ReinWiFi: A Reinforcement-Learning-Based Framework for the Application-Layer QoS Optimization of WiFi Networks
2405.03526
0
0
🛠️
Abstract
In this paper, a reinforcement-learning-based scheduling framework is proposed and implemented to optimize the application-layer quality-of-service (QoS) of a practical wireless local area network (WLAN) suffering from unknown interference. Particularly, application-layer tasks of file delivery and delay-sensitive communication, e.g., screen projection, in a WLAN with enhanced distributed channel access (EDCA) mechanism, are jointly scheduled by adjusting the contention window sizes and application-layer throughput limitation, such that their QoS, including the throughput of file delivery and the round trip time of the delay-sensitive communication, can be optimized. Due to the unknown interference and vendor-dependent implementation of the network interface card, the relation between the scheduling policy and the system QoS is unknown. Hence, a reinforcement learning method is proposed, in which a novel Q-network is trained to map from the historical scheduling parameters and QoS observations to the current scheduling action. It is demonstrated on a testbed that the proposed framework can achieve a significantly better QoS than the conventional EDCA mechanism.
Create account to get full access
Overview
- Proposes a reinforcement-learning-based scheduling framework to optimize quality-of-service (QoS) in a wireless local area network (WLAN) with unknown interference
- Jointly schedules application-layer tasks like file delivery and delay-sensitive communication (e.g., screen projection)
- Uses reinforcement learning to learn the relationship between scheduling parameters and system QoS
Plain English Explanation
The paper describes a new way to manage wireless networks that are experiencing interference from unknown sources. Wireless networks often have different types of traffic, like file downloads and video calls. The researchers developed a system that uses reinforcement learning to automatically adjust the network settings to provide the best quality of service (QoS) for these various applications.
Normally, it's hard to know how to best configure the network because the interference from other devices is unpredictable. The researchers' approach uses a neural network to learn the relationship between the network settings and the actual performance that users experience. By continuously observing the network and adjusting the settings, the system can optimize the QoS without needing to understand all the details of how the interference is affecting the network.
The researchers tested their framework on a real wireless network testbed and showed that it could achieve significantly better QoS than the standard network management approach. This suggests the reinforcement learning technique is a promising way to intelligently manage wireless networks in the face of unknown disturbances.
Technical Explanation
The paper proposes a reinforcement-learning-based scheduling framework to optimize the application-layer quality-of-service (QoS) in a wireless local area network (WLAN) with unknown interference.
The framework jointly schedules application-layer tasks like file delivery and delay-sensitive communication (e.g., screen projection) by adjusting the contention window sizes and application-layer throughput limitation. This allows the system to optimize the QoS metrics, such as file delivery throughput and round-trip time for delay-sensitive traffic.
Since the relationship between the scheduling policy and system QoS is unknown due to the unpredictable interference and vendor-dependent network card implementation, the researchers use a reinforcement learning approach. Specifically, they train a novel Q-network to map from the historical scheduling parameters and QoS observations to the current scheduling action.
Experiments on a real WLAN testbed show that the proposed framework can achieve significantly better QoS than the conventional EDCA mechanism, which does not adapt to the unknown interference.
Critical Analysis
The paper presents a promising approach to improving QoS in wireless networks facing unknown interference. The use of reinforcement learning to adaptively optimize the scheduling policy is an interesting solution to this challenging problem.
One potential limitation is that the framework was only evaluated on a single testbed, so its performance may vary depending on the specific network conditions and interference patterns. Further testing in diverse real-world environments would help validate the generalizability of the approach.
Additionally, the paper does not provide much detail on the training process for the Q-network or the specific reward function used. More information on these aspects would help readers better understand the inner workings of the framework and how it could be further improved or extended.
Overall, this research demonstrates the potential of reinforcement learning techniques to adaptively manage wireless networks in the face of unpredictable interference. Further development and rigorous evaluation of such approaches could lead to significant advancements in wireless network optimization.
Conclusion
This paper presents a novel reinforcement-learning-based scheduling framework that can effectively optimize application-layer quality-of-service in a wireless local area network with unknown interference. By jointly scheduling different types of traffic and adapting the scheduling policy through continuous learning, the framework is able to outperform conventional static network management approaches.
The research highlights the value of using adaptive, data-driven techniques like reinforcement learning to tackle complex networking challenges. As wireless technologies continue to evolve and face new interference challenges, this type of intelligent, self-optimizing approach may become increasingly important for ensuring reliable and high-quality wireless service.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Reinforcement-Learning based routing for packet-optical networks with hybrid telemetry
A. L. Garc'ia Navarro, Nataliia Koneva, Alfonso S'anchez-Maci'an, Jos'e Alberto Hern'andez, 'Oscar Gonz'alez de Dios, J. M. Rivas-Moscoso
0
0
This article provides a methodology and open-source implementation of Reinforcement Learning algorithms for finding optimal routes in a packet-optical network scenario. The algorithm uses measurements provided by the physical layer (pre-FEC bit error rate and propagation delay) and the link layer (link load) to configure a set of latency-based rewards and penalties based on such measurements. Then, the algorithm executes Q-learning based on this set of rewards for finding the optimal routing strategies. It is further shown that the algorithm dynamically adapts to changing network conditions by re-calculating optimal policies upon either link load changes or link degradation as measured by pre-FEC BER.
6/24/2024

Online Frequency Scheduling by Learning Parallel Actions
Anastasios Giovanidis, Mathieu Leconte, Sabrine Aroua, Tor Kvernvik, David Sandberg
0
0
Radio Resource Management is a challenging topic in future 6G networks where novel applications create strong competition among the users for the available resources. In this work we consider the frequency scheduling problem in a multi-user MIMO system. Frequency resources need to be assigned to a set of users while allowing for concurrent transmissions in the same sub-band. Traditional methods are insufficient to cope with all the involved constraints and uncertainties, whereas reinforcement learning can directly learn near-optimal solutions for such complex environments. However, the scheduling problem has an enormous action space accounting for all the combinations of users and sub-bands, so out-of-the-box algorithms cannot be used directly. In this work, we propose a scheduler based on action-branching over sub-bands, which is a deep Q-learning architecture with parallel decision capabilities. The sub-bands learn correlated but local decision policies and altogether they optimize a global reward. To improve the scaling of the architecture with the number of sub-bands, we propose variations (Unibranch, Graph Neural Network-based) that reduce the number of parameters to learn. The parallel decision making of the proposed architecture allows to meet short inference time requirements in real systems. Furthermore, the deep Q-learning approach permits online fine-tuning after deployment to bridge the sim-to-real gap. The proposed architectures are evaluated against relevant baselines from the literature showing competitive performance and possibilities of online adaptation to evolving environments.
6/10/2024
🏅
Dynamic Inhomogeneous Quantum Resource Scheduling with Reinforcement Learning
Linsen Li, Pratyush Anand, Kaiming He, Dirk Englund
0
0
A central challenge in quantum information science and technology is achieving real-time estimation and feedforward control of quantum systems. This challenge is compounded by the inherent inhomogeneity of quantum resources, such as qubit properties and controls, and their intrinsically probabilistic nature. This leads to stochastic challenges in error detection and probabilistic outcomes in processes such as heralded remote entanglement. Given these complexities, optimizing the construction of quantum resource states is an NP-hard problem. In this paper, we address the quantum resource scheduling issue by formulating the problem and simulating it within a digitized environment, allowing the exploration and development of agent-based optimization strategies. We employ reinforcement learning agents within this probabilistic setting and introduce a new framework utilizing a Transformer model that emphasizes self-attention mechanisms for pairs of qubits. This approach facilitates dynamic scheduling by providing real-time, next-step guidance. Our method significantly improves the performance of quantum systems, achieving more than a 3$times$ improvement over rule-based agents, and establishes an innovative framework that improves the joint design of physical and control systems for quantum applications in communication, networking, and computing.
5/28/2024
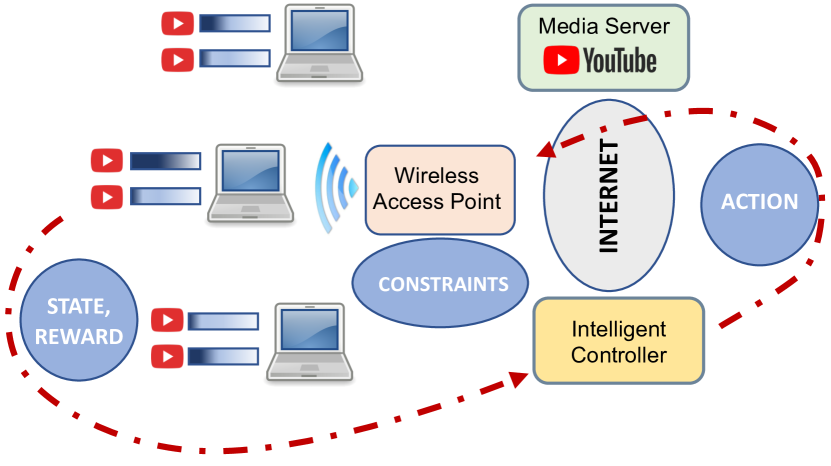
Structured Reinforcement Learning for Media Streaming at the Wireless Edge
Archana Bura, Sarat Chandra Bobbili, Shreyas Rameshkumar, Desik Rengarajan, Dileep Kalathil, Srinivas Shakkottai
0
0
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
4/12/2024