A Multi-Task and Multi-Label Classification Model for Implicit Discourse Relation Recognition

0

Sign in to get full access
Overview
- This paper proposes a multi-task and multi-label classification model for recognizing implicit discourse relations.
- The model jointly learns to classify the type of discourse relation (e.g., Comparison, Condition) and the sense of the relation (e.g., Contrast, Concession) using a shared encoder.
- The authors evaluate their model on the PDTB dataset and show that it outperforms previous state-of-the-art approaches.
Plain English Explanation
The paper focuses on a common natural language processing task called implicit discourse relation recognition. This involves understanding the underlying logical connections between different parts of a text, even when those connections are not explicitly stated.
For example, consider the following two sentences:
"It was raining outside. I decided to take an umbrella."
The connection between these sentences is that the rain led the person to take an umbrella - a causal relationship. However, this relationship is not directly stated, it is implicit.
The authors' model tries to automatically detect these implicit discourse relations by jointly learning to classify both the type of relation (e.g., Comparison, Condition) and the sense of the relation (e.g., Contrast, Concession). This is done using a shared encoder that learns a common representation for both tasks.
By tackling the two tasks together, the authors show their model can outperform previous approaches that treated them separately. The results on the standard PDTB dataset demonstrate the effectiveness of their multi-task, multi-label approach.
Technical Explanation
The core of the authors' model is a shared encoder that takes in the two text segments related by an implicit discourse relation and produces a joint representation. This representation is then fed into separate classification heads to predict both the type and sense of the relation.
The type classification head uses a multi-label setup, as a given text pair can exhibit multiple types of discourse relations (e.g., Comparison and Contingency). The sense classification head uses a standard single-label setup.
The authors leverage transfer learning by first pre-training the shared encoder on a discourse parsing task, which provides the model with useful initial representations for the downstream implicit relation recognition task.
During training, the model is optimized using a multi-task loss that combines the type and sense classification objectives. This encourages the shared encoder to learn features that are useful for both tasks.
The authors' experiments on the PDTB dataset show that their multi-task, multi-label model outperforms previous state-of-the-art approaches that treated the type and sense classification as separate, independent tasks.
Critical Analysis
The authors acknowledge several limitations of their work:
- Their model only considers local discourse relations between adjacent text segments, ignoring higher-level discourse structure.
- The PDTB dataset they use has been criticized for having annotation inconsistencies, which could impact model performance.
- Their transfer learning approach relies on discourse parsing data, which may not be available for all languages or domains.
Additionally, the multi-label classification setup used for relation types could be further explored. While it allows capturing multiple relation types, it may also introduce label dependencies that the model needs to learn.
Future research could investigate cross-lingual extensions of the model, as well as ways to incorporate higher-level discourse structure into the recognition of implicit relations.
Conclusion
This paper presents a novel multi-task and multi-label classification model for the important task of implicit discourse relation recognition. By jointly learning to predict both the type and sense of these relations, the authors show their model can outperform previous state-of-the-art approaches.
While the work has some limitations, it represents an important step forward in developing more sophisticated natural language understanding capabilities, with potential applications in areas like text summarization, question answering, and dialogue systems. The insights from this research can also inform future work on discourse-aware language models and their use in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Multi-Task and Multi-Label Classification Model for Implicit Discourse Relation Recognition
Nelson Filipe Costa, Leila Kosseim
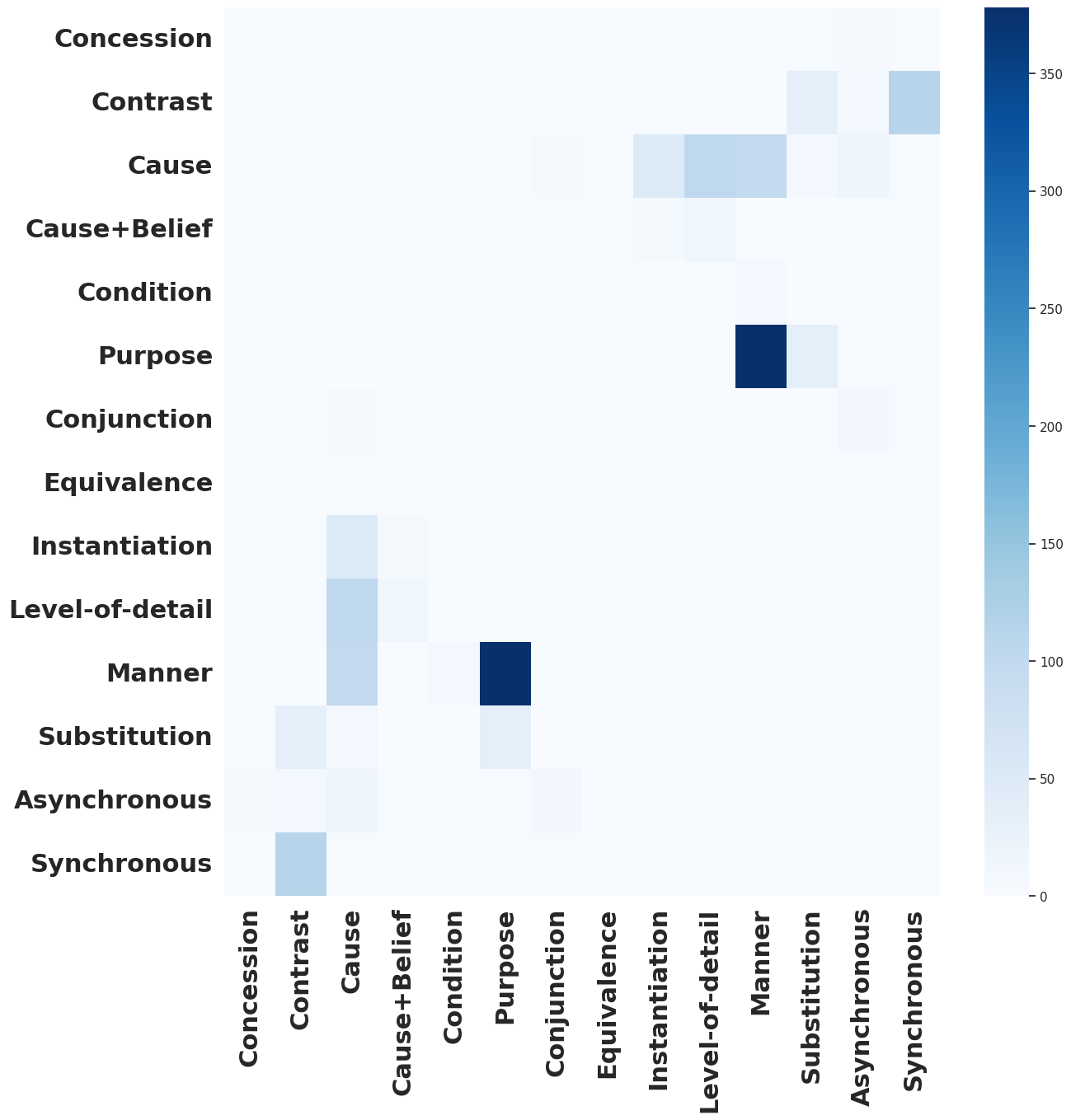
In this work, we address the inherent ambiguity in Implicit Discourse Relation Recognition (IDRR) by introducing a novel multi-task classification model capable of learning both multi-label and single-label representations of discourse relations. Leveraging the DiscoGeM corpus, we train and evaluate our model on both multi-label and traditional single-label classification tasks. To the best of our knowledge, our work presents the first truly multi-label classifier in IDRR, establishing a benchmark for multi-label classification and achieving SOTA results in single-label classification on DiscoGeM. Additionally, we evaluate our model on the PDTB 3.0 corpus for single-label classification without any prior exposure to its data. While the performance is below the current SOTA, our model demonstrates promising results indicating potential for effective transfer learning across both corpora.
Read more8/20/2024
0
Multi-Label Classification for Implicit Discourse Relation Recognition
Wanqiu Long, N. Siddharth, Bonnie Webber
Discourse relations play a pivotal role in establishing coherence within textual content, uniting sentences and clauses into a cohesive narrative. The Penn Discourse Treebank (PDTB) stands as one of the most extensively utilized datasets in this domain. In PDTB-3, the annotators can assign multiple labels to an example, when they believe that multiple relations are present. Prior research in discourse relation recognition has treated these instances as separate examples during training, and only one example needs to have its label predicted correctly for the instance to be judged as correct. However, this approach is inadequate, as it fails to account for the interdependence of labels in real-world contexts and to distinguish between cases where only one sense relation holds and cases where multiple relations hold simultaneously. In our work, we address this challenge by exploring various multi-label classification frameworks to handle implicit discourse relation recognition. We show that multi-label classification methods don't depress performance for single-label prediction. Additionally, we give comprehensive analysis of results and data. Our work contributes to advancing the understanding and application of discourse relations and provide a foundation for the future study
Read more6/10/2024

0
Implicit Discourse Relation Classification For Nigerian Pidgin
Muhammed Saeed, Peter Bourgonje, Vera Demberg
Despite attempts to make Large Language Models multi-lingual, many of the world's languages are still severely under-resourced. This widens the performance gap between NLP and AI applications aimed at well-financed, and those aimed at less-resourced languages. In this paper, we focus on Nigerian Pidgin (NP), which is spoken by nearly 100 million people, but has comparatively very few NLP resources and corpora. We address the task of Implicit Discourse Relation Classification (IDRC) and systematically compare an approach translating NP data to English and then using a well-resourced IDRC tool and back-projecting the labels versus creating a synthetic discourse corpus for NP, in which we translate PDTB and project PDTB labels, and then train an NP IDR classifier. The latter approach of learning a native NP classifier outperforms our baseline by 13.27% and 33.98% in f$_{1}$ score for 4-way and 11-way classification, respectively.
Read more6/28/2024

0
Automatic Alignment of Discourse Relations of Different Discourse Annotation Frameworks
Yingxue Fu
Existing discourse corpora are annotated based on different frameworks, which show significant dissimilarities in definitions of arguments and relations and structural constraints. Despite surface differences, these frameworks share basic understandings of discourse relations. The relationship between these frameworks has been an open research question, especially the correlation between relation inventories utilized in different frameworks. Better understanding of this question is helpful for integrating discourse theories and enabling interoperability of discourse corpora annotated under different frameworks. However, studies that explore correlations between discourse relation inventories are hindered by different criteria of discourse segmentation, and expert knowledge and manual examination are typically needed. Some semi-automatic methods have been proposed, but they rely on corpora annotated in multiple frameworks in parallel. In this paper, we introduce a fully automatic approach to address the challenges. Specifically, we extend the label-anchored contrastive learning method introduced by Zhang et al. (2022b) to learn label embeddings during a classification task. These embeddings are then utilized to map discourse relations from different frameworks. We show experimental results on RST-DT (Carlson et al., 2001) and PDTB 3.0 (Prasad et al., 2018).
Read more4/9/2024