MultiDiff: Consistent Novel View Synthesis from a Single Image
2406.18524
0
0

Abstract
We introduce MultiDiff, a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature, as there exist multiple, plausible explanations for unobserved areas. To address this issue, we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views, increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes, allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation, MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results -- even for long-term scene generation with large camera movements, while reducing inference time by an order of magnitude. For additional consistency and image quality improvements, we introduce a novel, structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging, real-world datasets RealEstate10K and ScanNet. Finally, our model naturally supports multi-view consistent editing without the need for further tuning.
Create account to get full access
Overview
- This paper introduces a novel diffusion-based model called MultiDiff that can generate consistent novel views of an object from a single input image.
- The model learns to capture the underlying 3D geometry and appearance of the object, allowing it to synthesize multiple consistent views of the same object from different perspectives.
- This approach addresses the challenge of generating high-quality, multi-view consistent images from a single input, which is crucial for applications like AR/VR, robotics, and 3D content creation.
Plain English Explanation
MultiDiff is a new AI model that can take a single image of an object and generate multiple, consistent views of that object from different angles. This is an important capability because it allows for the creation of 3D content and immersive experiences, such as augmented reality (AR) or virtual reality (VR), from a single input.
The key idea behind MultiDiff is that it learns to understand the underlying 3D geometry and appearance of the object in the input image. This allows the model to synthesize novel views of the object that are coherent and realistic, as if the object were being viewed from different perspectives. This is a challenging task because the model needs to maintain the object's identity, shape, and texture across the generated views.
MultiDiff addresses this challenge using a diffusion-based approach, which is a type of machine learning model that can generate high-quality, realistic images. By combining this diffusion-based approach with techniques for capturing 3D information, the researchers were able to develop a system that can create consistent, multi-view renderings of objects from a single input image.
This capability has many potential applications, such as in robotics, where a robot might need to understand the 3D structure of an object to interact with it, or in 3D content creation, where artists and designers could use MultiDiff to quickly generate multiple views of a 3D object from a single photograph.
Technical Explanation
The core idea behind MultiDiff is to leverage diffusion-based models, which have shown impressive results in generating high-quality, realistic images, and combine them with techniques for capturing 3D information from a single input image.
The architecture of MultiDiff consists of several key components:
- Encoder: This part of the model takes the input image and encodes it into a latent representation that captures the 3D geometry and appearance of the object.
- Diffusion Module: This module uses a diffusion-based approach to generate multiple, consistent views of the object from the latent representation. The diffusion process gradually adds noise to the latent representation and then learns to reverse this process to generate the novel views.
- Renderer: The final component of MultiDiff is a renderer that takes the generated novel views and produces the final output images.
The researchers trained MultiDiff on a dataset of 3D objects and their corresponding 2D images, which allowed the model to learn the relationship between the 3D geometry and 2D appearance. During inference, the model can take a single input image and generate multiple, consistent views of the object from different perspectives.
The key innovation of MultiDiff is its ability to capture the underlying 3D structure of the object, which enables it to generate coherent and realistic novel views. This is achieved through the use of SyncDreamer, a technique for learning a consistent latent representation across multiple views, and MVDiffusion, a multi-view diffusion model that can generate high-resolution, multi-view consistent images.
Critical Analysis
The researchers have demonstrated the effectiveness of MultiDiff in generating consistent novel views of objects from a single input image. The model is able to maintain the identity, shape, and texture of the object across the generated views, which is a significant achievement.
However, the paper does not address some potential limitations and areas for further research:
- Generalization to Real-World Scenes: The experiments in the paper focus on generating novel views of isolated 3D objects. It's unclear how well the model would perform on more complex, real-world scenes with multiple objects and occlusions.
- Handling Uncertainty: The diffusion-based approach used in MultiDiff may not be able to capture the inherent uncertainty in the 3D geometry and appearance of an object, which could lead to suboptimal novel view synthesis.
- Computational Efficiency: The iterative nature of the diffusion process may make MultiDiff computationally expensive, which could limit its practical applications, especially in real-time scenarios.
Further research could explore ways to address these limitations, such as by incorporating techniques for scene understanding or uncertainty modeling, or by exploring more efficient diffusion-based architectures.
Conclusion
The MultiDiff model presented in this paper is a significant advance in the field of novel view synthesis. By leveraging diffusion-based techniques and 3D representation learning, the model is able to generate consistent, multi-view renderings of objects from a single input image.
This capability has important applications in areas like AR/VR, robotics, and 3D content creation, where the ability to understand and visualize the 3D structure of objects is crucial. While the current implementation of MultiDiff has some limitations, the paper demonstrates the potential of this approach and opens up avenues for further research and development in this exciting field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
0
0
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
6/3/2024
🖼️
SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, Wenping Wang
0
0
In this paper, we present a novel diffusion model called that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
4/16/2024
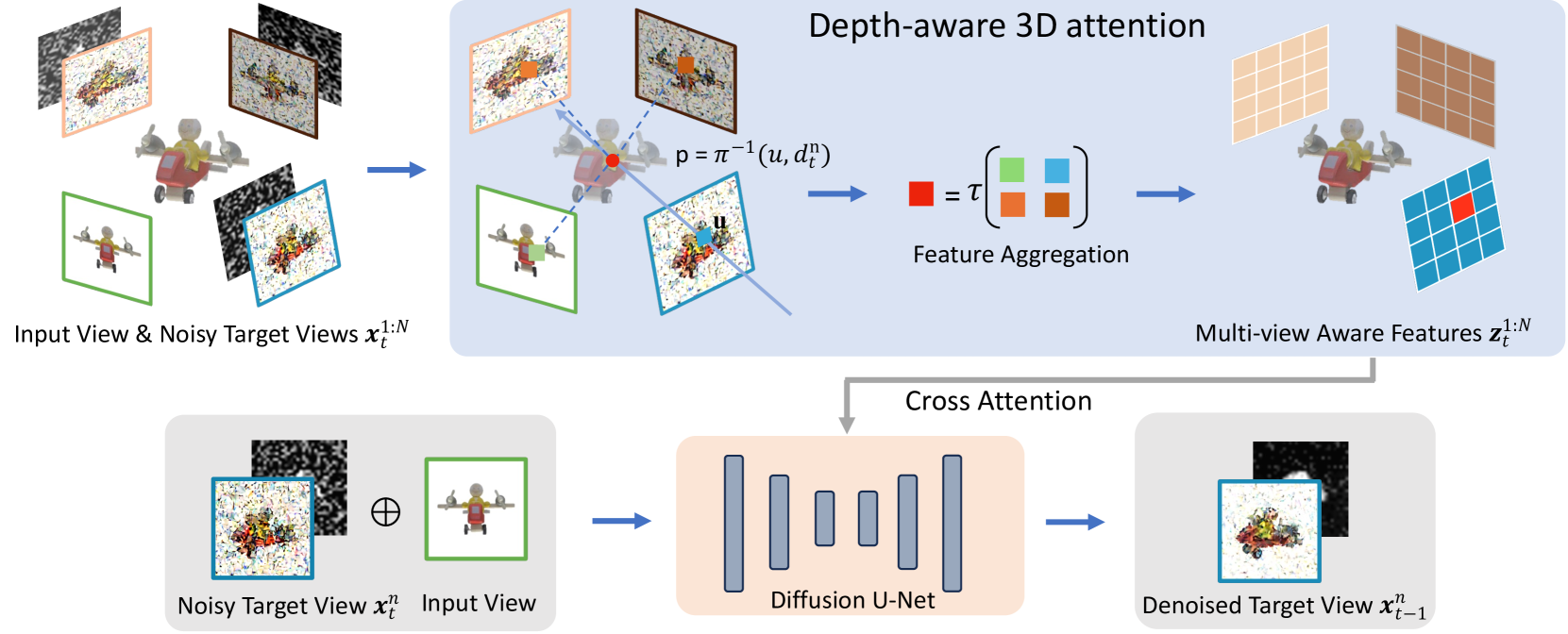
MVD-Fusion: Single-view 3D via Depth-consistent Multi-view Generation
Hanzhe Hu, Zhizhuo Zhou, Varun Jampani, Shubham Tulsiani
0
0
We present MVD-Fusion: a method for single-view 3D inference via generative modeling of multi-view-consistent RGB-D images. While recent methods pursuing 3D inference advocate learning novel-view generative models, these generations are not 3D-consistent and require a distillation process to generate a 3D output. We instead cast the task of 3D inference as directly generating mutually-consistent multiple views and build on the insight that additionally inferring depth can provide a mechanism for enforcing this consistency. Specifically, we train a denoising diffusion model to generate multi-view RGB-D images given a single RGB input image and leverage the (intermediate noisy) depth estimates to obtain reprojection-based conditioning to maintain multi-view consistency. We train our model using large-scale synthetic dataset Obajverse as well as the real-world CO3D dataset comprising of generic camera viewpoints. We demonstrate that our approach can yield more accurate synthesis compared to recent state-of-the-art, including distillation-based 3D inference and prior multi-view generation methods. We also evaluate the geometry induced by our multi-view depth prediction and find that it yields a more accurate representation than other direct 3D inference approaches.
4/5/2024