Spoken Language Corpora Augmentation with Domain-Specific Voice-Cloned Speech

0

Sign in to get full access
Overview
- This paper explores a method to augment spoken language corpora by generating domain-specific voice-cloned speech.
- The researchers developed a framework to clone the voice of a target speaker and use it to generate synthetic speech in a specific domain, such as customer service or technical support.
- The goal is to expand the diversity and coverage of speech data for training machine learning models, particularly in areas where limited real speech data is available.
Plain English Explanation
The researchers in this paper wanted to find a way to create more speech data for training AI models. Often, there isn't enough real speech data available, especially for specific domains like customer service or technical support. To solve this, they developed a method to "clone" the voice of a target speaker and then use that cloned voice to generate new synthetic speech in the desired domain.
This builds on prior work in areas like multi-speaker text-to-speech training and cross-domain audio deepfake detection. The key idea is to take a reference speaker's voice and adapt it to generate new speech that sounds like it's coming from that same speaker, but on topics relevant to a specific domain.
This synthetic training data generation can help expand the diversity and coverage of speech data available for training machine learning models, which is especially important in areas where there is limited real-world speech data to work with.
Technical Explanation
The researchers developed a framework that consists of two main components:
- A voice cloning module that can transform the voice of a reference speaker to match a target speaker's voice characteristics.
- A speech synthesis module that generates new domain-specific speech using the cloned voice.
They evaluated their approach by conducting experiments on two task-oriented dialogue datasets - a customer service dataset and a technical support dataset. The results showed that the generated voice-cloned speech could successfully expand the diversity of the original speech corpora, leading to improved performance on downstream speech recognition and dialogue modeling tasks.
Key technical insights include:
- Leveraging speaker augmentation techniques to enhance the voice cloning module
- Using text-to-speech models trained on multi-speaker data to enable domain-specific speech synthesis
- Exploring methods to generate high-quality synthetic speech that sounds natural and matches the target speaker's voice
Critical Analysis
The researchers acknowledge several limitations of their approach, including the potential for the synthetic speech to be detected as "fake" by audio deepfake classifiers, and the need for a sizable amount of reference speech data for the voice cloning module to work effectively.
Additionally, while the experiments showed promising results, the paper does not provide a comprehensive analysis of the quality and perceptual realism of the generated speech samples. Further user studies or perceptual evaluations would be valuable to better understand the limitations and tradeoffs of this approach.
It's also important to consider the ethical implications of using voice cloning technology, as it could potentially be misused for malicious purposes, such as impersonating real individuals. The researchers do not address these ethical concerns in depth.
Overall, the proposed framework represents an interesting and potentially useful approach to expanding spoken language corpora, but more research is needed to fully understand its capabilities and limitations, as well as the broader societal implications of this technology.
Conclusion
This paper presents a novel method for augmenting spoken language corpora using domain-specific voice-cloned speech. By leveraging voice cloning and text-to-speech techniques, the researchers were able to generate synthetic speech that can enhance the diversity and coverage of existing speech datasets, particularly in areas with limited real-world data.
The results of the experiments suggest that this approach can lead to improvements in downstream speech recognition and dialogue modeling tasks. However, the authors acknowledge several key limitations and areas for further research, including the need for more comprehensive evaluations of the synthetic speech quality and potential ethical considerations.
Overall, this work represents an important step forward in addressing the data scarcity challenges faced in building robust spoken language systems, and the techniques developed here could have broader applications in areas such as personalized voice assistants and audiobook generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spoken Language Corpora Augmentation with Domain-Specific Voice-Cloned Speech
Mateusz Czy.znikiewicz, {L}ukasz Bondaruk, Jakub Kubiak, Adam Wik{a}cek, {L}ukasz Deg'orski, Marek Kubis, Pawe{l} Sk'orzewski
In this paper we study the impact of augmenting spoken language corpora with domain-specific synthetic samples for the purpose of training a speech recognition system. Using both a conventional neural TTS system and a zero-shot one with voice cloning ability we generate speech corpora that vary in the number of voices. We compare speech recognition models trained with addition of different amounts of synthetic data generated using these two methods with a baseline model trained solely on voice recordings. We show that while the quality of voice-cloned dataset is lower, its increased multivoiceity makes it much more effective than the one with only a few voices synthesized with the use of a conventional neural TTS system. Furthermore, our experiments indicate that using low variability synthetic speech quickly leads to saturation in the quality of the ASR whereas high variability speech provides improvement even when increasing total amount of data used for training by 30%.
Read more7/30/2024
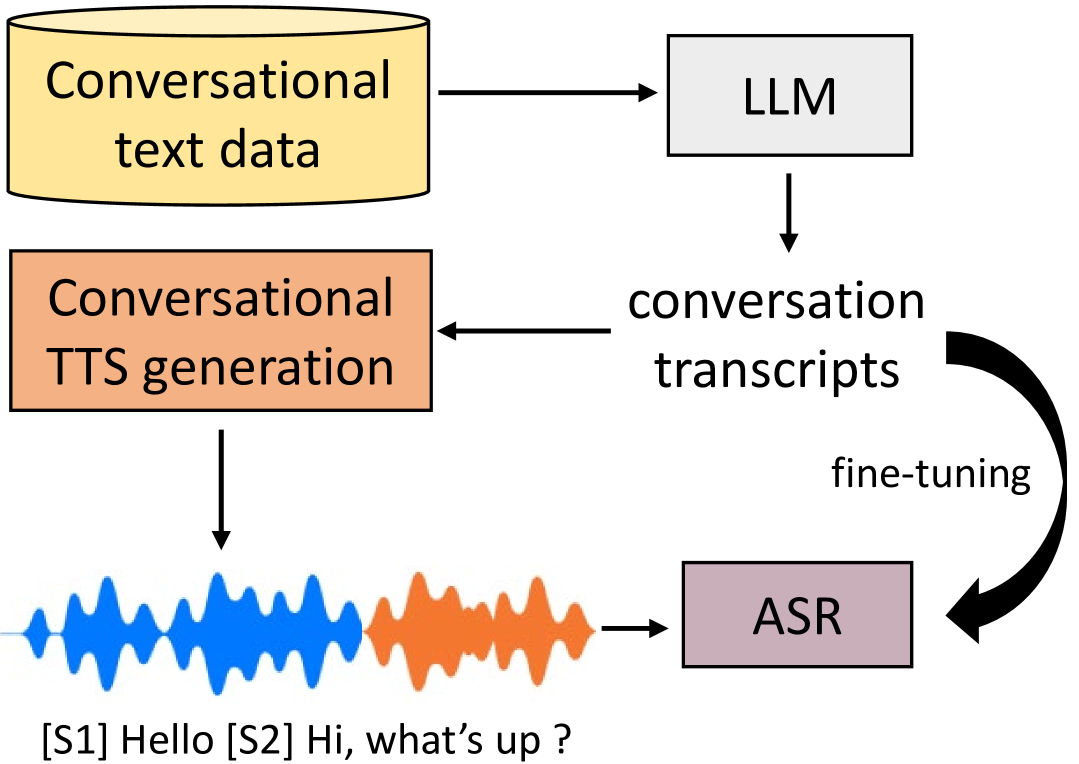
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024

0
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
John Janiczek, Dading Chong, Dongyang Dai, Arlo Faria, Chao Wang, Tao Wang, Yuzong Liu
A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
Read more8/29/2024

0
New!Zero Shot Text to Speech Augmentation for Automatic Speech Recognition on Low-Resource Accented Speech Corpora
Francesco Nespoli, Daniel Barreda, Patrick A. Naylor
In recent years, automatic speech recognition (ASR) models greatly improved transcription performance both in clean, low noise, acoustic conditions and in reverberant environments. However, all these systems rely on the availability of hundreds of hours of labelled training data in specific acoustic conditions. When such a training dataset is not available, the performance of the system is heavily impacted. For example, this happens when a specific acoustic environment or a particular population of speakers is under-represented in the training dataset. Specifically, in this paper we investigate the effect of accented speech data on an off-the-shelf ASR system. Furthermore, we suggest a strategy based on zero-shot text-to-speech to augment the accented speech corpora. We show that this augmentation method is able to mitigate the loss in performance of the ASR system on accented data up to 5% word error rate reduction (WERR). In conclusion, we demonstrate that by incorporating a modest fraction of real with synthetically generated data, the ASR system exhibits superior performance compared to a model trained exclusively on authentic accented speech with up to 14% WERR.
Read more9/18/2024