Multi-task learning via robust regularized clustering with non-convex group penalties
2404.03250
0
0
🔗
Abstract
Multi-task learning (MTL) aims to improve estimation and prediction performance by sharing common information among related tasks. One natural assumption in MTL is that tasks are classified into clusters based on their characteristics. However, existing MTL methods based on this assumption often ignore outlier tasks that have large task-specific components or no relation to other tasks. To address this issue, we propose a novel MTL method called Multi-Task Learning via Robust Regularized Clustering (MTLRRC). MTLRRC incorporates robust regularization terms inspired by robust convex clustering, which is further extended to handle non-convex and group-sparse penalties. The extension allows MTLRRC to simultaneously perform robust task clustering and outlier task detection. The connection between the extended robust clustering and the multivariate M-estimator is also established. This provides an interpretation of the robustness of MTLRRC against outlier tasks. An efficient algorithm based on a modified alternating direction method of multipliers is developed for the estimation of the parameters. The effectiveness of MTLRRC is demonstrated through simulation studies and application to real data.
Create account to get full access
Overview
- Proposes a novel multi-task learning (MTL) method called Multi-Task Learning via Robust Regularized Clustering (MTLRRC)
- Addresses the issue of existing MTL methods ignoring outlier tasks that have large task-specific components or no relation to other tasks
- Incorporates robust regularization terms inspired by robust convex clustering, extended to handle non-convex and group-sparse penalties
- Allows MTLRRC to simultaneously perform robust task clustering and outlier task detection
- Provides an efficient algorithm based on a modified alternating direction method of multipliers for parameter estimation
Plain English Explanation
Multi-task learning (MTL) is a machine learning approach that aims to improve performance on multiple related tasks by sharing information between them. A common assumption in MTL is that tasks can be grouped into clusters based on their characteristics. However, existing MTL methods often struggle to handle tasks that are outliers, meaning they have large task-specific components or no relation to the other tasks.
The proposed MTLRRC method addresses this issue by incorporating robust regularization techniques inspired by robust convex clustering. This allows MTLRRC to simultaneously group related tasks into clusters and identify outlier tasks that don't fit well into any cluster. The method is further extended to handle non-convex and group-sparse penalties, which can capture more complex relationships between tasks.
The key idea is that by being more robust to outlier tasks, MTLRRC can better leverage the shared information between related tasks to improve overall performance, while also identifying tasks that are better handled separately. This can be especially useful in real-world applications where there may be a mix of related and unrelated tasks, such as in multi-level label correction by distilling proximate or meta-learning for generalized ridge regression in high-dimensional settings.
Technical Explanation
The proposed MTLRRC method extends existing MTL approaches by incorporating robust regularization terms inspired by robust convex clustering. This allows the method to simultaneously perform robust task clustering and outlier task detection, addressing the limitation of existing MTL methods that often ignore outlier tasks.
The key innovation is the extension of the robust clustering formulation to handle non-convex and group-sparse penalties. This allows MTLRRC to capture more complex relationships between tasks, going beyond the simple task clustering assumption made by many existing MTL methods, such as how does multi-task training affect transformer or joint task regularization for partially labeled multi-task.
The authors also establish a connection between the extended robust clustering and the multivariate M-estimator, providing an interpretation of the robustness of MTLRRC against outlier tasks. An efficient algorithm based on a modified alternating direction method of multipliers is developed for the estimation of the model parameters.
The effectiveness of MTLRRC is demonstrated through simulation studies and application to real-world data, showing improvements over existing MTL methods in handling outlier tasks and overall performance.
Critical Analysis
The paper presents a novel and promising approach to multi-task learning, addressing an important limitation of existing methods. The robust regularization and clustering formulation allow MTLRRC to identify and handle outlier tasks more effectively than previous techniques.
However, the paper does not provide a thorough discussion of the potential limitations or caveats of the proposed method. For example, it would be valuable to understand the computational complexity of the algorithm, the sensitivity of the method to hyperparameter choices, and the types of tasks or scenarios where MTLRRC might struggle to perform well.
Additionally, while the authors establish a connection between the robust clustering and the multivariate M-estimator, it's not clear how this interpretation can be leveraged in practice to further improve the method or provide insights into its behavior.
Future research could explore extensions of MTLRRC to handle more diverse task relationships, such as hierarchical or overlapping task structures, or investigate the application of the method to a wider range of real-world problems, including those with multi-level label correction by distilling proximate or meta-learning for generalized ridge regression in high-dimensional settings.
Conclusion
The proposed MTLRRC method offers a novel approach to multi-task learning that addresses the limitation of existing methods in handling outlier tasks. By incorporating robust regularization and clustering techniques, MTLRRC can simultaneously group related tasks and identify outliers, leading to improved estimation and prediction performance.
The technical innovations, including the extension to non-convex and group-sparse penalties, and the connection to the multivariate M-estimator, provide a solid theoretical foundation for the method. The demonstrated effectiveness through simulations and real-world applications suggests that MTLRRC could be a valuable tool for researchers and practitioners working on complex, multi-task learning problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
MTLComb: multi-task learning combining regression and classification tasks for joint feature selection
Han Cao, Sivanesan Rajan, Bianka Hahn, Ersoy Kocak, Daniel Durstewitz, Emanuel Schwarz, Verena Schneider-Lindner
0
0
Multi-task learning (MTL) is a learning paradigm that enables the simultaneous training of multiple communicating algorithms. Although MTL has been successfully applied to ether regression or classification tasks alone, incorporating mixed types of tasks into a unified MTL framework remains challenging, primarily due to variations in the magnitudes of losses associated with different tasks. This challenge, particularly evident in MTL applications with joint feature selection, often results in biased selections. To overcome this obstacle, we propose a provable loss weighting scheme that analytically determines the optimal weights for balancing regression and classification tasks. This scheme significantly mitigates the otherwise biased feature selection. Building upon this scheme, we introduce MTLComb, an MTL algorithm and software package encompassing optimization procedures, training protocols, and hyperparameter estimation procedures. MTLComb is designed for learning shared predictors among tasks of mixed types. To showcase the efficacy of MTLComb, we conduct tests on both simulated data and biomedical studies pertaining to sepsis and schizophrenia.
5/17/2024

Interpetable Target-Feature Aggregation for Multi-Task Learning based on Bias-Variance Analysis
Paolo Bonetti, Alberto Maria Metelli, Marcello Restelli
0
0
Multi-task learning (MTL) is a powerful machine learning paradigm designed to leverage shared knowledge across tasks to improve generalization and performance. Previous works have proposed approaches to MTL that can be divided into feature learning, focused on the identification of a common feature representation, and task clustering, where similar tasks are grouped together. In this paper, we propose an MTL approach at the intersection between task clustering and feature transformation based on a two-phase iterative aggregation of targets and features. First, we propose a bias-variance analysis for regression models with additive Gaussian noise, where we provide a general expression of the asymptotic bias and variance of a task, considering a linear regression trained on aggregated input features and an aggregated target. Then, we exploit this analysis to provide a two-phase MTL algorithm (NonLinCTFA). Firstly, this method partitions the tasks into clusters and aggregates each obtained group of targets with their mean. Then, for each aggregated task, it aggregates subsets of features with their mean in a dimensionality reduction fashion. In both phases, a key aspect is to preserve the interpretability of the reduced targets and features through the aggregation with the mean, which is further motivated by applications to Earth science. Finally, we validate the algorithms on synthetic data, showing the effect of different parameters and real-world datasets, exploring the validity of the proposed methodology on classical datasets, recent baselines, and Earth science applications.
6/13/2024

Joint-Task Regularization for Partially Labeled Multi-Task Learning
Kento Nishi, Junsik Kim, Wanhua Li, Hanspeter Pfister
0
0
Multi-task learning has become increasingly popular in the machine learning field, but its practicality is hindered by the need for large, labeled datasets. Most multi-task learning methods depend on fully labeled datasets wherein each input example is accompanied by ground-truth labels for all target tasks. Unfortunately, curating such datasets can be prohibitively expensive and impractical, especially for dense prediction tasks which require per-pixel labels for each image. With this in mind, we propose Joint-Task Regularization (JTR), an intuitive technique which leverages cross-task relations to simultaneously regularize all tasks in a single joint-task latent space to improve learning when data is not fully labeled for all tasks. JTR stands out from existing approaches in that it regularizes all tasks jointly rather than separately in pairs -- therefore, it achieves linear complexity relative to the number of tasks while previous methods scale quadratically. To demonstrate the validity of our approach, we extensively benchmark our method across a wide variety of partially labeled scenarios based on NYU-v2, Cityscapes, and Taskonomy.
4/3/2024
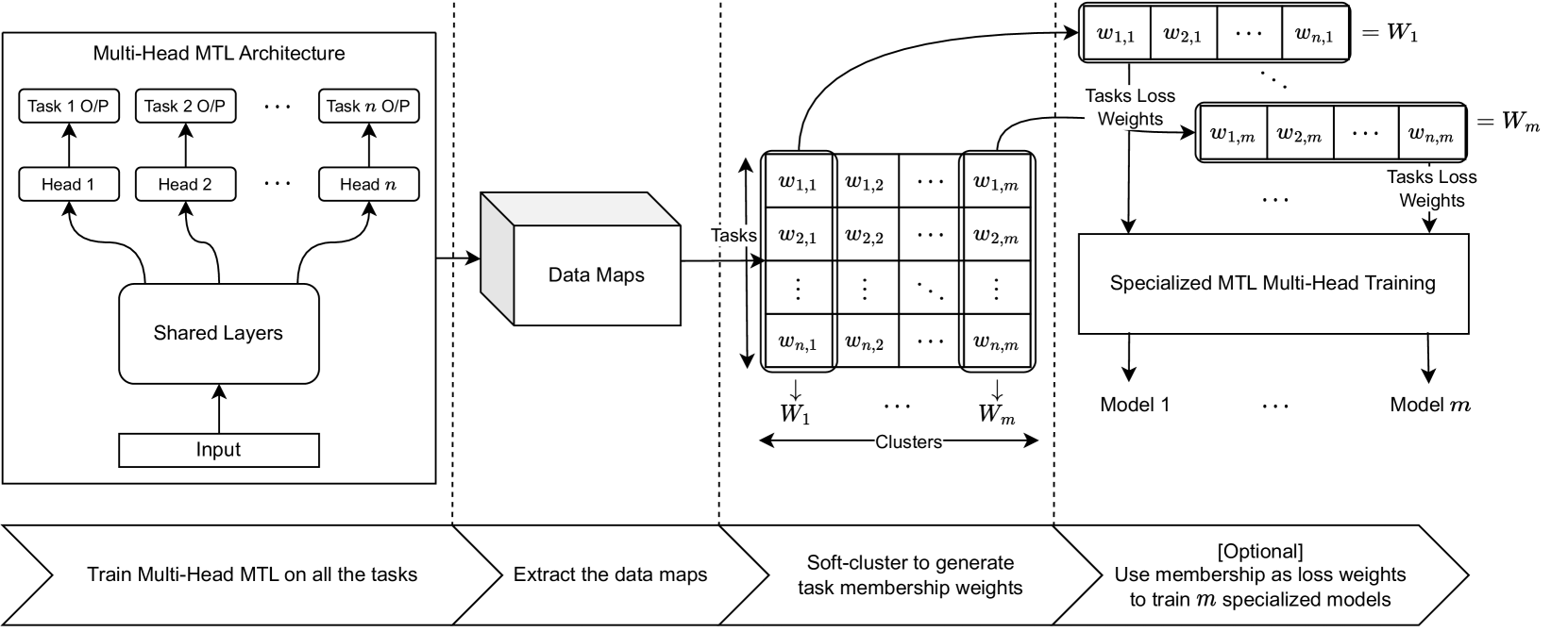
STG-MTL: Scalable Task Grouping for Multi-Task Learning Using Data Map
Ammar Sherif, Abubakar Abid, Mustafa Elattar, Mohamed ElHelw
0
0
Multi-Task Learning (MTL) is a powerful technique that has gained popularity due to its performance improvement over traditional Single-Task Learning (STL). However, MTL is often challenging because there is an exponential number of possible task groupings, which can make it difficult to choose the best one because some groupings might produce performance degradation due to negative interference between tasks. That is why existing solutions are severely suffering from scalability issues, limiting any practical application. In our paper, we propose a new data-driven method that addresses these challenges and provides a scalable and modular solution for classification task grouping based on a re-proposed data-driven features, Data Maps, which capture the training dynamics for each classification task during the MTL training. Through a theoretical comparison with other techniques, we manage to show that our approach has the superior scalability. Our experiments show a better performance and verify the method's effectiveness, even on an unprecedented number of tasks (up to 100 tasks on CIFAR100). Being the first to work on such number of tasks, our comparisons on the resulting grouping shows similar grouping to the mentioned in the dataset, CIFAR100. Finally, we provide a modular implementation for easier integration and testing, with examples from multiple datasets and tasks.
5/28/2024