A multi-speaker multi-lingual voice cloning system based on vits2 for limmits 2024 challenge

0

Sign in to get full access
Overview
- This paper presents a multi-speaker, multi-lingual voice cloning system based on the VITS2 (Variational Intelligent Text-to-Speech 2) architecture.
- The system is designed for the LIMMITS 2024 Challenge, which aims to develop voice cloning technologies that can handle multiple speakers and languages.
- The proposed system leverages techniques such as meta-learning for text-to-speech synthesis and LLAMA-VITS for enhancing TTS synthesis with semantic awareness.
Plain English Explanation
The researchers have developed a voice cloning system that can work with multiple speakers and languages. This is important because it allows the system to be used in a wider range of applications, such as creating personalized voice assistants or dubbing movies into different languages.
The system is based on the VITS2 architecture, which is a type of text-to-speech (TTS) system that can generate high-quality, natural-sounding speech. The researchers have added some additional techniques to make the system more powerful, such as meta-learning, which allows the system to quickly adapt to new speakers and languages, and LLAMA-VITS, which helps the system understand the semantic meaning of the text it's trying to convert to speech.
Overall, this system represents an important step forward in the field of voice cloning, and it could have a wide range of applications in the future.
Technical Explanation
The proposed system is based on the VITS2 (Variational Intelligent Text-to-Speech 2) architecture, which is a state-of-the-art text-to-speech (TTS) model that can generate high-quality, natural-sounding speech. To enable multi-speaker, multi-lingual capabilities, the researchers have incorporated several additional techniques:
- Meta-learning for text-to-speech synthesis: This allows the system to quickly adapt to new speakers and languages, reducing the amount of training data required.
- LLAMA-VITS for enhancing TTS synthesis with semantic awareness: This helps the system better understand the meaning of the text it's trying to convert to speech, leading to more natural-sounding and expressive output.
- Spoken language corpora augmentation for domain-specific voice: The researchers have used data augmentation techniques to expand the available training data, which is especially important for low-resource languages.
The combination of these techniques allows the proposed system to handle a wide range of speakers and languages, making it well-suited for the LIMMITS 2024 Challenge.
Critical Analysis
The research presented in this paper represents an important step forward in the field of multi-speaker, multi-lingual voice cloning. The use of techniques like meta-learning and LLAMA-VITS is particularly promising, as they address some of the key challenges in building robust and versatile TTS systems.
However, the paper does not provide a detailed evaluation of the system's performance across different speakers and languages, nor does it address potential issues such as speaker identity preservation or cross-lingual transfer. Additionally, the reliance on data augmentation techniques may raise concerns about the system's ability to handle truly low-resource languages or unexpected linguistic variations.
Further research is needed to fully understand the capabilities and limitations of this approach, as well as to explore alternative techniques that could further enhance the system's performance and generalization abilities.
Conclusion
The proposed multi-speaker, multi-lingual voice cloning system based on VITS2 represents an important advancement in the field of text-to-speech synthesis. By leveraging techniques like meta-learning and LLAMA-VITS, the system can handle a wider range of speakers and languages, making it a valuable tool for a variety of applications, from personalized voice assistants to multilingual content creation.
While further research is needed to fully understand the system's capabilities and limitations, this work sets the stage for the continued development of more flexible and adaptable voice cloning technologies, which could have a significant impact on how we interact with and consume digital content in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A multi-speaker multi-lingual voice cloning system based on vits2 for limmits 2024 challenge
Xiaopeng Wang, Yi Lu, Xin Qi, Zhiyong Wang, Yuankun Xie, Shuchen Shi, Ruibo Fu
This paper presents the development of a speech synthesis system for the LIMMITS'24 Challenge, focusing primarily on Track 2. The objective of the challenge is to establish a multi-speaker, multi-lingual Indic Text-to-Speech system with voice cloning capabilities, covering seven Indian languages with both male and female speakers. The system was trained using challenge data and fine-tuned for few-shot voice cloning on target speakers. Evaluation included both mono-lingual and cross-lingual synthesis across all seven languages, with subjective tests assessing naturalness and speaker similarity. Our system uses the VITS2 architecture, augmented with a multi-lingual ID and a BERT model to enhance contextual language comprehension. In Track 1, where no additional data usage was permitted, our model achieved a Speaker Similarity score of 4.02. In Track 2, which allowed the use of extra data, it attained a Speaker Similarity score of 4.17.
Read more6/27/2024
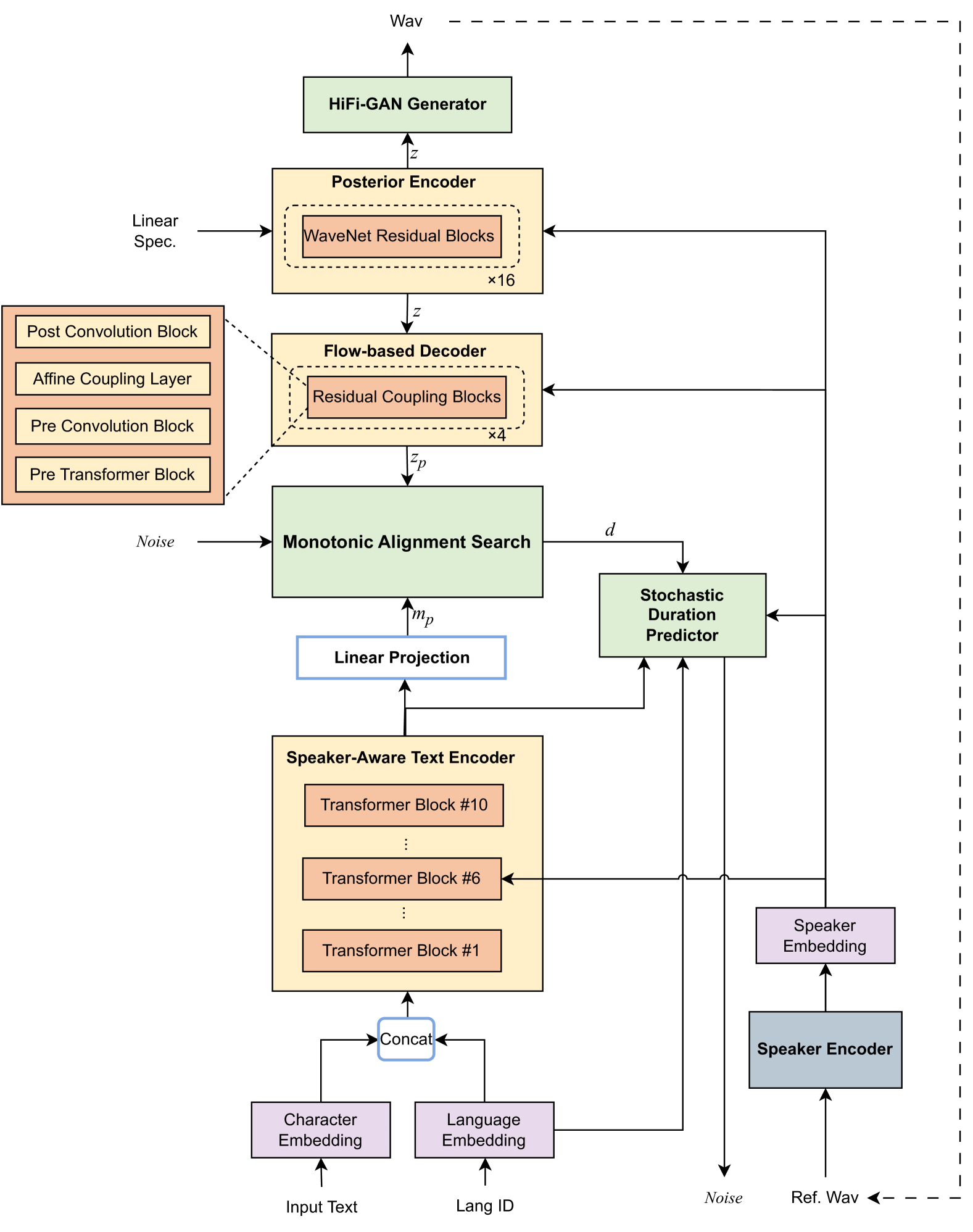
0
The THU-HCSI Multi-Speaker Multi-Lingual Few-Shot Voice Cloning System for LIMMITS'24 Challenge
Yixuan Zhou, Shuoyi Zhou, Shun Lei, Zhiyong Wu, Menglin Wu
This paper presents the multi-speaker multi-lingual few-shot voice cloning system developed by THU-HCSI team for LIMMITS'24 Challenge. To achieve high speaker similarity and naturalness in both mono-lingual and cross-lingual scenarios, we build the system upon YourTTS and add several enhancements. For further improving speaker similarity and speech quality, we introduce speaker-aware text encoder and flow-based decoder with Transformer blocks. In addition, we denoise the few-shot data, mix up them with pre-training data, and adopt a speaker-balanced sampling strategy to guarantee effective fine-tuning for target speakers. The official evaluations in track 1 show that our system achieves the best speaker similarity MOS of 4.25 and obtains considerable naturalness MOS of 3.97.
Read more4/26/2024

0
Advancing Voice Cloning for Nepali: Leveraging Transfer Learning in a Low-Resource Language
Manjil Karki, Pratik Shakya, Sandesh Acharya, Ravi Pandit, Dinesh Gothe
Voice cloning is a prominent feature in personalized speech interfaces. A neural vocal cloning system can mimic someone's voice using just a few audio samples. Both speaker encoding and speaker adaptation are topics of research in the field of voice cloning. Speaker adaptation relies on fine-tuning a multi-speaker generative model, which involves training a separate model to infer a new speaker embedding used for speaker encoding. Both methods can achieve excellent performance, even with a small number of cloning audios, in terms of the speech's naturalness and similarity to the original speaker. Speaker encoding approaches are more appropriate for low-resource deployment since they require significantly less memory and have a faster cloning time than speaker adaption, which can offer slightly greater naturalness and similarity. The main goal is to create a vocal cloning system that produces audio output with a Nepali accent or that sounds like Nepali. For the further advancement of TTS, the idea of transfer learning was effectively used to address several issues that were encountered in the development of this system, including the poor audio quality and the lack of available data.
Read more8/26/2024

0
VECL-TTS: Voice identity and Emotional style controllable Cross-Lingual Text-to-Speech
Ashishkumar Gudmalwar, Nirmesh Shah, Sai Akarsh, Pankaj Wasnik, Rajiv Ratn Shah
Despite the significant advancements in Text-to-Speech (TTS) systems, their full utilization in automatic dubbing remains limited. This task necessitates the extraction of voice identity and emotional style from a reference speech in a source language and subsequently transferring them to a target language using cross-lingual TTS techniques. While previous approaches have mainly concentrated on controlling voice identity within the cross-lingual TTS framework, there has been limited work on incorporating emotion and voice identity together. To this end, we introduce an end-to-end Voice Identity and Emotional Style Controllable Cross-Lingual (VECL) TTS system using multilingual speakers and an emotion embedding network. Moreover, we introduce content and style consistency losses to enhance the quality of synthesized speech further. The proposed system achieved an average relative improvement of 8.83% compared to the state-of-the-art (SOTA) methods on a database comprising English and three Indian languages (Hindi, Telugu, and Marathi).
Read more6/13/2024