Multi-Space Alignments Towards Universal LiDAR Segmentation

0
🛠️
Sign in to get full access
Overview
- This paper presents M3Net, a novel framework for multi-task, multi-dataset, and multi-modality LiDAR segmentation using a single set of parameters.
- M3Net aims to create a unified and versatile LiDAR segmentation model with strong robustness and generalizability, which is crucial for safe autonomous driving perception.
- The key innovations include combining large-scale driving datasets from diverse sensors and scenes, and aligning the data, feature, and label spaces during training to tame heterogeneous data.
Plain English Explanation
In this paper, the researchers introduce a new model called M3Net that can perform LiDAR-based 3D object segmentation in a very versatile and robust way. LiDAR is a key sensor for autonomous vehicles, as it can accurately measure the 3D structure of the environment. Segmentation, which involves dividing the LiDAR data into distinct objects or regions, is a crucial task for safe autonomous driving.
The researchers recognized that existing LiDAR segmentation models often struggle with handling diverse data from different sensors and driving scenarios. To address this, they developed M3Net, which can be trained on a wide variety of LiDAR datasets using a single set of parameters. This means M3Net can adapt to different environments and sensor setups without requiring extensive retraining or model modifications.
The key innovations in M3Net are:
-
Combining Large-Scale Datasets: The researchers combined multiple large-scale driving datasets acquired by different types of LiDAR sensors in diverse scenes. This exposes the model to a much richer and more representative set of data during training.
-
Aligning Data, Features, and Labels: To help the model learn from this heterogeneous data, the researchers conducted alignments in three key spaces: the data space, the feature space, and the label space. This ensures the model can effectively extract and relate the relevant information, despite differences in the underlying data.
By leveraging these techniques, M3Net is able to achieve state-of-the-art performance on a wide range of LiDAR segmentation benchmarks, using a single set of model parameters. This demonstrates the power of M3Net's versatility and robustness, which are crucial for enabling safe and reliable autonomous driving perception.
Technical Explanation
The paper presents the M3Net framework, which is designed to tackle the challenge of creating a unified and versatile LiDAR segmentation model with strong robustness and generalizability. To better exploit the wealth of data available for autonomous driving, the researchers first combined large-scale driving datasets acquired by different types of LiDAR sensors from diverse scenes.
To help the model learn effectively from this heterogeneous data, the researchers conducted alignments in three key spaces during training:
- Data Space Alignment: The researchers aligned the data distributions from different datasets to reduce domain gaps.
- Feature Space Alignment: They aligned the feature representations learned by the model across different datasets to ensure consistent feature extraction.
- Label Space Alignment: The researchers aligned the label spaces of the datasets to enable the model to recognize the same semantic classes consistently.
By performing these alignments, M3Net is able to tame the heterogeneous data and learn a unified representation that can be applied to a wide range of LiDAR segmentation tasks.
The core of M3Net is a multi-task, multi-dataset, and multi-modality segmentation framework that can be trained using a single set of model parameters. This allows M3Net to achieve state-of-the-art performance on various LiDAR segmentation benchmarks, including SemanticKITTI, nuScenes, and Waymo Open, without the need for extensive retraining or model modifications.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of creating a versatile and robust LiDAR segmentation model. The key innovations, such as combining large-scale datasets and aligning data, features, and labels, are well-justified and effectively demonstrated through extensive experiments.
However, the paper does not delve into potential limitations or caveats of the proposed M3Net framework. For example, it would be interesting to understand the computational and memory requirements of the model, as well as any potential trade-offs between its generalizability and task-specific performance. Additionally, the paper could have explored the transferability of M3Net to other modalities, such as fusing LiDAR with camera data or leveraging multi-camera data, to further enhance its robustness and applicability.
Overall, the M3Net framework represents a significant step forward in developing versatile and robust LiDAR segmentation models for autonomous driving. However, further research is needed to fully understand the limitations and potential extensions of this approach.
Conclusion
This paper introduces M3Net, a novel framework for multi-task, multi-dataset, and multi-modality LiDAR segmentation that achieves state-of-the-art performance using a single set of parameters. By combining large-scale driving datasets and aligning the data, feature, and label spaces, M3Net demonstrates impressive versatility and robustness, which are crucial for enabling safe and reliable autonomous driving perception. The proposed approach represents a significant advancement in the field of LiDAR segmentation and has the potential to significantly impact the development of next-generation autonomous vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Multi-Space Alignments Towards Universal LiDAR Segmentation
Youquan Liu, Lingdong Kong, Xiaoyang Wu, Runnan Chen, Xin Li, Liang Pan, Ziwei Liu, Yuexin Ma
A unified and versatile LiDAR segmentation model with strong robustness and generalizability is desirable for safe autonomous driving perception. This work presents M3Net, a one-of-a-kind framework for fulfilling multi-task, multi-dataset, multi-modality LiDAR segmentation in a universal manner using just a single set of parameters. To better exploit data volume and diversity, we first combine large-scale driving datasets acquired by different types of sensors from diverse scenes and then conduct alignments in three spaces, namely data, feature, and label spaces, during the training. As a result, M3Net is capable of taming heterogeneous data for training state-of-the-art LiDAR segmentation models. Extensive experiments on twelve LiDAR segmentation datasets verify our effectiveness. Notably, using a shared set of parameters, M3Net achieves 75.1%, 83.1%, and 72.4% mIoU scores, respectively, on the official benchmarks of SemanticKITTI, nuScenes, and Waymo Open.
Read more5/3/2024
🏋️
0
An Empirical Study of Training State-of-the-Art LiDAR Segmentation Models
Jiahao Sun, Chunmei Qing, Xiang Xu, Lingdong Kong, Youquan Liu, Li Li, Chenming Zhu, Jingwei Zhang, Zeqi Xiao, Runnan Chen, Tai Wang, Wenwei Zhang, Kai Chen
In the rapidly evolving field of autonomous driving, precise segmentation of LiDAR data is crucial for understanding complex 3D environments. Traditional approaches often rely on disparate, standalone codebases, hindering unified advancements and fair benchmarking across models. To address these challenges, we introduce MMDetection3D-lidarseg, a comprehensive toolbox designed for the efficient training and evaluation of state-of-the-art LiDAR segmentation models. We support a wide range of segmentation models and integrate advanced data augmentation techniques to enhance robustness and generalization. Additionally, the toolbox provides support for multiple leading sparse convolution backends, optimizing computational efficiency and performance. By fostering a unified framework, MMDetection3D-lidarseg streamlines development and benchmarking, setting new standards for research and application. Our extensive benchmark experiments on widely-used datasets demonstrate the effectiveness of the toolbox. The codebase and trained models have been publicly available, promoting further research and innovation in the field of LiDAR segmentation for autonomous driving.
Read more5/31/2024

0
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, Ziwei Liu
Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
Read more5/9/2024
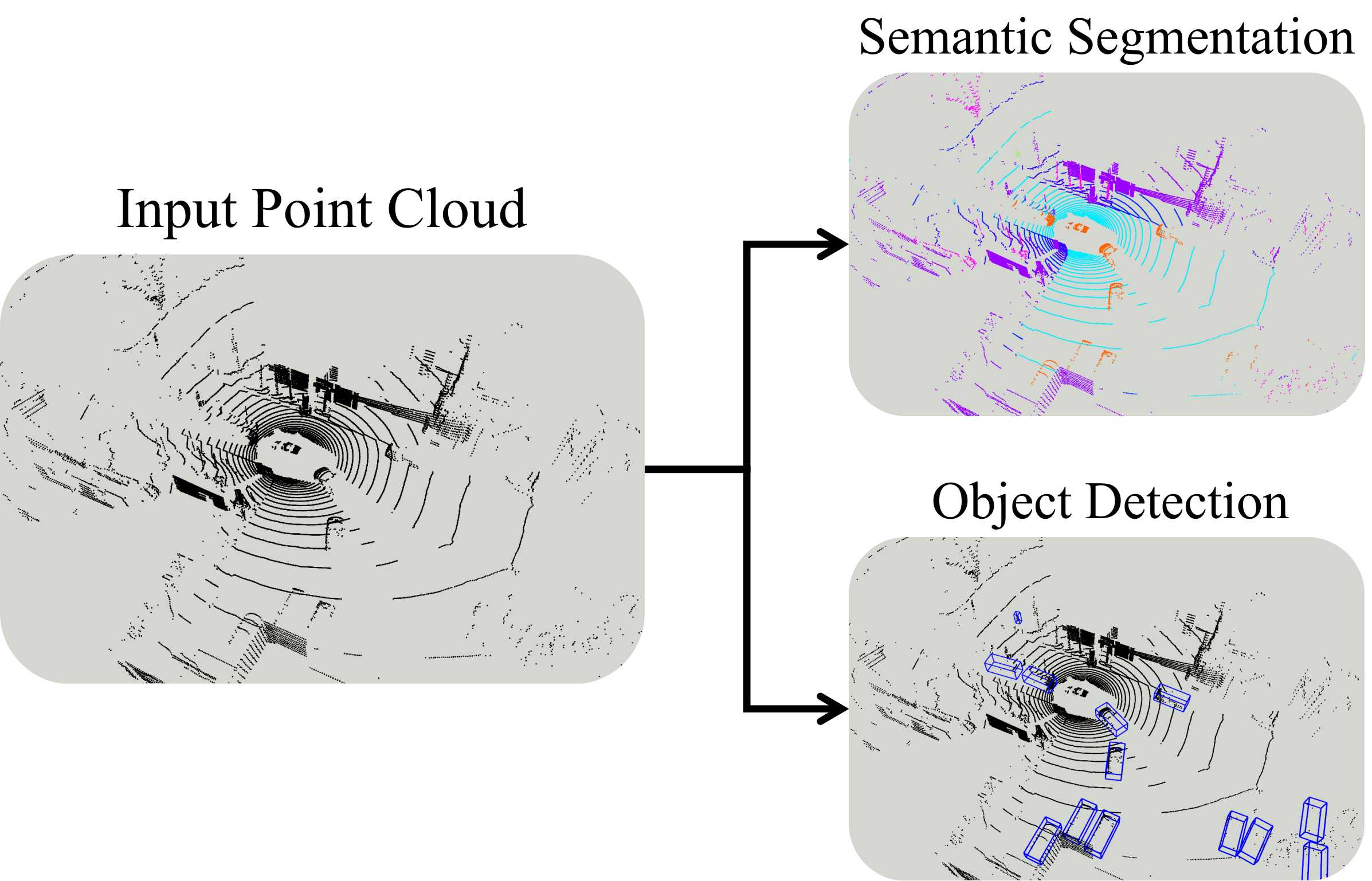
0
LiSD: An Efficient Multi-Task Learning Framework for LiDAR Segmentation and Detection
Jiahua Xu, Si Zuo, Chenfeng Wei, Wei Zhou
With the rapid proliferation of autonomous driving, there has been a heightened focus on the research of lidar-based 3D semantic segmentation and object detection methodologies, aiming to ensure the safety of traffic participants. In recent decades, learning-based approaches have emerged, demonstrating remarkable performance gains in comparison to conventional algorithms. However, the segmentation and detection tasks have traditionally been examined in isolation to achieve the best precision. To this end, we propose an efficient multi-task learning framework named LiSD which can address both segmentation and detection tasks, aiming to optimize the overall performance. Our proposed LiSD is a voxel-based encoder-decoder framework that contains a hierarchical feature collaboration module and a holistic information aggregation module. Different integration methods are adopted to keep sparsity in segmentation while densifying features for query initialization in detection. Besides, cross-task information is utilized in an instance-aware refinement module to obtain more accurate predictions. Experimental results on the nuScenes dataset and Waymo Open Dataset demonstrate the effectiveness of our proposed model. It is worth noting that LiSD achieves the state-of-the-art performance of 83.3% mIoU on the nuScenes segmentation benchmark for lidar-only methods.
Read more6/13/2024