Multi-label Cluster Discrimination for Visual Representation Learning

0

Sign in to get full access
Overview
- This paper explores a novel approach to visual representation learning called "Multi-label Cluster Discrimination" (MLCD).
- MLCD aims to learn robust and generalizable visual representations by jointly optimizing for instance-level and cluster-level discrimination tasks.
- The key idea is to leverage multi-label information to capture richer semantic associations between visual concepts, leading to more powerful representations.
Plain English Explanation
Visual representation learning is the process of training AI models to understand and extract meaningful information from images. Traditionally, this has focused on instance-level discrimination - learning to tell individual objects or images apart.
The authors of this paper argue that this approach has limitations. By only focusing on distinguishing individual instances, models may miss out on capturing the broader semantic relationships between visual concepts. To address this, the researchers propose a new technique called "Multi-label Cluster Discrimination" (MLCD).
MLCD works by training the model to not only tell individual instances apart, but also to group visually similar images into meaningful "clusters" based on their shared attributes or labels. This multi-label approach allows the model to learn richer, more generalized representations that better reflect the underlying structure of the visual world.
For example, rather than just learning to distinguish individual dogs, a model trained with MLCD would also learn to group together images of different dog breeds, understand the visual similarities between them, and connect those visual cues to higher-level semantic concepts like "canine" or "mammal."
By combining instance-level and cluster-level training objectives, MLCD aims to produce visual representations that are both discriminative (able to tell things apart) and generalizable (able to recognize broader patterns and relationships).
Technical Explanation
The core of the MLCD approach is a dual-branch neural network architecture. One branch is responsible for instance-level discrimination, learning to tell individual images apart. The other branch focuses on cluster-level discrimination, grouping visually similar images into semantically meaningful clusters based on their multi-label annotations.
The two branches are trained simultaneously using a combination of contrastive and multi-label classification losses. The instance-level branch uses a standard contrastive loss to push embeddings of the same image closer together and embeddings of different images farther apart.
The cluster-level branch leverages the multi-label annotations to group images into clusters corresponding to their shared semantic attributes. A multi-label classification loss is applied to encourage the model to accurately predict the cluster memberships of each image.
By optimizing for both instance-level and cluster-level discrimination, the model is incentivized to learn visual representations that are not only discriminative, but also capture the broader semantic relationships between visual concepts. The authors demonstrate the effectiveness of this approach through extensive experiments on standard benchmarks for visual representation learning.
Critical Analysis
The authors provide a thorough analysis of the MLCD approach, including comparisons to prior instance-level and cluster-level methods, as well as comprehensive ablation studies. They acknowledge some potential limitations, such as the reliance on multi-label annotations, which may not always be readily available.
Additionally, while the MLCD framework is shown to outperform previous state-of-the-art techniques, there is still room for improvement in terms of the absolute performance levels achieved. Exploring ways to further enhance the model's capacity to learn rich, generalizable visual representations remains an important area for future research.
It would also be valuable to investigate how MLCD could be adapted or extended to other domains beyond computer vision, such as learning representations for natural language or multi-modal tasks. Expanding the scope of this approach could unlock new opportunities for advancing representation learning more broadly.
Conclusion
This paper presents a novel visual representation learning technique called "Multi-label Cluster Discrimination" (MLCD) that jointly optimizes for instance-level and cluster-level discrimination tasks. By leveraging multi-label information, MLCD is able to capture richer semantic associations between visual concepts, leading to more powerful and generalizable representations.
The authors demonstrate the effectiveness of MLCD through extensive experiments, showcasing its advantages over previous state-of-the-art methods. While the approach has some limitations, such as the dependence on multi-label annotations, it represents an important step forward in advancing the field of visual representation learning. Further exploration of MLCD's potential applications and extensions to other domains could yield valuable insights and drive continued progress in this important area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-label Cluster Discrimination for Visual Representation Learning
Xiang An, Kaicheng Yang, Xiangzi Dai, Ziyong Feng, Jiankang Deng
Contrastive Language Image Pre-training (CLIP) has recently demonstrated success across various tasks due to superior feature representation empowered by image-text contrastive learning. However, the instance discrimination method used by CLIP can hardly encode the semantic structure of training data. To handle this limitation, cluster discrimination has been proposed through iterative cluster assignment and classification. Nevertheless, most cluster discrimination approaches only define a single pseudo-label for each image, neglecting multi-label signals in the image. In this paper, we propose a novel Multi-Label Cluster Discrimination method named MLCD to enhance representation learning. In the clustering step, we first cluster the large-scale LAION-400M dataset into one million centers based on off-the-shelf embedding features. Considering that natural images frequently contain multiple visual objects or attributes, we select the multiple closest centers as auxiliary class labels. In the discrimination step, we design a novel multi-label classification loss, which elegantly separates losses from positive classes and negative classes, and alleviates ambiguity on decision boundary. We validate the proposed multi-label cluster discrimination method with experiments on different scales of models and pre-training datasets. Experimental results show that our method achieves state-of-the-art performance on multiple downstream tasks including linear probe, zero-shot classification, and image-text retrieval.
Read more7/25/2024

0
Multimodal Multilabel Classification by CLIP
Yanming Guo
Multimodal multilabel classification (MMC) is a challenging task that aims to design a learning algorithm to handle two data sources, the image and text, and learn a comprehensive semantic feature presentation across the modalities. In this task, we review the extensive number of state-of-the-art approaches in MMC and leverage a novel technique that utilises the Contrastive Language-Image Pre-training (CLIP) as the feature extractor and fine-tune the model by exploring different classification heads, fusion methods and loss functions. Finally, our best result achieved more than 90% F_1 score in the public Kaggle competition leaderboard. This paper provides detailed descriptions of novel training methods and quantitative analysis through the experimental results.
Read more6/26/2024
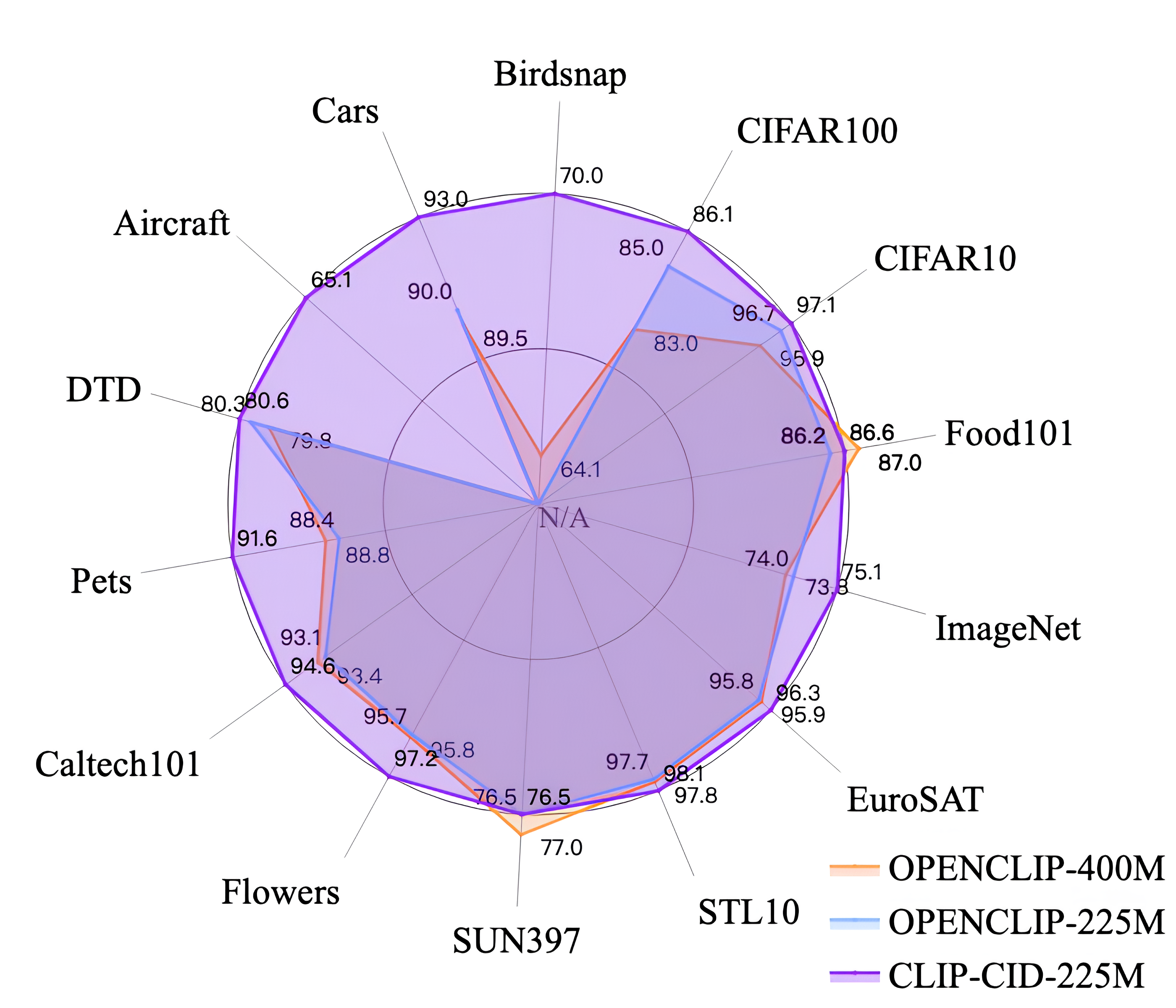
0
CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination
Kaicheng Yang, Tiancheng Gu, Xiang An, Haiqiang Jiang, Xiangzi Dai, Ziyong Feng, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has achieved excellent performance over a wide range of tasks. However, the effectiveness of CLIP heavily relies on a substantial corpus of pre-training data, resulting in notable consumption of computational resources. Although knowledge distillation has been widely applied in single modality models, how to efficiently expand knowledge distillation to vision-language foundation models with extensive data remains relatively unexplored. In this paper, we introduce CLIP-CID, a novel distillation mechanism that effectively transfers knowledge from a large vision-language foundation model to a smaller model. We initially propose a simple but efficient image semantic balance method to reduce transfer learning bias and improve distillation efficiency. This method filters out 43.7% of image-text pairs from the LAION400M while maintaining superior performance. After that, we leverage cluster-instance discrimination to facilitate knowledge transfer from the teacher model to the student model, thereby empowering the student model to acquire a holistic semantic comprehension of the pre-training data. Experimental results demonstrate that CLIP-CID achieves state-of-the-art performance on various downstream tasks including linear probe and zero-shot classification.
Read more8/20/2024

0
ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
Ahmad Sajedi, Samir Khaki, Yuri A. Lawryshyn, Konstantinos N. Plataniotis
Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
Read more4/15/2024