MultiBooth: Towards Generating All Your Concepts in an Image from Text

0

Sign in to get full access
Overview
- The paper introduces "MultiBooth", a system for generating multiple concepts in a single image from text input.
- It addresses the challenge of creating personalized images that incorporate multiple user-specified elements.
- The approach builds on recent advancements in text-to-image generation and aims to enable fine-grained control over the generated content.
Plain English Explanation
The paper presents a new tool called "MultiBooth" that can create images based on text descriptions provided by the user. Unlike previous text-to-image systems that generate a single image, MultiBooth allows users to specify multiple concepts or elements they want to see in the final image.
For example, a user could ask MultiBooth to generate an image of a "colorful abstract cityscape with a hot air balloon and a dog." The system would then try to incorporate all of those elements - the cityscape, hot air balloon, and dog - into a single cohesive image. This gives users much more control and customization over the generated output compared to standard text-to-image models.
The key innovation of MultiBooth is its ability to fuse together multiple user-defined concepts into a coherent visual representation. This builds on recent breakthroughs in text-to-image synthesis and multi-concept guidance to enable a new level of personalized image generation.
Technical Explanation
The MultiBooth system takes a text prompt as input, which can include multiple concepts the user wants to see in the final image. The model then learns to generate an image that seamlessly combines those specified elements.
This is accomplished through a novel multi-task training approach. The model is trained to not only generate the overall image, but also individual segmentation masks corresponding to each of the requested concepts. This allows the system to reason about how to properly integrate the different elements into a cohesive whole.
The authors also introduce techniques for concept weighting and text-guided style transfer to further enhance the level of customization and control the user has over the generated image.
Experiments demonstrate that MultiBooth significantly outperforms previous text-to-image models in its ability to faithfully represent multiple user-specified concepts within a single output image. The authors also show how the system can be extended to handle more complex, text-rich image generation tasks.
Critical Analysis
The key strength of MultiBooth is its ability to generate personalized images that capture the specific elements a user wants to see. This addresses an important limitation of prior text-to-image models, which could only produce a single, generic image from the input text.
However, the paper acknowledges that MultiBooth still has room for improvement in terms of overall image quality and coherence when handling complex, multi-concept prompts. The segmentation-based approach can sometimes lead to visible seams or artifacts between the different elements.
Additionally, the experiments are limited to a relatively narrow domain of image generation tasks. It remains to be seen how well MultiBooth would scale to more open-ended or abstract text prompts that don't have a clear visual mapping.
Further research could explore ways to better integrate the various user-specified concepts, perhaps through more sophisticated multi-modal reasoning or generative techniques. Expanding the model's capabilities to handle a wider range of text inputs and generation tasks would also be valuable.
Conclusion
The MultiBooth system represents an important step forward in text-to-image generation, enabling users to customize the output by specifying multiple desired concepts. This addresses a key limitation of existing models and opens up new possibilities for personalized, interactive image creation.
While the current implementation has some room for improvement, the core ideas behind MultiBooth - multi-task training, concept weighting, and text-guided style transfer - demonstrate the potential for AI systems to become more responsive to users' specific visual needs and preferences. As the field of text-to-image generation continues to advance, tools like MultiBooth may play an increasingly central role in how people create, interact with, and share digital imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MultiBooth: Towards Generating All Your Concepts in an Image from Text
Chenyang Zhu, Kai Li, Yue Ma, Chunming He, Li Xiu
This paper introduces MultiBooth, a novel and efficient technique for multi-concept customization in image generation from text. Despite the significant advancements in customized generation methods, particularly with the success of diffusion models, existing methods often struggle with multi-concept scenarios due to low concept fidelity and high inference cost. MultiBooth addresses these issues by dividing the multi-concept generation process into two phases: a single-concept learning phase and a multi-concept integration phase. During the single-concept learning phase, we employ a multi-modal image encoder and an efficient concept encoding technique to learn a concise and discriminative representation for each concept. In the multi-concept integration phase, we use bounding boxes to define the generation area for each concept within the cross-attention map. This method enables the creation of individual concepts within their specified regions, thereby facilitating the formation of multi-concept images. This strategy not only improves concept fidelity but also reduces additional inference cost. MultiBooth surpasses various baselines in both qualitative and quantitative evaluations, showcasing its superior performance and computational efficiency. Project Page: https://multibooth.github.io/
Read more4/23/2024

0
AttnDreamBooth: Towards Text-Aligned Personalized Text-to-Image Generation
Lianyu Pang, Jian Yin, Baoquan Zhao, Feize Wu, Fu Lee Wang, Qing Li, Xudong Mao
Recent advances in text-to-image models have enabled high-quality personalized image synthesis of user-provided concepts with flexible textual control. In this work, we analyze the limitations of two primary techniques in text-to-image personalization: Textual Inversion and DreamBooth. When integrating the learned concept into new prompts, Textual Inversion tends to overfit the concept, while DreamBooth often overlooks it. We attribute these issues to the incorrect learning of the embedding alignment for the concept. We introduce AttnDreamBooth, a novel approach that addresses these issues by separately learning the embedding alignment, the attention map, and the subject identity in different training stages. We also introduce a cross-attention map regularization term to enhance the learning of the attention map. Our method demonstrates significant improvements in identity preservation and text alignment compared to the baseline methods.
Read more6/10/2024

0
MotionBooth: Motion-Aware Customized Text-to-Video Generation
Jianzong Wu, Xiangtai Li, Yanhong Zeng, Jiangning Zhang, Qianyu Zhou, Yining Li, Yunhai Tong, Kai Chen
In this work, we present MotionBooth, an innovative framework designed for animating customized subjects with precise control over both object and camera movements. By leveraging a few images of a specific object, we efficiently fine-tune a text-to-video model to capture the object's shape and attributes accurately. Our approach presents subject region loss and video preservation loss to enhance the subject's learning performance, along with a subject token cross-attention loss to integrate the customized subject with motion control signals. Additionally, we propose training-free techniques for managing subject and camera motions during inference. In particular, we utilize cross-attention map manipulation to govern subject motion and introduce a novel latent shift module for camera movement control as well. MotionBooth excels in preserving the appearance of subjects while simultaneously controlling the motions in generated videos. Extensive quantitative and qualitative evaluations demonstrate the superiority and effectiveness of our method. Our project page is at https://jianzongwu.github.io/projects/motionbooth
Read more8/22/2024
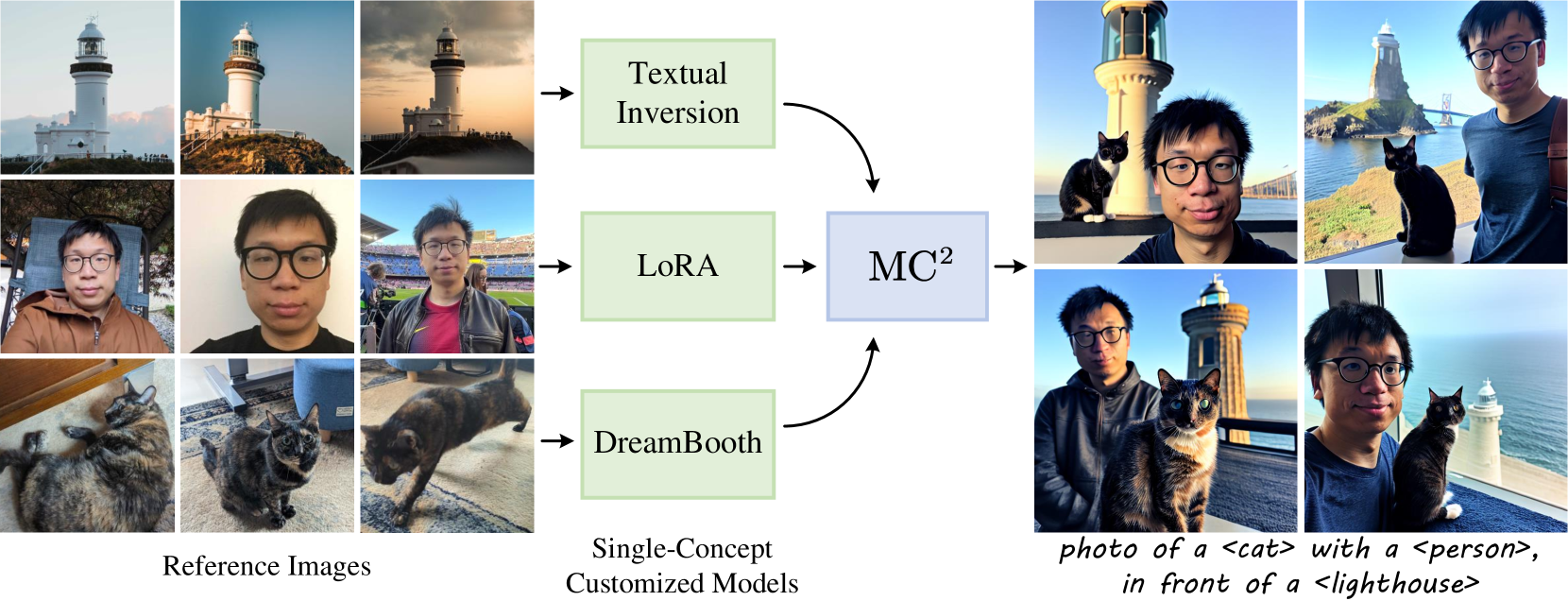
0
MC$^2$: Multi-concept Guidance for Customized Multi-concept Generation
Jiaxiu Jiang, Yabo Zhang, Kailai Feng, Xiaohe Wu, Wangmeng Zuo
Customized text-to-image generation aims to synthesize instantiations of user-specified concepts and has achieved unprecedented progress in handling individual concept. However, when extending to multiple customized concepts, existing methods exhibit limitations in terms of flexibility and fidelity, only accommodating the combination of limited types of models and potentially resulting in a mix of characteristics from different concepts. In this paper, we introduce the Multi-concept guidance for Multi-concept customization, termed MC$^2$, for improved flexibility and fidelity. MC$^2$ decouples the requirements for model architecture via inference time optimization, allowing the integration of various heterogeneous single-concept customized models. It adaptively refines the attention weights between visual and textual tokens, directing image regions to focus on their associated words while diminishing the impact of irrelevant ones. Extensive experiments demonstrate that MC$^2$ even surpasses previous methods that require additional training in terms of consistency with input prompt and reference images. Moreover, MC$^2$ can be extended to elevate the compositional capabilities of text-to-image generation, yielding appealing results. Code will be publicly available at https://github.com/JIANGJiaXiu/MC-2.
Read more4/15/2024