Multi-Stage Multi-Modal Pre-Training for Automatic Speech Recognition
2403.19822
0
0
Abstract
Recent advances in machine learning have demonstrated that multi-modal pre-training can improve automatic speech recognition (ASR) performance compared to randomly initialized models, even when models are fine-tuned on uni-modal tasks. Existing multi-modal pre-training methods for the ASR task have primarily focused on single-stage pre-training where a single unsupervised task is used for pre-training followed by fine-tuning on the downstream task. In this work, we introduce a novel method combining multi-modal and multi-task unsupervised pre-training with a translation-based supervised mid-training approach. We empirically demonstrate that such a multi-stage approach leads to relative word error rate (WER) improvements of up to 38.45% over baselines on both Librispeech and SUPERB. Additionally, we share several important findings for choosing pre-training methods and datasets.
Get summaries of the top AI research delivered straight to your inbox:
Introduction
The paper explores the impact of exposing automatic speech recognition (ASR) models to diverse audio-visual data during pre-training. The authors evaluate multiple audio-visual pre-training methods using datasets with varying characteristics and introduce a novel mid-training stage using speech translation. Key findings include:
-
Pre-training with audio-visual data, particularly from speech-specific datasets, can improve word error rate (WER) by up to 30.8% relative to randomly initialized baseline models on speech-only test data.
-
The mid-training stage, introduced between pre-training and fine-tuning, improves WER by 38.45% on the Librispeech test-clean dataset and 26.18% on the test-other dataset compared to audio-visual pre-training only baselines.
-
The proposed techniques also show improvements on several tasks in the SUPERB benchmark, including Keyword Spotting, Intent Classification, Phoneme Recognition, and Speaker Diarization.
The paper highlights the importance of exposing ASR models to diverse data during pre-training and introduces a novel mid-training approach to consolidate learned information, leading to significant performance improvements.
Background
The paper discusses representation learning methods for automatic speech recognition (ASR), focusing on two main approaches: masked autoencoding and contrastive learning. While most self-supervised methods use a single target loss and dataset for pre-training, recent work has shown the benefits of combining multiple losses and diverse datasets, including audio-visual data and multiple languages. The authors aim to improve learned multi-modal representations by using a combination of losses and pre-training stages with different datasets.
Audio-visual data provides diverse information for representation learning, and studies have shown that incorporating visual input during training can improve ASR performance. Some methods extend pre-training approaches to scenarios where both uni-modal and multi-modal data are available during training, while others demonstrate that pre-training with paired audio-visual data can enhance performance on uni-modal datasets.
In addition to multiple modalities, pre-training with multiple languages has been explored. Research has shown that pre-training with a wide range of inputs from several languages improves ASR performance across all studied languages. Leveraging self-supervised learning for knowledge transfer across languages can yield significant improvements in word error rate (WER) on target languages. Even out-of-domain multi-lingual data can improve WER in various conversation and dictation tasks.
Methods
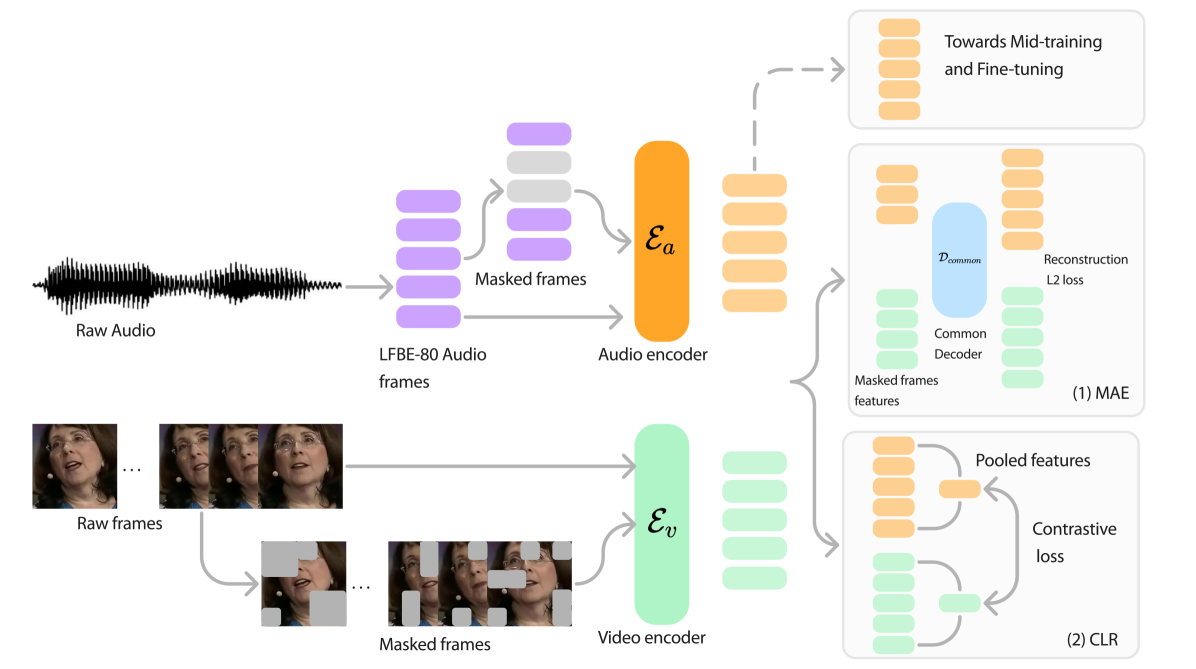
This paper presents a multi-stage, multi-modal pre-training approach for audio-visual models, followed by fine-tuning on downstream tasks. The authors experiment with two pre-training strategies: Masked Autoencoder (MAE) for learning local features and Contrastive Learning (CLR) for learning global features. MAE consists of masked audio and video-specific encoders and a joint transformer decoder, while CLR uses pooled audio-visual features from the same video as positive pairs and other combinations as negatives.
The pre-training datasets used are Kinetics-600 (non-speech), Voxceleb2 (noisy speech), and LRS3 (clean speech). A mid-training task of speech translation using the MuST-C dataset is introduced to bridge the gap between pre-training and fine-tuning. The models are evaluated on downstream tasks such as ASR (Librispeech) and SUPERB benchmark tasks.
The video encoder divides the video into space-time patches, which are flattened and augmented with positional embeddings. For MAE, 60% of the patches are masked, and the remaining are passed through ViT encoder blocks. For CLR, the patches are reduced to a single embedding per frame and temporally pooled.
The audio encoder uses sub-sampled LFBE features with positional embeddings. In MAE, 60% of the frames are masked, and the rest are encoded by a Conformer. In CLR, the frames are featurized without masking and temporally pooled.
The results show that translation mid-training consistently improves performance, especially for CLR, and that Italian language is the most effective mid-training task. The paper suggests that complementary languages to English may be more useful for mid-training.
Results, Analysis & Limitations
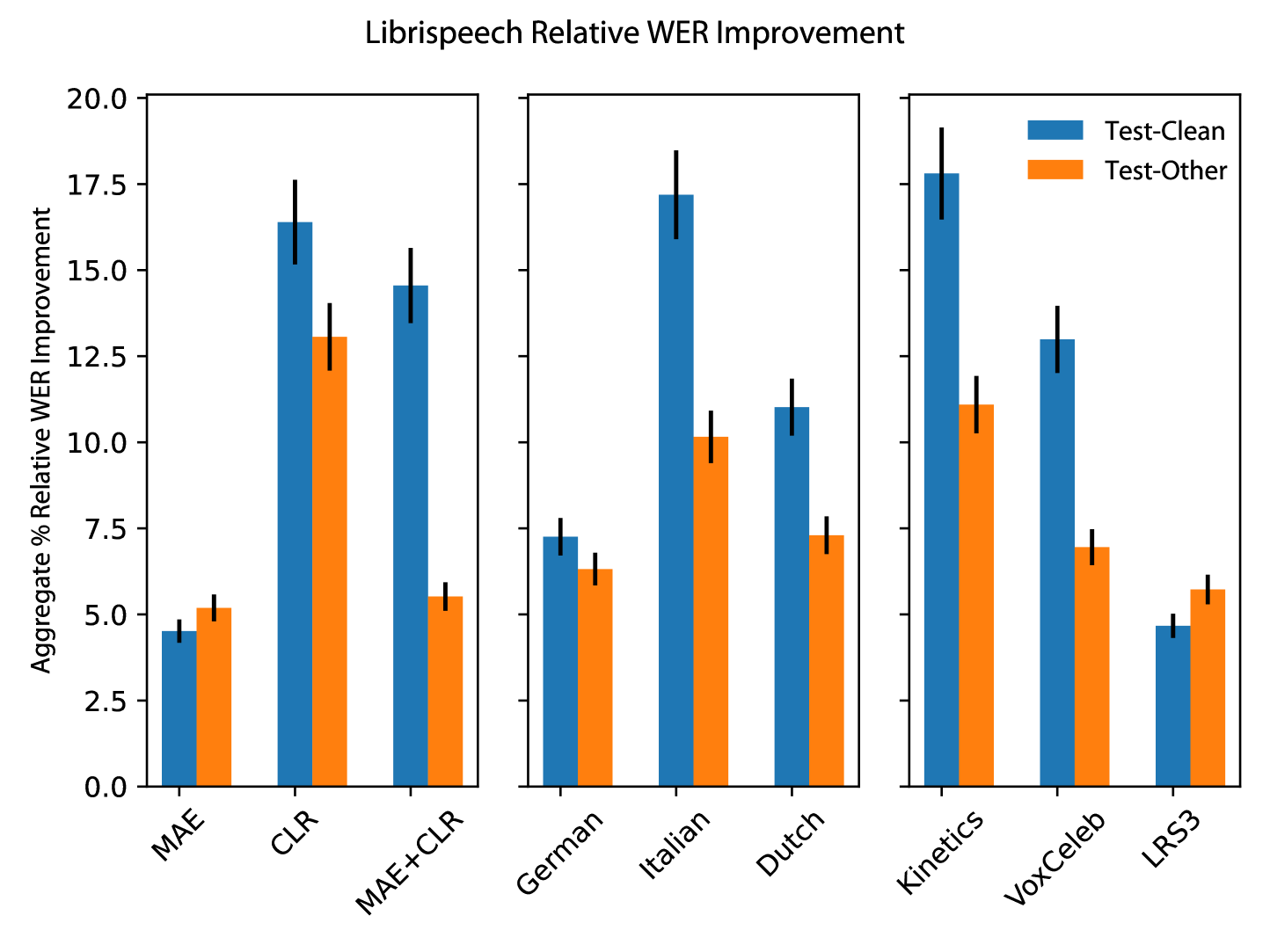
The main results on the Librispeech dataset, shown in Table 1 and Figure 3, demonstrate several key findings:
-
Audio-visual pre-training is effective, with significant improvements over the baseline.
-
Mid-training with all translation pairs improves ASR performance, with Italian being the most effective, suggesting that complementary languages to English may be more useful than languages closer to the target language.
-
The distributional makeup of the multi-modal dataset is key to pre-training performance, not just dataset size. Models pre-trained on LRS-3, the smallest dataset, outperform others on the test-other dataset.
-
The model pre-trained on Kinetics, which contains no speech data, improves the most with mid-training, while the LRS-3 model, consisting of primarily clean data, has less to gain.
-
Multi-task learning may be more effective on out-of-domain data, where modalities contain non-redundant audio information.
-
MAE alone outperforms both CLR and MAE+CLR for ASR results averaged over all pre-training datasets, suggesting that pre-training with masked auto-encoding objectives remains a promising approach for future exploration.

The research explores the effectiveness of mid-training on four tasks from the SUPERB benchmark. Mid-training improves performance for MAE+CLR models across most tasks, with the exception of speaker diarization (SD) due to minimal task overlap with the mid-training target. Intent Classification (IC) sees the most improvement, particularly for models pre-trained on the Kinetics and LRS-3 datasets, benefiting from additional textual alignment. Keyword spotting (KS) improvements are largely attributed to enhancements in Kinetics pre-trained models. Models pre-trained on VoxCeleb2 show less improvement with mid-training compared to those pre-trained on Kinetics and LRS-3 for all tasks, possibly because VoxCeleb2 is already multi-lingual and benefits less from further multi-lingual training.
The paper notes that the baseline conformer models used in the experiments do not match the performance reported by Gulati et al. (2020). The primary goal of the work was not to achieve state-of-the-art performance but to study the impact of pre-training methods and datasets on automatic speech recognition (ASR) performance. The higher word error rate (WER) is attributed to the lower batch size used in the experiments, which was necessary to accommodate the large number of ablation studies conducted for the paper. Despite the lower baseline performance, the insights gained from the relative performance comparisons across the large-scale ablation studies are considered transferable to larger, more expensive models.
The key findings of the study are:
- Audio-visual pre-training is effective in almost all scenarios.
- Mid-training is useful, and including complementary data is more effective than including data similar to pre-training data.
- The clean speech audio-visual dataset LRS-3 is an effective pre-training dataset given its size, compared to Kinetics and Voxceleb2.
- Masked Acoustic Modeling (MAE) pre-training is more effective than contrastive learning in ASR, while augmenting pre-training with Contrastive Language-Image Pre-training (CLIP) can help with downstream tasks that use global information.
Discussion
The paper discusses the increasing size of pre-trained models and datasets, making it expensive to pre-train models on datasets aligned with specific downstream tasks. As a solution, the authors propose a lightweight mid-training strategy to tune the pre-trained features and enhance downstream performance. They compare this approach to an alternative strategy of including the task during pre-training, highlighting two drawbacks. First, the limited amount of labeled data available for the mid-training task may not significantly impact performance when jointly learned during pre-training. Second, the mid-training approach is more practical as it can be applied to existing pre-trained models, avoiding the need for time-consuming and computationally expensive training from scratch.
Conclusion & Future Directions
The paper explores the impact of multi-lingual mid-training objectives and large-scale audio-visual pre-training methods on downstream automatic speech recognition (ASR) performance. The findings confirm previous observations, showing that well-chosen mid-training tasks can significantly improve the performance of multi-modal pre-trained models on the final downstream task. However, the authors suggest that further research is needed to fully understand how sequences of training tasks can effectively align large pre-trained models with downstream tasks.
The paper proposes exploring additional mid-training tasks, such as those based on synthetic data or self-supervised approaches, as an interesting direction for future work. Additionally, investigating how pre-training tasks impact the performance of downstream and mid-trained models is another closely related area for future research. While the current study focuses on multi-modal pre-training, the authors note that mid-training can also be applied to uni-modal pre-training or even zero-shot transfer from foundational models.
In summary, this study highlights the significant improvement in downstream ASR performance achieved through large-scale audio-visual pre-training and the use of mid-training tasks. By continuing to explore these areas, researchers can advance the understanding of how to effectively align pre-trained models with diverse downstream tasks and unlock new possibilities in multi-modal ASR research.
Bibliographical References
There is no text provided in this section to summarize.
Related Papers
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024
🌀
Data-Efficient Multimodal Fusion on a Single GPU
Noel Vouitsis, Zhaoyan Liu, Satya Krishna Gorti, Valentin Villecroze, Jesse C. Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, Maksims Volkovs
0
0
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $sim ! 600times$ fewer GPU days and $sim ! 80times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
4/11/2024
➖
Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
Xiao Wang, Guangyao Chen, Guangwu Qian, Pengcheng Gao, Xiao-Yong Wei, Yaowei Wang, Yonghong Tian, Wen Gao
0
0
With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey. This paper has been published by the journal Machine Intelligence Research (MIR), https://link.springer.com/article/10.1007/s11633-022-1410-8, DOI: 10.1007/s11633-022-1410-8, vol. 20, no. 4, pp. 447-482, 2023.
4/11/2024
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Tongkun Su, Jun Li, Xi Zhang, Haibo Jin, Hao Chen, Qiong Wang, Faqin Lv, Baoliang Zhao, Yin Hu
0
0
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
4/9/2024