Meta Learning Text-to-Speech Synthesis in over 7000 Languages
2406.06403
0
0

Abstract
In this work, we take on the challenging task of building a single text-to-speech synthesis system that is capable of generating speech in over 7000 languages, many of which lack sufficient data for traditional TTS development. By leveraging a novel integration of massively multilingual pretraining and meta learning to approximate language representations, our approach enables zero-shot speech synthesis in languages without any available data. We validate our system's performance through objective measures and human evaluation across a diverse linguistic landscape. By releasing our code and models publicly, we aim to empower communities with limited linguistic resources and foster further innovation in the field of speech technology.
Create account to get full access
Overview
This research paper introduces a new approach for training text-to-speech (TTS) models that can generate speech in over 7,000 languages. The key innovation is the use of meta-learning, which allows the model to rapidly adapt to new languages with limited data. The researchers demonstrate that their approach, called XTTS, outperforms previous state-of-the-art multilingual TTS models on a range of evaluation metrics.
Plain English Explanation
The researchers have developed a way to teach AI models how to generate human-like speech in thousands of languages, even if they don't have much data for a particular language. Normally, training a TTS model for a new language requires a lot of audio recordings and transcripts, which can be difficult to obtain for lesser-known languages.
The researchers' approach uses a technique called meta-learning, which allows the model to "learn how to learn" new languages quickly. Instead of training the model on data from every language, they train it on a diverse set of languages and teach it general principles for adapting to new ones.
When the model encounters a new language, it can leverage this meta-learning to rapidly adjust its parameters and generate natural-sounding speech with just a small amount of data. This makes it possible to expand TTS capabilities to a huge number of languages, which could be transformative for applications like language preservation, education, and global communication.
Technical Explanation
The key component of the researchers' approach is a meta-learning framework that allows the model to quickly adapt to new languages. They start by training the model on a large corpus of speech data covering thousands of languages. This trains the model to learn general linguistic principles that are applicable across languages.
Then, during meta-training, the model is exposed to many different language tasks, each with limited data. It learns to rapidly adjust its parameters to perform well on these few-shot language tasks, developing meta-level skills for language adaptation. This meta-trained model can then be fine-tuned on a new target language with just a small amount of data, allowing it to generate high-quality speech in that language.
The researchers also incorporate several other innovations, such as phonetic-enhanced language modeling and large-scale multilingual translation, to further improve the model's performance and efficiency, especially for mobile TTS applications.
Critical Analysis
The researchers have demonstrated impressive results, with their XTTS model outperforming previous state-of-the-art multilingual TTS systems on a range of metrics. However, the paper does note some limitations, such as the need for further improvements in audio quality and the fact that the model still requires some language-specific data for fine-tuning.
Additionally, while the meta-learning approach is a clever solution for expanding TTS to thousands of languages, it remains to be seen how well it will scale as the number of target languages grows even larger. There may be practical limits on the maximum number of languages the model can effectively learn to adapt to.
The researchers also do not address potential societal implications or ethical concerns around the deployment of such a powerful multilingual TTS system. For example, there could be risks around the misuse of synthesized speech for disinformation or the potential to exacerbate existing language barriers and inequalities.
Overall, this research represents an important advance in multilingual TTS, but further work is needed to fully realize the potential benefits while mitigating potential downsides.
Conclusion
The researchers have developed a novel meta-learning approach for training text-to-speech models that can generate speech in over 7,000 languages. By teaching the model general principles for rapidly adapting to new languages, they have overcome the data scarcity challenges that have historically limited the expansion of multilingual TTS capabilities.
This breakthrough could have far-reaching applications, from supporting endangered language preservation to enabling more accessible global communication. However, the researchers must also consider potential ethical implications and work to ensure their technology is deployed responsibly. Continued research and development in this area could lead to transformative advances in multilingual AI technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Edresson Casanova, Kelly Davis, Eren Golge, Gorkem Goknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, Julian Weber
0
0
Most Zero-shot Multi-speaker TTS (ZS-TTS) systems support only a single language. Although models like YourTTS, VALL-E X, Mega-TTS 2, and Voicebox explored Multilingual ZS-TTS they are limited to just a few high/medium resource languages, limiting the applications of these models in most of the low/medium resource languages. In this paper, we aim to alleviate this issue by proposing and making publicly available the XTTS system. Our method builds upon the Tortoise model and adds several novel modifications to enable multilingual training, improve voice cloning, and enable faster training and inference. XTTS was trained in 16 languages and achieved state-of-the-art (SOTA) results in most of them.
6/10/2024
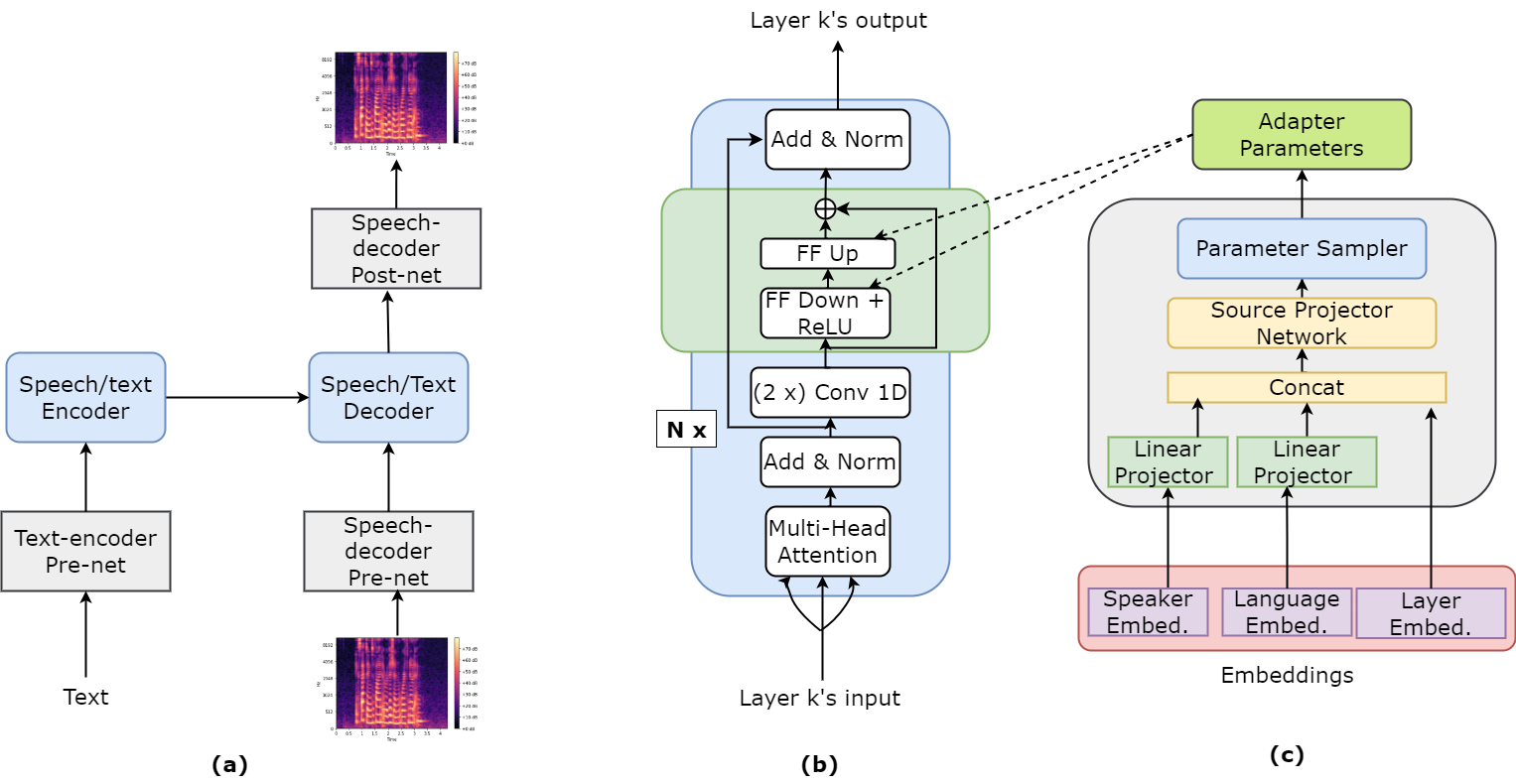
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
0
0
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
6/26/2024
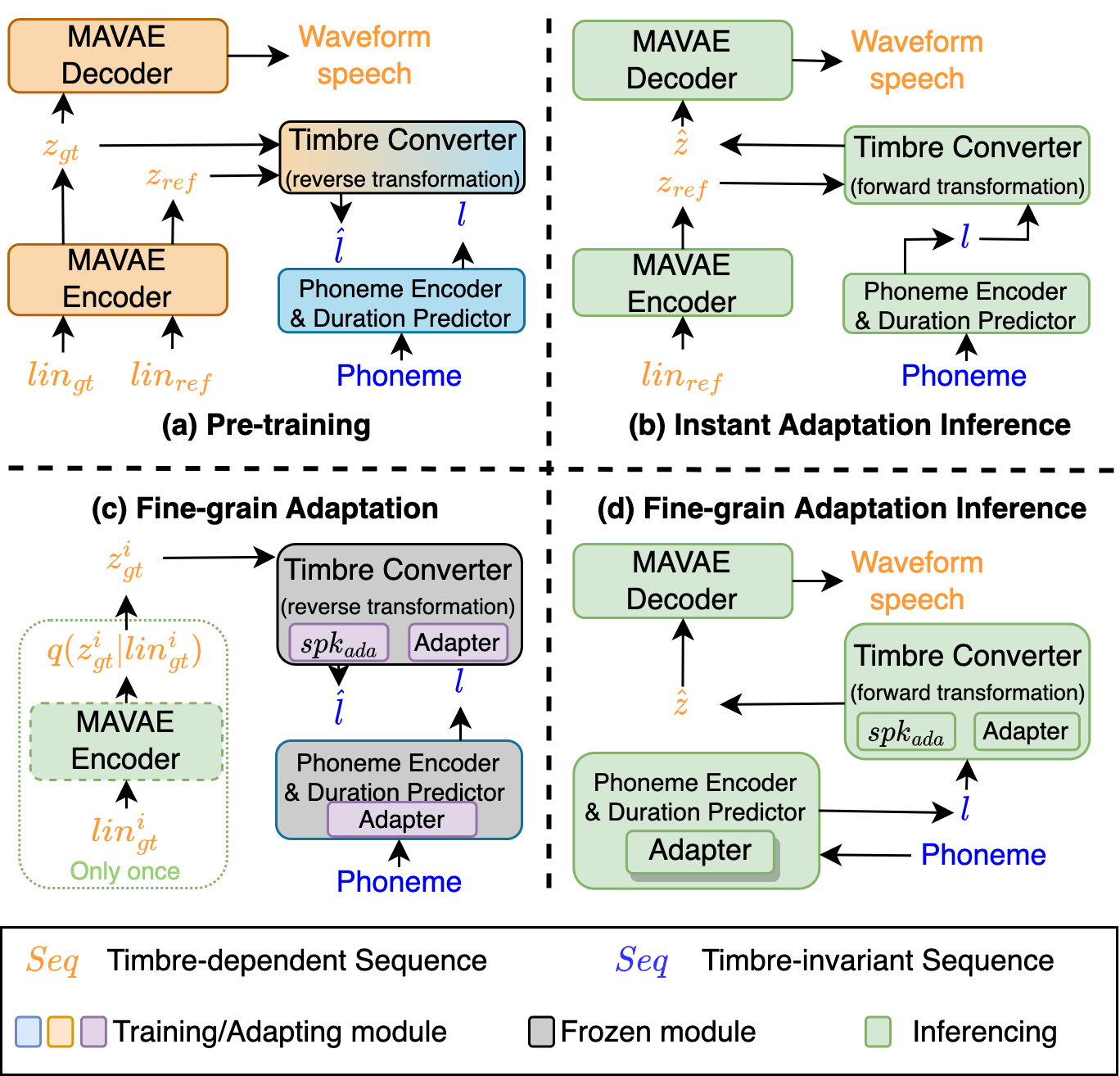
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024

Towards Zero-Shot Text-To-Speech for Arabic Dialects
Khai Duy Doan, Abdul Waheed, Muhammad Abdul-Mageed
0
0
Zero-shot multi-speaker text-to-speech (ZS-TTS) systems have advanced for English, however, it still lags behind due to insufficient resources. We address this gap for Arabic, a language of more than 450 million native speakers, by first adapting a sizeable existing dataset to suit the needs of speech synthesis. Additionally, we employ a set of Arabic dialect identification models to explore the impact of pre-defined dialect labels on improving the ZS-TTS model in a multi-dialect setting. Subsequently, we fine-tune the XTTSfootnote{https://docs.coqui.ai/en/latest/models/xtts.html}footnote{https://medium.com/machine-learns/xtts-v2-new-version-of-the-open-source-text-to-speech-model-af73914db81f}footnote{https://medium.com/@erogol/xtts-v1-techincal-notes-eb83ff05bdc} model, an open-source architecture. We then evaluate our models on a dataset comprising 31 unseen speakers and an in-house dialectal dataset. Our automated and human evaluation results show convincing performance while capable of generating dialectal speech. Our study highlights significant potential for improvements in this emerging area of research in Arabic.
6/26/2024