Multi-scale Restoration of Missing Data in Optical Time-series Images with Masked Spatial-Temporal Attention Network

0

Sign in to get full access
Overview
- This paper presents a multi-scale restoration method for addressing missing data in optical time-series remote sensing images.
- The proposed approach, called the Masked Spatial-Temporal Attention Network (MSTAN), leverages a masked spatial-temporal attention mechanism to capture both spatial and temporal dependencies in the data.
- The method employs a multi-objective joint optimization strategy to simultaneously restore missing data while preserving the original image characteristics.
Plain English Explanation
Remote sensing images captured over time can sometimes have missing data due to various reasons, such as cloud cover or sensor malfunctions. Restoring this missing data is crucial for many applications like environmental monitoring and urban planning.
The researchers in this paper developed a new method called the Masked Spatial-Temporal Attention Network (MSTAN) to address this problem. MSTAN uses a special type of "attention" mechanism to understand the relationships between different parts of the image, both in space and time. This allows the model to effectively fill in the missing data while preserving the original characteristics of the images.
The key innovation is the use of a "multi-scale" approach, which means the model operates at different levels of detail to capture information at various scales. This is important because different features in remote sensing images can exist at different scales, from small details to large-scale patterns.
MSTAN also employs a "multi-objective" optimization strategy, which means the model is trained to achieve two goals simultaneously: restoring the missing data and maintaining the original image properties. This helps ensure that the restored images are both accurate and realistic.
Technical Explanation
The MSTAN model consists of a multi-scale encoder-decoder architecture with a masked spatial-temporal attention mechanism. The encoder extracts features at multiple scales, while the decoder uses the attention mechanism to effectively fill in the missing data.
The attention mechanism works by allowing the model to focus on the most relevant parts of the image, both spatially and temporally, when restoring the missing information. This is achieved by introducing a "mask" that identifies the missing regions, which the attention module can then use to selectively attend to the available data.
The multi-objective optimization strategy is implemented by defining two loss functions: one for the restoration task and another for preserving the original image characteristics. The model is trained to minimize both loss functions simultaneously, ensuring that the restored images are both accurate and maintain the original image properties.
Critical Analysis
The authors acknowledge that MSTAN may struggle with heavily corrupted or rapidly changing time-series data, as the attention mechanism may not be able to effectively capture all the necessary spatial and temporal relationships. Further research could explore ways to enhance the attention mechanism or incorporate additional techniques to handle more challenging missing data scenarios.
Additionally, the authors do not provide a detailed analysis of the computational complexity and runtime of their method, which could be an important consideration for practical applications. [Future work could investigate ways to improve the efficiency of the MSTAN model, such as through the use of more advanced neural network architectures or specialized hardware.
Conclusion
This paper presents a novel multi-scale restoration method, the Masked Spatial-Temporal Attention Network (MSTAN), for addressing missing data in optical time-series remote sensing images. The key innovations are the use of a masked spatial-temporal attention mechanism to capture both spatial and temporal dependencies, and a multi-objective joint optimization strategy to restore missing data while preserving original image characteristics.
The results demonstrate the effectiveness of MSTAN in reconstructing missing data while maintaining the fidelity of the original images. This work has significant implications for a wide range of remote sensing applications that rely on high-quality, continuous time-series data, such as environmental monitoring, urban planning, and disaster response.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-scale Restoration of Missing Data in Optical Time-series Images with Masked Spatial-Temporal Attention Network
Zaiyan Zhang, Jining Yan, Yuanqi Liang, Jiaxin Feng, Haixu He, Wei Han
Due to factors such as thick cloud cover and sensor limitations, remote sensing images often suffer from significant missing data, resulting in incomplete time-series information. Existing methods for imputing missing values in remote sensing images do not fully exploit spatio-temporal auxiliary information, leading to limited accuracy in restoration. Therefore, this paper proposes a novel deep learning-based approach called MS2TAN (Multi-scale Masked Spatial-Temporal Attention Network), for reconstructing time-series remote sensing images. Firstly, we introduce an efficient spatio-temporal feature extractor based on Masked Spatial-Temporal Attention (MSTA), to obtain high-quality representations of the spatio-temporal neighborhood features in the missing regions. Secondly, a Multi-scale Restoration Network consisting of the MSTA-based Feature Extractors, is employed to progressively refine the missing values by exploring spatio-temporal neighborhood features at different scales. Thirdly, we propose a ``Pixel-Structure-Perception'' Multi-Objective Joint Optimization method to enhance the visual effects of the reconstruction results from multiple perspectives and preserve more texture structures. Furthermore, the proposed method reconstructs missing values in all input temporal phases in parallel (i.e., Multi-In Multi-Out), achieving higher processing efficiency. Finally, experimental evaluations on two typical missing data restoration tasks across multiple research areas demonstrate that the proposed method outperforms state-of-the-art methods with an improvement of 0.40dB/1.17dB in mean peak signal-to-noise ratio (mPSNR) and 3.77/9.41 thousandths in mean structural similarity (mSSIM), while exhibiting stronger texture and structural consistency.
Read more6/21/2024

0
A$^{2}$-MAE: A spatial-temporal-spectral unified remote sensing pre-training method based on anchor-aware masked autoencoder
Lixian Zhang, Yi Zhao, Runmin Dong, Jinxiao Zhang, Shuai Yuan, Shilei Cao, Mengxuan Chen, Juepeng Zheng, Weijia Li, Wei Liu, Wayne Zhang, Litong Feng, Haohuan Fu
Vast amounts of remote sensing (RS) data provide Earth observations across multiple dimensions, encompassing critical spatial, temporal, and spectral information which is essential for addressing global-scale challenges such as land use monitoring, disaster prevention, and environmental change mitigation. Despite various pre-training methods tailored to the characteristics of RS data, a key limitation persists: the inability to effectively integrate spatial, temporal, and spectral information within a single unified model. To unlock the potential of RS data, we construct a Spatial-Temporal-Spectral Structured Dataset (STSSD) characterized by the incorporation of multiple RS sources, diverse coverage, unified locations within image sets, and heterogeneity within images. Building upon this structured dataset, we propose an Anchor-Aware Masked AutoEncoder method (A$^{2}$-MAE), leveraging intrinsic complementary information from the different kinds of images and geo-information to reconstruct the masked patches during the pre-training phase. A$^{2}$-MAE integrates an anchor-aware masking strategy and a geographic encoding module to comprehensively exploit the properties of RS images. Specifically, the proposed anchor-aware masking strategy dynamically adapts the masking process based on the meta-information of a pre-selected anchor image, thereby facilitating the training on images captured by diverse types of RS sources within one model. Furthermore, we propose a geographic encoding method to leverage accurate spatial patterns, enhancing the model generalization capabilities for downstream applications that are generally location-related. Extensive experiments demonstrate our method achieves comprehensive improvements across various downstream tasks compared with existing RS pre-training methods, including image classification, semantic segmentation, and change detection tasks.
Read more6/18/2024

0
MSA2Net: Multi-scale Adaptive Attention-guided Network for Medical Image Segmentation
Sina Ghorbani Kolahi, Seyed Kamal Chaharsooghi, Toktam Khatibi, Afshin Bozorgpour, Reza Azad, Moein Heidari, Ilker Hacihaliloglu, Dorit Merhof
Medical image segmentation involves identifying and separating object instances in a medical image to delineate various tissues and structures, a task complicated by the significant variations in size, shape, and density of these features. Convolutional neural networks (CNNs) have traditionally been used for this task but have limitations in capturing long-range dependencies. Transformers, equipped with self-attention mechanisms, aim to address this problem. However, in medical image segmentation it is beneficial to merge both local and global features to effectively integrate feature maps across various scales, capturing both detailed features and broader semantic elements for dealing with variations in structures. In this paper, we introduce MSA$^2$Net, a new deep segmentation framework featuring an expedient design of skip-connections. These connections facilitate feature fusion by dynamically weighting and combining coarse-grained encoder features with fine-grained decoder feature maps. Specifically, we propose a Multi-Scale Adaptive Spatial Attention Gate (MASAG), which dynamically adjusts the receptive field (Local and Global contextual information) to ensure that spatially relevant features are selectively highlighted while minimizing background distractions. Extensive evaluations involving dermatology, and radiological datasets demonstrate that our MSA$^2$Net outperforms state-of-the-art (SOTA) works or matches their performance. The source code is publicly available at https://github.com/xmindflow/MSA-2Net.
Read more8/6/2024
0
Multi-Scale Representation Learning for Image Restoration with State-Space Model
Yuhong He, Long Peng, Qiaosi Yi, Chen Wu, Lu Wang
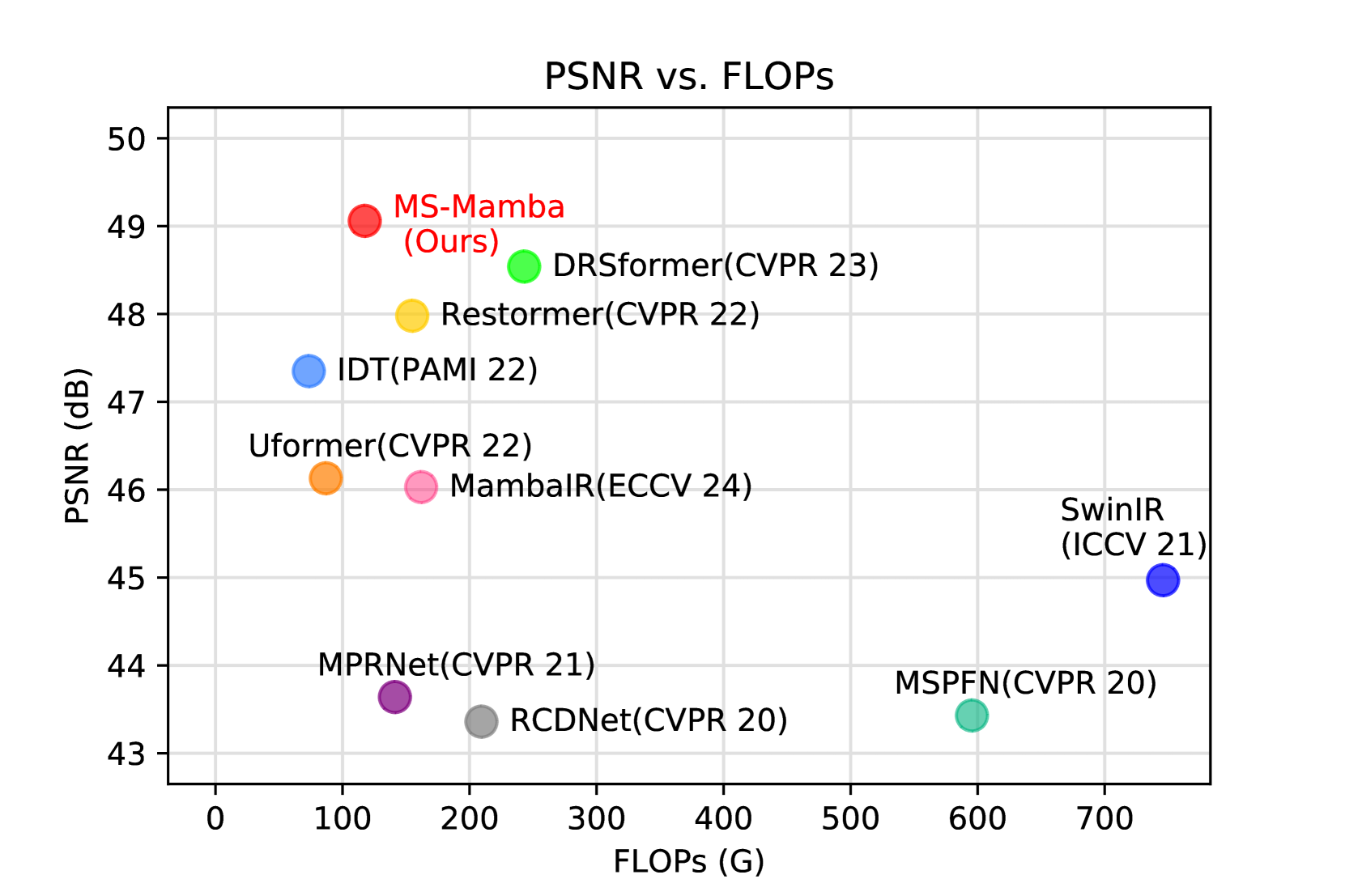
Image restoration endeavors to reconstruct a high-quality, detail-rich image from a degraded counterpart, which is a pivotal process in photography and various computer vision systems. In real-world scenarios, different types of degradation can cause the loss of image details at various scales and degrade image contrast. Existing methods predominantly rely on CNN and Transformer to capture multi-scale representations. However, these methods are often limited by the high computational complexity of Transformers and the constrained receptive field of CNN, which hinder them from achieving superior performance and efficiency in image restoration. To address these challenges, we propose a novel Multi-Scale State-Space Model-based (MS-Mamba) for efficient image restoration that enhances the capacity for multi-scale representation learning through our proposed global and regional SSM modules. Additionally, an Adaptive Gradient Block (AGB) and a Residual Fourier Block (RFB) are proposed to improve the network's detail extraction capabilities by capturing gradients in various directions and facilitating learning details in the frequency domain. Extensive experiments on nine public benchmarks across four classic image restoration tasks, image deraining, dehazing, denoising, and low-light enhancement, demonstrate that our proposed method achieves new state-of-the-art performance while maintaining low computational complexity. The source code will be publicly available.
Read more8/20/2024