Image-to-Lidar Relational Distillation for Autonomous Driving Data

0

Sign in to get full access
Overview
- The paper presents a novel technique called "Image-to-Lidar Relational Distillation" for autonomous driving applications
- It aims to transfer knowledge from 2D image data to 3D lidar data, improving the performance of 3D perception tasks
- The method leverages the relationship between image and lidar data to distill useful information from one modality to the other
Plain English Explanation
Self-driving cars rely on a variety of sensors, including cameras that capture 2D images and lidar systems that create 3D point clouds. These two data sources provide complementary information that can be combined to better understand the vehicle's surroundings.
The researchers developed a technique called "Image-to-Lidar Relational Distillation" that aims to transfer useful knowledge from 2D image data to the 3D lidar data. This can help improve the performance of 3D perception tasks like object detection and scene understanding, which are critical for autonomous driving.
The key insight is that there are inherent relationships between the information captured by cameras and lidar sensors. For example, the shape and appearance of an object in the 2D image can provide cues about its 3D structure in the lidar point cloud. The proposed method learns to leverage these cross-modal relationships to distill relevant information from the image data and apply it to enrich the lidar data.
Technical Explanation
The Image-to-Lidar Relational Distillation framework consists of two main components:
-
Relational Embedding: This module learns a shared embedding space that captures the inherent relationships between image and lidar data. It takes in image and lidar features and outputs a joint relational representation.
-
Distillation Head: This component uses the learned relational embedding to distill relevant knowledge from the image features and transfer it to the lidar features. This helps enhance the lidar-based 3D perception by incorporating complementary information from the 2D image data.
The authors evaluate their method on several 3D detection and segmentation tasks using autonomous driving datasets. They demonstrate significant performance improvements compared to baseline approaches that do not leverage the cross-modal relational knowledge.
Critical Analysis
The Image-to-Lidar Relational Distillation technique provides a promising approach for enhancing 3D perception in autonomous driving by effectively combining information from 2D images and 3D lidar data. However, the authors acknowledge some limitations:
- The method relies on well-aligned image-lidar pairs, which may not always be available in real-world scenarios due to sensor calibration issues or dynamic environments.
- The distillation process assumes that the image and lidar data capture the same underlying scene, which may not always be the case, especially in complex urban environments.
- The paper focuses on improving 3D perception tasks, but does not explore the potential impact on other autonomous driving capabilities, such as localization or motion planning.
Further research could explore ways to address these limitations, such as developing more robust cross-modal alignment techniques or investigating the broader impact of the relational distillation approach on the overall autonomous driving pipeline.
Conclusion
The Image-to-Lidar Relational Distillation method presents an innovative approach for enhancing 3D perception in autonomous driving by leveraging the inherent relationships between 2D image and 3D lidar data. By effectively transferring knowledge from the image domain to the lidar domain, the technique can improve the performance of critical tasks like object detection and scene understanding, ultimately contributing to the development of safer and more reliable self-driving systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Image-to-Lidar Relational Distillation for Autonomous Driving Data
Anas Mahmoud, Ali Harakeh, Steven Waslander
Pre-trained on extensive and diverse multi-modal datasets, 2D foundation models excel at addressing 2D tasks with little or no downstream supervision, owing to their robust representations. The emergence of 2D-to-3D distillation frameworks has extended these capabilities to 3D models. However, distilling 3D representations for autonomous driving datasets presents challenges like self-similarity, class imbalance, and point cloud sparsity, hindering the effectiveness of contrastive distillation, especially in zero-shot learning contexts. Whereas other methodologies, such as similarity-based distillation, enhance zero-shot performance, they tend to yield less discriminative representations, diminishing few-shot performance. We investigate the gap in structure between the 2D and the 3D representations that result from state-of-the-art distillation frameworks and reveal a significant mismatch between the two. Additionally, we demonstrate that the observed structural gap is negatively correlated with the efficacy of the distilled representations on zero-shot and few-shot 3D semantic segmentation. To bridge this gap, we propose a relational distillation framework enforcing intra-modal and cross-modal constraints, resulting in distilled 3D representations that closely capture the structure of the 2D representation. This alignment significantly enhances 3D representation performance over those learned through contrastive distillation in zero-shot segmentation tasks. Furthermore, our relational loss consistently improves the quality of 3D representations in both in-distribution and out-of-distribution few-shot segmentation tasks, outperforming approaches that rely on the similarity loss.
Read more9/4/2024

0
Multi-modal Relation Distillation for Unified 3D Representation Learning
Huiqun Wang, Yiping Bao, Panwang Pan, Zeming Li, Xiao Liu, Ruijie Yang, Di Huang
Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning heterogeneous features across 3D shapes and their corresponding 2D images and language descriptions. However, current straightforward solutions often overlook intricate structural relations among samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pre-training framework, which is designed to effectively distill reputable large Vision-Language Models (VLM) into 3D backbones. MRD aims to capture both intra-relations within each modality as well as cross-relations between different modalities and produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering new state-of-the-art performance.
Read more7/22/2024
📈
0
PartDistill: 3D Shape Part Segmentation by Vision-Language Model Distillation
Ardian Umam, Cheng-Kun Yang, Min-Hung Chen, Jen-Hui Chuang, Yen-Yu Lin
This paper proposes a cross-modal distillation framework, PartDistill, which transfers 2D knowledge from vision-language models (VLMs) to facilitate 3D shape part segmentation. PartDistill addresses three major challenges in this task: the lack of 3D segmentation in invisible or undetected regions in the 2D projections, inconsistent 2D predictions by VLMs, and the lack of knowledge accumulation across different 3D shapes. PartDistill consists of a teacher network that uses a VLM to make 2D predictions and a student network that learns from the 2D predictions while extracting geometrical features from multiple 3D shapes to carry out 3D part segmentation. A bi-directional distillation, including forward and backward distillations, is carried out within the framework, where the former forward distills the 2D predictions to the student network, and the latter improves the quality of the 2D predictions, which subsequently enhances the final 3D segmentation. Moreover, PartDistill can exploit generative models that facilitate effortless 3D shape creation for generating knowledge sources to be distilled. Through extensive experiments, PartDistill boosts the existing methods with substantial margins on widely used ShapeNetPart and PartNetE datasets, by more than 15% and 12% higher mIoU scores, respectively. The code for this work is available at https://github.com/ardianumam/PartDistill.
Read more4/17/2024
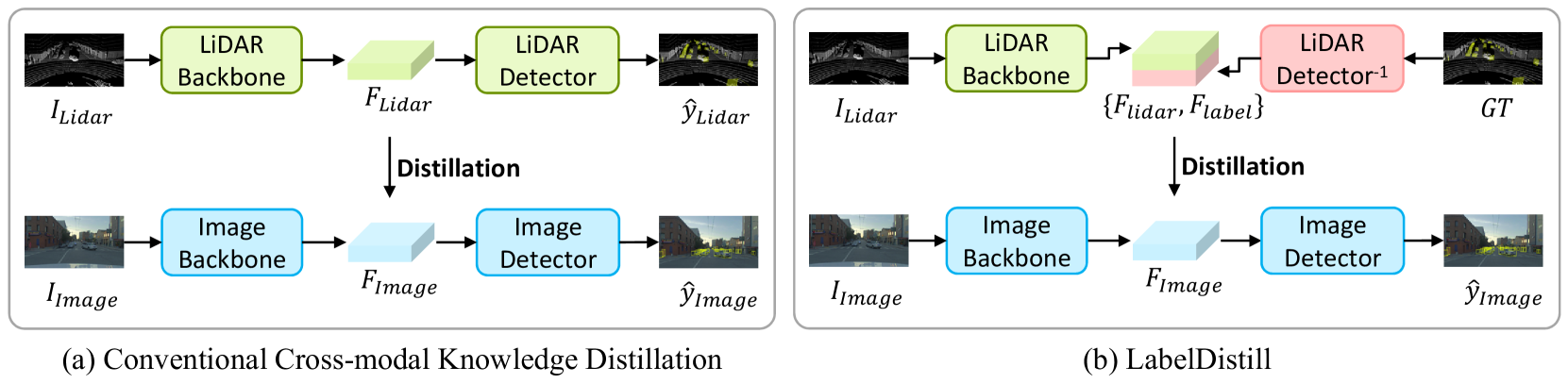
0
LabelDistill: Label-guided Cross-modal Knowledge Distillation for Camera-based 3D Object Detection
Sanmin Kim, Youngseok Kim, Sihwan Hwang, Hyeonjun Jeong, Dongsuk Kum
Recent advancements in camera-based 3D object detection have introduced cross-modal knowledge distillation to bridge the performance gap with LiDAR 3D detectors, leveraging the precise geometric information in LiDAR point clouds. However, existing cross-modal knowledge distillation methods tend to overlook the inherent imperfections of LiDAR, such as the ambiguity of measurements on distant or occluded objects, which should not be transferred to the image detector. To mitigate these imperfections in LiDAR teacher, we propose a novel method that leverages aleatoric uncertainty-free features from ground truth labels. In contrast to conventional label guidance approaches, we approximate the inverse function of the teacher's head to effectively embed label inputs into feature space. This approach provides additional accurate guidance alongside LiDAR teacher, thereby boosting the performance of the image detector. Additionally, we introduce feature partitioning, which effectively transfers knowledge from the teacher modality while preserving the distinctive features of the student, thereby maximizing the potential of both modalities. Experimental results demonstrate that our approach improves mAP and NDS by 5.1 points and 4.9 points compared to the baseline model, proving the effectiveness of our approach. The code is available at https://github.com/sanmin0312/LabelDistill
Read more7/16/2024