a significant advantage in affective analysis tasks owing to the comprehensive information of various modalities, particularly the complementary information. Thus, many emerging studies focus on disentangling the modality-invariant and modality-specific representations from input data and then fusing them for prediction. However, our study shows that modality-specific representations may contain information that is irrelevant or conflicting with the tasks, which downgrades the effectiveness of learned multimodal representations. We revisit the disentanglement issue, and propose a novel triple disentanglement approach, TriDiRA, which disentangles the modality-invariant, effective modality-specific and ineffective modality-specific representations from input data. By fusing only the modality-invariant and effective modality-specific representations, TriDiRA can significantly alleviate the impact of irrelevant and conflicting information across modalities during model training. Extensive experiments conducted on four benchmark datasets demonstrate the effectiveness and generalization of our triple disentanglement, which outperforms SOTA methods.
Read more4/9/2024