Multi-User Multi-Application Packet Scheduling for Application-Specific QoE Enhancement Based on Knowledge-Embedded DDPG in 6G RAN
2405.01007
0
0
➖
Abstract
The rapidly growing diversity of concurrent applications from both different users and same devices calls for application-specific Quality of Experience (QoE) enhancement of future wireless communications. Achieving this goal relies on application-specific packet scheduling, as it is vital for achieving tailored QoE enhancement by realizing the application-specific Quality of Service (QoS) requirements and for optimal perceived QoE values. However, the intertwining diversified QoE perception mechanisms, fairness among concurrent applications, and the impact of network dynamics inevitably complicate tailored packet scheduling. To achieve concurrent application-specific QoE enhancement, the problem of multi-user multi-application packet scheduling in downlink 6G radio access network (RAN) is first formulated as a Markov decision process (MDP) problem in this paper. For solving this problem, a deep deterministic policy gradient (DDPG)-based solution is proposed. However, due to the high dimensionalities of both the state and action spaces, the trained DDPG agents might generate decisions causing unnecessary resource waste. Hence, a knowledge embedding method is proposed to adjust the decisions of the DDPG agents according to human insights. Extensive experiments are conducted, which demonstrate the superiority of DDPG-based packet schedulers over baseline algorithms and the effectiveness of the proposed knowledge embedding technique.
Create account to get full access
Overview
- The paper addresses the challenge of providing application-specific Quality of Experience (QoE) enhancement in future wireless communications, which is essential as the diversity of concurrent applications and devices continues to grow.
- To achieve this, the paper formulates the problem of multi-user, multi-application packet scheduling in a 6G radio access network (RAN) as a Markov decision process (MDP).
- A deep deterministic policy gradient (DDPG)-based solution is proposed to solve this problem, but the high dimensionality of the state and action spaces can lead to unnecessary resource waste.
- To address this, the paper introduces a knowledge embedding method to adjust the DDPG agent's decisions based on human insights.
Plain English Explanation
As the number and variety of apps running on our devices continue to increase, it's becoming more important for wireless networks to be able to optimize the user experience for each specific app. This is known as Quality of Experience (QoE) enhancement. To achieve this, the network needs to be able to prioritize and schedule the data packets for each app in a way that best meets its unique requirements, a process called application-specific packet scheduling.
However, this is a complex challenge because there are many different apps running at the same time, each with its own needs, and the network conditions are constantly changing. The researchers tackled this problem by formulating it as a Markov decision process (MDP), which is a mathematical framework for modeling decision-making in uncertain environments.
They then proposed a deep reinforcement learning approach, specifically a deep deterministic policy gradient (DDPG) algorithm, to solve the MDP and make the scheduling decisions. This allows the system to learn how to optimize the QoE for each app through experience, rather than relying on pre-defined rules.
However, the researchers found that the DDPG agents could sometimes make decisions that waste network resources. To address this, they developed a "knowledge embedding" method that adjusts the DDPG agent's decisions based on insights from human experts, helping to improve the efficiency and effectiveness of the scheduling process.
Technical Explanation
The paper first formulates the problem of multi-user, multi-application packet scheduling in a 6G radio access network (RAN) as a Markov decision process (MDP). This allows the researchers to model the dynamic and uncertain nature of the wireless network environment, where the state of the system (e.g., network conditions, application requirements) and the consequences of scheduling decisions are not fully known in advance.
To solve this MDP problem, the researchers propose a deep deterministic policy gradient (DDPG) -based solution. DDPG is a type of deep reinforcement learning algorithm that can learn to make optimal decisions in complex, high-dimensional environments. In this case, the DDPG agent learns to schedule packets in a way that enhances the QoE for each concurrent application.
However, the researchers note that the high dimensionalities of both the state and action spaces in this problem can lead to the DDPG agents making decisions that result in unnecessary resource waste. To address this, they introduce a knowledge embedding method that adjusts the DDPG agent's decisions based on insights from human experts, helping to improve the efficiency and effectiveness of the scheduling process.
The researchers conduct extensive experiments to evaluate their proposed DDPG-based packet schedulers and the knowledge embedding technique. They demonstrate that the DDPG-based schedulers outperform baseline algorithms in terms of enhancing the QoE for concurrent applications, and that the knowledge embedding method further improves the performance of the DDPG agents.
Critical Analysis
The paper presents a promising approach to addressing the challenge of application-specific QoE enhancement in future wireless communications. By formulating the problem as an MDP and solving it with a DDPG-based solution, the researchers have developed a flexible and adaptive system that can learn to optimize packet scheduling for diverse and dynamic application requirements.
However, the researchers acknowledge that the high dimensionality of the state and action spaces in this problem can lead to the DDPG agents making suboptimal decisions, resulting in resource waste. While the proposed knowledge embedding method helps to mitigate this issue, it would be valuable to explore other techniques for reducing the complexity of the problem, such as hierarchical or modular reinforcement learning approaches.
Additionally, the paper does not provide a detailed analysis of the fairness and equity considerations in the packet scheduling process. As the number and diversity of concurrent applications continue to grow, it will be important to ensure that the scheduling algorithm does not unfairly prioritize certain applications or users over others.
Furthermore, the paper focuses on the downlink 6G RAN scenario, but it would be interesting to see how the proposed techniques could be extended to other wireless network architectures and use cases, such as multi-server, multi-access edge computing or joint service, caching, communication, and computing resource allocation.
Conclusion
This paper presents a novel approach to application-specific QoE enhancement in future wireless communications, which is a critical challenge as the diversity of concurrent applications and devices continues to grow. By formulating the problem as an MDP and solving it with a DDPG-based solution, the researchers have developed a flexible and adaptive system that can learn to optimize packet scheduling for diverse and dynamic application requirements.
The introduction of a knowledge embedding method to adjust the DDPG agent's decisions based on human insights is a particularly interesting contribution, as it helps to address the issue of unnecessary resource waste caused by the high dimensionality of the problem. While further research is needed to address fairness considerations and explore extensions to other wireless network architectures, this paper represents an important step forward in the quest to deliver tailored, high-quality user experiences in the era of 6G and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Novel Joint DRL-Based Utility Optimization for UAV Data Services
Xuli Cai, Poonam Lohan, Burak Kantarci
0
0
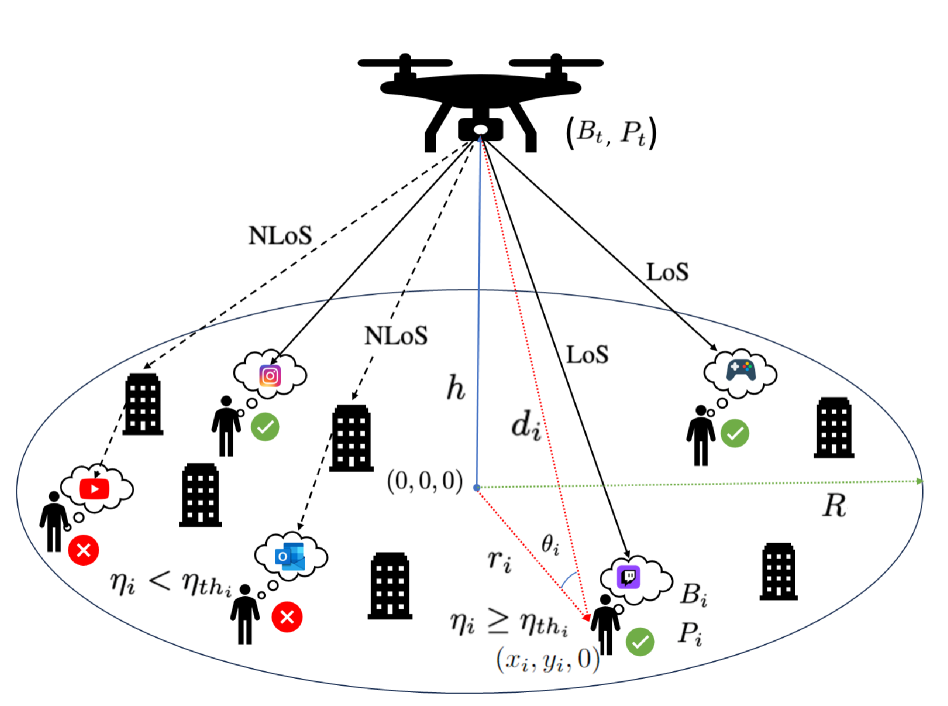
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
6/18/2024
Computation Offloading for Multi-server Multi-access Edge Vehicular Networks: A DDQN-based Method
Siyu Wang, Bo Yang, Zhiwen Yu, Xuelin Cao, Yan Zhang, Chau Yuen
0
0
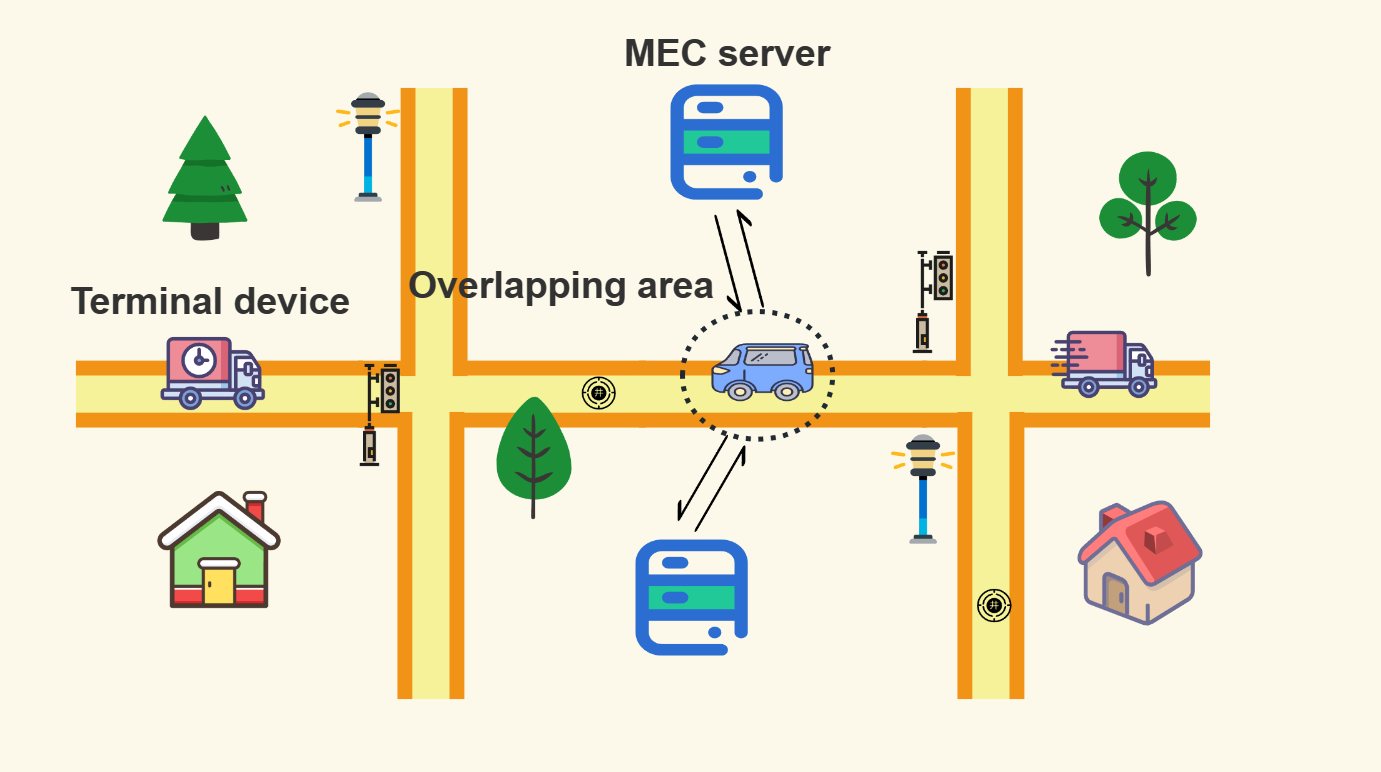
In this paper, we investigate a multi-user offloading problem in the overlapping domain of a multi-server mobile edge computing system. We divide the original problem into two stages: the offloading decision making stage and the request scheduling stage. To prevent the terminal from going out of service area during offloading, we consider the mobility parameter of the terminal according to the human behaviour model when making the offloading decision, and then introduce a server evaluation mechanism based on both the mobility parameter and the server load to select the optimal offloading server. In order to fully utilise the server resources, we design a double deep Q-network (DDQN)-based reward evaluation algorithm that considers the priority of tasks when scheduling offload requests. Finally, numerical simulations are conducted to verify that our proposed method outperforms traditional mathematical computation methods as well as the DQN algorithm.
4/12/2024
🛠️
ReinWiFi: A Reinforcement-Learning-Based Framework for the Application-Layer QoS Optimization of WiFi Networks
Qianren Li, Bojie Lv, Yuncong Hong, Rui Wang
0
0
In this paper, a reinforcement-learning-based scheduling framework is proposed and implemented to optimize the application-layer quality-of-service (QoS) of a practical wireless local area network (WLAN) suffering from unknown interference. Particularly, application-layer tasks of file delivery and delay-sensitive communication, e.g., screen projection, in a WLAN with enhanced distributed channel access (EDCA) mechanism, are jointly scheduled by adjusting the contention window sizes and application-layer throughput limitation, such that their QoS, including the throughput of file delivery and the round trip time of the delay-sensitive communication, can be optimized. Due to the unknown interference and vendor-dependent implementation of the network interface card, the relation between the scheduling policy and the system QoS is unknown. Hence, a reinforcement learning method is proposed, in which a novel Q-network is trained to map from the historical scheduling parameters and QoS observations to the current scheduling action. It is demonstrated on a testbed that the proposed framework can achieve a significantly better QoS than the conventional EDCA mechanism.
5/7/2024
🤔
Joint Service Caching, Communication and Computing Resource Allocation in Collaborative MEC Systems: A DRL-based Two-timescale Approach
Qianqian Liu, Haixia Zhang, Xin Zhang, Dongfeng Yuan
0
0
Meeting the strict Quality of Service (QoS) requirements of terminals has imposed a signiffcant challenge on Multiaccess Edge Computing (MEC) systems, due to the limited multidimensional resources. To address this challenge, we propose a collaborative MEC framework that facilitates resource sharing between the edge servers, and with the aim to maximize the long-term QoS and reduce the cache switching cost through joint optimization of service caching, collaborative offfoading, and computation and communication resource allocation. The dual timescale feature and temporal recurrence relationship between service caching and other resource allocation make solving the problem even more challenging. To solve it, we propose a deep reinforcement learning (DRL)-based dual timescale scheme, called DGL-DDPG, which is composed of a short-term genetic algorithm (GA) and a long short-term memory network-based deep deterministic policy gradient (LSTM-DDPG). In doing so, we reformulate the optimization problem as a Markov decision process (MDP) where the small-timescale resource allocation decisions generated by an improved GA are taken as the states and input into a centralized LSTM-DDPG agent to generate the service caching decision for the large-timescale. Simulation results demonstrate that our proposed algorithm outperforms the baseline algorithms in terms of the average QoS and cache switching cost.
4/29/2024