Zero-Shot Fake Video Detection by Audio-Visual Consistency
2406.07854
0
0

Abstract
Recent studies have advocated the detection of fake videos as a one-class detection task, predicated on the hypothesis that the consistency between audio and visual modalities of genuine data is more significant than that of fake data. This methodology, which solely relies on genuine audio-visual data while negating the need for forged counterparts, is thus delineated as a `zero-shot' detection paradigm. This paper introduces a novel zero-shot detection approach anchored in content consistency across audio and video. By employing pre-trained ASR and VSR models, we recognize the audio and video content sequences, respectively. Then, the edit distance between the two sequences is computed to assess whether the claimed video is genuine. Experimental results indicate that, compared to two mainstream approaches based on semantic consistency and temporal consistency, our approach achieves superior generalizability across various deepfake techniques and demonstrates strong robustness against audio-visual perturbations. Finally, state-of-the-art performance gains can be achieved by simply integrating the decision scores of these three systems.
Create account to get full access
Overview
- This paper presents a novel approach for zero-shot fake video detection by leveraging audio-visual consistency.
- The proposed method aims to detect manipulated videos without requiring any prior knowledge or training data of the specific fake video generation techniques.
- The key idea is to exploit the inherent relationship between audio and visual information in genuine videos, and use this as a cue to identify inconsistencies that may indicate a fake video.
Plain English Explanation
The paper introduces a new way to detect fake videos without needing to know anything about how they were made beforehand. The main insight is that real videos have a tight connection between the audio (the sounds) and the visuals (what you see). For example, in a genuine video of someone speaking, the mouth movements should closely match the words you hear.
By analyzing this audio-visual consistency, the researchers developed a technique that can identify videos where the audio and visuals don't line up properly - a telltale sign of a fake or manipulated video. This "zero-shot" approach means it can detect fakes without being trained on examples of specific forgery techniques, like deepfakes.
The key advantage of this method is that it can generalize to catch a wide variety of fake video manipulation techniques, rather than having to be retrained for each new forgery method as they emerge. This makes it a powerful tool for combating the growing problem of deceptive media online.
Technical Explanation
The paper proposes a zero-shot fake video detection framework that exploits the inherent relationship between audio and visual modalities in genuine videos. The core idea is to leverage this audio-visual consistency as a strong cue to identify potential inconsistencies that may indicate a manipulated or fake video.
The approach involves two key components: 1) Audio-Visual Embedding, which learns a joint representation capturing the correlated patterns between audio and visual features, and 2) Audio-Visual Consistency Modeling, which assesses the degree of alignment between the audio and visual embeddings to detect potential discrepancies.
Importantly, this framework does not require any prior knowledge or training data of the specific fake video generation techniques, such as deepfakes or other forgery methods. By learning the natural audio-visual relationship in genuine videos, it can generalize to detect a wide range of manipulated content in a "zero-shot" manner.
Critical Analysis
The paper presents a compelling approach that leverages the inherent audio-visual consistency in genuine videos as a powerful cue for detecting fake or manipulated content. By not relying on specific knowledge of forgery techniques, the proposed framework has the potential to generalize well to emerging deepfake and other video manipulation methods.
However, the paper acknowledges that the approach may struggle with high-quality fakes that are able to preserve a convincing audio-visual alignment. Additionally, the experiments are limited to a specific dataset, so further evaluation on more diverse and challenging fake video benchmarks would be valuable.
It would also be interesting to explore how this zero-shot method could be combined with other audio-visual deepfake detection techniques to create a more comprehensive and robust solution for combating manipulated media in the wild.
Conclusion
This paper introduces a novel zero-shot fake video detection approach that exploits the inherent relationship between audio and visual modalities in genuine videos. By modeling audio-visual consistency, the proposed framework can identify potential discrepancies that may indicate a manipulated or fake video, without requiring any prior knowledge of the specific forgery techniques used.
This is a promising direction for building more generalizable and future-proof solutions to the growing challenge of detecting deceptive media, which will become increasingly important as video manipulation technologies continue to advance. Further research and real-world deployment of such audio-visual consistency-based detection methods could play a vital role in the ongoing battle against the spread of misinformation and deepfakes online.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
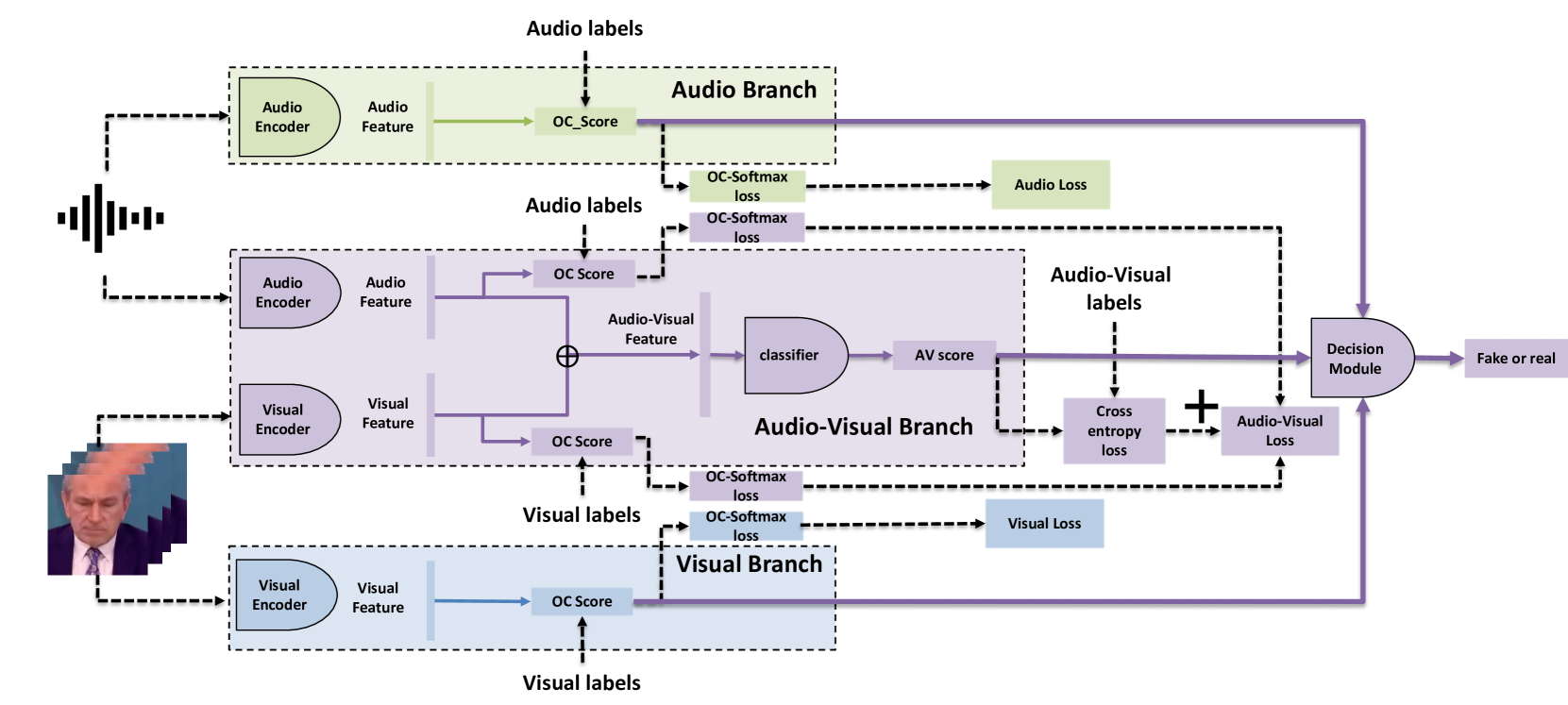
A Multi-Stream Fusion Approach with One-Class Learning for Audio-Visual Deepfake Detection
Kyungbok Lee, You Zhang, Zhiyao Duan
0
0
This paper addresses the challenge of developing a robust audio-visual deepfake detection model. In practical use cases, new generation algorithms are continually emerging, and these algorithms are not encountered during the development of detection methods. This calls for the generalization ability of the method. Additionally, to ensure the credibility of detection methods, it is beneficial for the model to interpret which cues from the video indicate it is fake. Motivated by these considerations, we then propose a multi-stream fusion approach with one-class learning as a representation-level regularization technique. We study the generalization problem of audio-visual deepfake detection by creating a new benchmark by extending and re-splitting the existing FakeAVCeleb dataset. The benchmark contains four categories of fake video(Real Audio-Fake Visual, Fake Audio-Fake Visual, Fake Audio-Real Visual, and unsynchronized video). The experimental results show that our approach improves the model's detection of unseen attacks by an average of 7.31% across four test sets, compared to the baseline model. Additionally, our proposed framework offers interpretability, indicating which modality the model identifies as fake.
6/21/2024

Visual and audio scene classification for detecting discrepancies in video: a baseline method and experimental protocol
Konstantinos Apostolidis, Jakob Abesser, Luca Cuccovillo, Vasileios Mezaris
0
0
This paper presents a baseline approach and an experimental protocol for a specific content verification problem: detecting discrepancies between the audio and video modalities in multimedia content. We first design and optimize an audio-visual scene classifier, to compare with existing classification baselines that use both modalities. Then, by applying this classifier separately to the audio and the visual modality, we can detect scene-class inconsistencies between them. To facilitate further research and provide a common evaluation platform, we introduce an experimental protocol and a benchmark dataset simulating such inconsistencies. Our approach achieves state-of-the-art results in scene classification and promising outcomes in audio-visual discrepancies detection, highlighting its potential in content verification applications.
5/2/2024
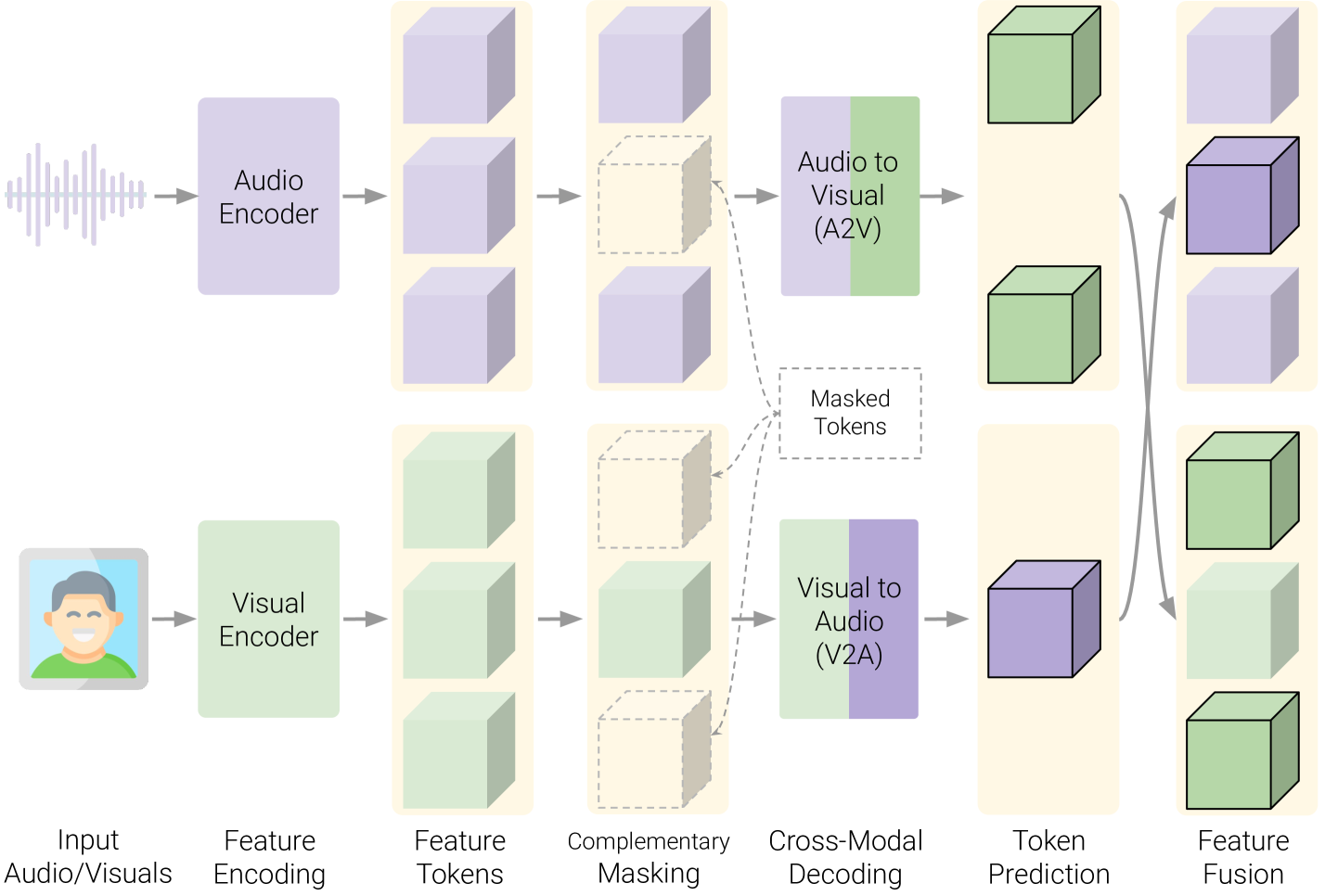
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Trevine Oorloff, Surya Koppisetti, Nicol`o Bonettini, Divyaraj Solanki, Ben Colman, Yaser Yacoob, Ali Shahriyari, Gaurav Bharaj
0
0
With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
6/6/2024
🌀
Audio Anti-Spoofing Detection: A Survey
Menglu Li, Yasaman Ahmadiadli, Xiao-Ping Zhang
0
0
The availability of smart devices leads to an exponential increase in multimedia content. However, the rapid advancements in deep learning have given rise to sophisticated algorithms capable of manipulating or creating multimedia fake content, known as Deepfake. Audio Deepfakes pose a significant threat by producing highly realistic voices, thus facilitating the spread of misinformation. To address this issue, numerous audio anti-spoofing detection challenges have been organized to foster the development of anti-spoofing countermeasures. This survey paper presents a comprehensive review of every component within the detection pipeline, including algorithm architectures, optimization techniques, application generalizability, evaluation metrics, performance comparisons, available datasets, and open-source availability. For each aspect, we conduct a systematic evaluation of the recent advancements, along with discussions on existing challenges. Additionally, we also explore emerging research topics on audio anti-spoofing, including partial spoofing detection, cross-dataset evaluation, and adversarial attack defence, while proposing some promising research directions for future work. This survey paper not only identifies the current state-of-the-art to establish strong baselines for future experiments but also guides future researchers on a clear path for understanding and enhancing the audio anti-spoofing detection mechanisms.
4/23/2024