SyncDreamer: Generating Multiview-consistent Images from a Single-view Image
2309.03453
0
0
🖼️
Abstract
In this paper, we present a novel diffusion model called that generates multiview-consistent images from a single-view image. Using pretrained large-scale 2D diffusion models, recent work Zero123 demonstrates the ability to generate plausible novel views from a single-view image of an object. However, maintaining consistency in geometry and colors for the generated images remains a challenge. To address this issue, we propose a synchronized multiview diffusion model that models the joint probability distribution of multiview images, enabling the generation of multiview-consistent images in a single reverse process. SyncDreamer synchronizes the intermediate states of all the generated images at every step of the reverse process through a 3D-aware feature attention mechanism that correlates the corresponding features across different views. Experiments show that SyncDreamer generates images with high consistency across different views, thus making it well-suited for various 3D generation tasks such as novel-view-synthesis, text-to-3D, and image-to-3D.
Create account to get full access
Overview
- This paper introduces a novel diffusion model called SyncDreamer that generates multi-view consistent images from a single-view image.
- Recent work like Zero123 has shown the ability to generate plausible novel views from a single-view image, but maintaining consistency in geometry and colors remains a challenge.
- SyncDreamer addresses this by modeling the joint probability distribution of multi-view images, enabling the generation of multi-view consistent images in a single reverse process.
Plain English Explanation
SyncDreamer is a new type of AI model that can take a single image of an object and generate a set of consistent images from different viewpoints. Previous models like Zero123 could generate new views, but the images would sometimes have inconsistencies in the geometry or colors.
SyncDreamer avoids this by modeling the relationships between the different viewpoints all at once. It learns how the object should look from multiple angles, so when it generates the new views, they seamlessly fit together. This makes SyncDreamer well-suited for tasks like generating 3D scenes from text or single images, since the different views will be properly aligned.
The key innovation is a "3D-aware feature attention" mechanism that coordinates the intermediate states of the generated images at each step. This helps the model understand how the features in one view correspond to the features in the other views, ensuring consistent geometry and colors.
Technical Explanation
SyncDreamer builds on recent work in diffusion models, which are a type of generative AI that can create new images by starting with noise and gradually refining it. The paper uses pre-trained 2D diffusion models as a starting point, and then introduces a novel architecture and training process to enable multi-view consistent image generation.
The core of SyncDreamer is a 3D-aware feature attention mechanism that correlates the corresponding features across different views during the reverse diffusion process. This ensures that the intermediate states of the generated images are synchronized, leading to the final outputs having high consistency in terms of geometry, colors, and other visual properties.
Experiments show that SyncDreamer outperforms previous single-to-multi-view generation methods, both in terms of view consistency and visual quality. The model is demonstrated on tasks like novel view synthesis, text-to-3D, and image-to-3D, highlighting its versatility and potential applications.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of generating multi-view consistent images from a single input. The 3D-aware feature attention mechanism is a clever solution to coordinate the generation process across different viewpoints.
However, the paper does not deeply explore the limitations of the approach. For example, it's unclear how SyncDreamer would perform on more complex 3D scenes with occlusions, or how the model's performance scales with the number of views. Additionally, the paper doesn't discuss potential biases or artifacts that may arise in the generated images.
Further research could investigate techniques to rethink iterative stereo matching from diffusion or explore ways to boost 3D generation through multi-view approaches. Comparing SyncDreamer to other multi-view generation methods, such as DiffusionDollar2Dollar or RealMDreamer, could also provide valuable insights.
Conclusion
SyncDreamer represents an important step forward in the field of multi-view image generation. By modeling the joint probability distribution of multi-view images and leveraging a 3D-aware feature attention mechanism, the model is able to generate visually consistent images from a single input view. This capability has significant implications for applications such as novel view synthesis, text-to-3D, and image-to-3D generation, where maintaining coherence across viewpoints is crucial.
While the paper leaves room for further exploration of the model's limitations and potential enhancements, SyncDreamer demonstrates the power of diffusion-based approaches for tackling challenging 3D-related tasks. As the field of generative AI continues to evolve, innovative techniques like those presented in this work will likely play an increasingly important role in pushing the boundaries of what's possible in 3D content creation and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
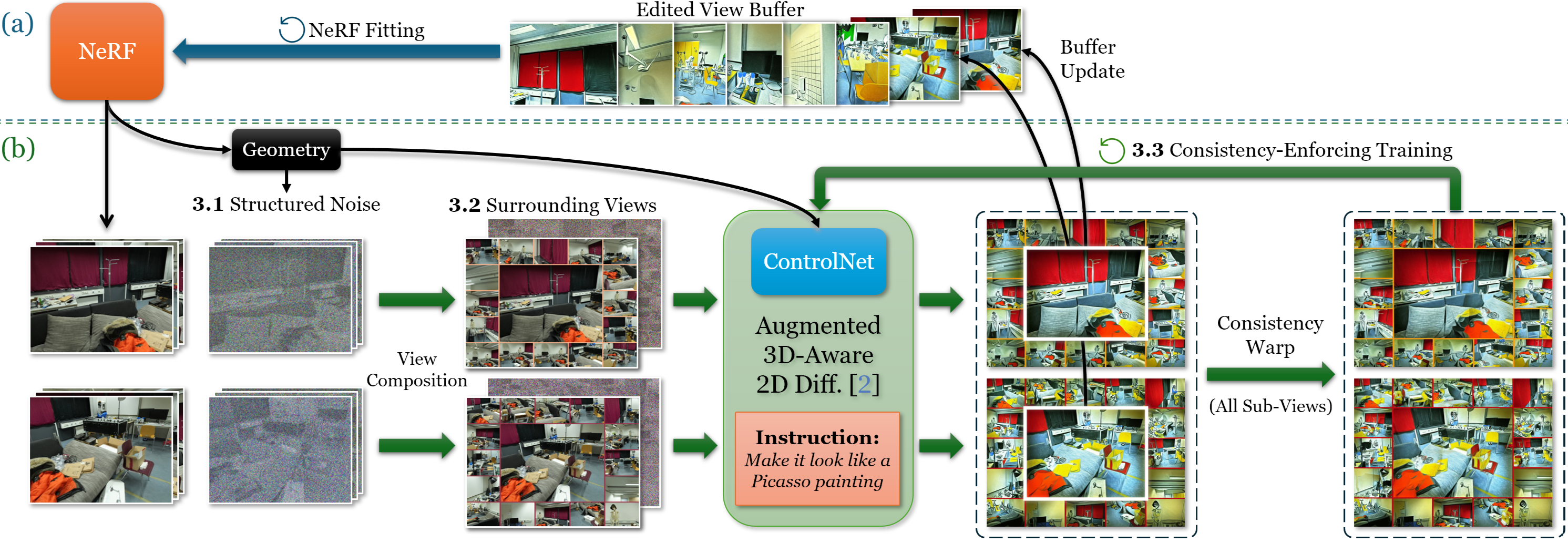
ConsistDreamer: 3D-Consistent 2D Diffusion for High-Fidelity Scene Editing
Jun-Kun Chen, Samuel Rota Bul`o, Norman Muller, Lorenzo Porzi, Peter Kontschieder, Yu-Xiong Wang
0
0
This paper proposes ConsistDreamer - a novel framework that lifts 2D diffusion models with 3D awareness and 3D consistency, thus enabling high-fidelity instruction-guided scene editing. To overcome the fundamental limitation of missing 3D consistency in 2D diffusion models, our key insight is to introduce three synergetic strategies that augment the input of the 2D diffusion model to become 3D-aware and to explicitly enforce 3D consistency during the training process. Specifically, we design surrounding views as context-rich input for the 2D diffusion model, and generate 3D-consistent, structured noise instead of image-independent noise. Moreover, we introduce self-supervised consistency-enforcing training within the per-scene editing procedure. Extensive evaluation shows that our ConsistDreamer achieves state-of-the-art performance for instruction-guided scene editing across various scenes and editing instructions, particularly in complicated large-scale indoor scenes from ScanNet++, with significantly improved sharpness and fine-grained textures. Notably, ConsistDreamer stands as the first work capable of successfully editing complex (e.g., plaid/checkered) patterns. Our project page is at immortalco.github.io/ConsistDreamer.
6/14/2024
🛸
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, Xiao Yang
0
0
We introduce MVDream, a diffusion model that is able to generate consistent multi-view images from a given text prompt. Learning from both 2D and 3D data, a multi-view diffusion model can achieve the generalizability of 2D diffusion models and the consistency of 3D renderings. We demonstrate that such a multi-view diffusion model is implicitly a generalizable 3D prior agnostic to 3D representations. It can be applied to 3D generation via Score Distillation Sampling, significantly enhancing the consistency and stability of existing 2D-lifting methods. It can also learn new concepts from a few 2D examples, akin to DreamBooth, but for 3D generation.
4/19/2024

MVDiff: Scalable and Flexible Multi-View Diffusion for 3D Object Reconstruction from Single-View
Emmanuelle Bourigault, Pauline Bourigault
0
0
Generating consistent multiple views for 3D reconstruction tasks is still a challenge to existing image-to-3D diffusion models. Generally, incorporating 3D representations into diffusion model decrease the model's speed as well as generalizability and quality. This paper proposes a general framework to generate consistent multi-view images from single image or leveraging scene representation transformer and view-conditioned diffusion model. In the model, we introduce epipolar geometry constraints and multi-view attention to enforce 3D consistency. From as few as one image input, our model is able to generate 3D meshes surpassing baselines methods in evaluation metrics, including PSNR, SSIM and LPIPS.
6/14/2024

MultiDiff: Consistent Novel View Synthesis from a Single Image
Norman Muller, Katja Schwarz, Barbara Roessle, Lorenzo Porzi, Samuel Rota Bul`o, Matthias Nie{ss}ner, Peter Kontschieder
0
0
We introduce MultiDiff, a novel approach for consistent novel view synthesis of scenes from a single RGB image. The task of synthesizing novel views from a single reference image is highly ill-posed by nature, as there exist multiple, plausible explanations for unobserved areas. To address this issue, we incorporate strong priors in form of monocular depth predictors and video-diffusion models. Monocular depth enables us to condition our model on warped reference images for the target views, increasing geometric stability. The video-diffusion prior provides a strong proxy for 3D scenes, allowing the model to learn continuous and pixel-accurate correspondences across generated images. In contrast to approaches relying on autoregressive image generation that are prone to drifts and error accumulation, MultiDiff jointly synthesizes a sequence of frames yielding high-quality and multi-view consistent results -- even for long-term scene generation with large camera movements, while reducing inference time by an order of magnitude. For additional consistency and image quality improvements, we introduce a novel, structured noise distribution. Our experimental results demonstrate that MultiDiff outperforms state-of-the-art methods on the challenging, real-world datasets RealEstate10K and ScanNet. Finally, our model naturally supports multi-view consistent editing without the need for further tuning.
6/27/2024