MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning
2404.05621
0
0
Abstract
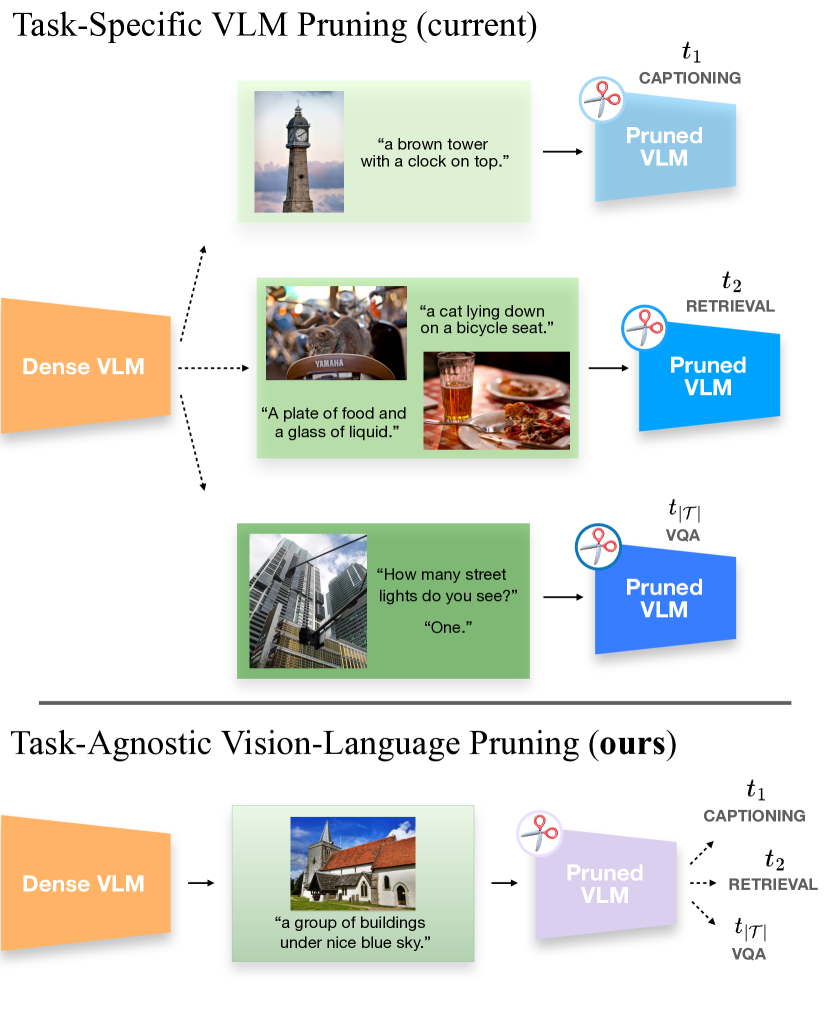
While excellent in transfer learning, Vision-Language models (VLMs) come with high computational costs due to their large number of parameters. To address this issue, removing parameters via model pruning is a viable solution. However, existing techniques for VLMs are task-specific, and thus require pruning the network from scratch for each new task of interest. In this work, we explore a new direction: Task-Agnostic Vision-Language Pruning (TA-VLP). Given a pretrained VLM, the goal is to find a unique pruned counterpart transferable to multiple unknown downstream tasks. In this challenging setting, the transferable representations already encoded in the pretrained model are a key aspect to preserve. Thus, we propose Multimodal Flow Pruning (MULTIFLOW), a first, gradient-free, pruning framework for TA-VLP where: (i) the importance of a parameter is expressed in terms of its magnitude and its information flow, by incorporating the saliency of the neurons it connects; and (ii) pruning is driven by the emergent (multimodal) distribution of the VLM parameters after pretraining. We benchmark eight state-of-the-art pruning algorithms in the context of TA-VLP, experimenting with two VLMs, three vision-language tasks, and three pruning ratios. Our experimental results show that MULTIFLOW outperforms recent sophisticated, combinatorial competitors in the vast majority of the cases, paving the way towards addressing TA-VLP. The code is publicly available at https://github.com/FarinaMatteo/multiflow.
Create account to get full access
Overview
- Proposes a task-agnostic vision-language pruning approach called "multiflow" that can be applied to various vision-language models
- Aims to improve the efficiency and performance of these models without task-specific fine-tuning
- Introduces a novel training pipeline and loss function to enable task-agnostic pruning
Plain English Explanation
The paper introduces a new technique called "multiflow" that can help make vision-language AI models more efficient and effective without having to retrain or fine-tune them for specific tasks.
Vision-language models are AI systems that can understand and process both visual and textual information. They are powerful but can also be complex and resource-intensive. The researchers behind this paper wanted to find a way to "prune" or simplify these models so they can run faster and use less computing power, while still maintaining their performance.
Traditional pruning methods often require fine-tuning the model for each specific task, which can be time-consuming and impractical. The key innovation of "multiflow" is that it enables task-agnostic pruning - the model can be pruned without having to retrain it for a particular application. This makes the pruning process more flexible and scalable.
The paper describes a new training pipeline and loss function that enable this task-agnostic approach. In simple terms, the model is trained to learn a more efficient internal structure that can work well across a variety of tasks, rather than being optimized for a single narrow use case.
This advance could help make powerful vision-language AI models more accessible and usable in real-world applications where computing resources and time are limited. By making these models more efficient, the "multiflow" approach could unlock new possibilities for deploying them in the real world.
Technical Explanation
The paper introduces a novel technique called "multiflow" for task-agnostic vision-language pruning. Traditional pruning methods often require task-specific fine-tuning, which can be time-consuming and impractical. The key innovation of "multiflow" is that it enables pruning without the need for task-specific fine-tuning.
The authors propose a new training pipeline and loss function to enable this task-agnostic pruning approach. The model is trained to learn a more efficient internal structure that can work well across a variety of tasks, rather than being optimized for a single narrow use case.
The training pipeline consists of two key components: 1) a multi-task training setup that exposes the model to a diverse set of vision-language tasks, and 2) a novel "multiflow" loss function that encourages the model to learn a compact and transferable representation.
The multi-task training setup allows the model to build general capabilities that can be applied across different applications, rather than specializing in a single task. The "multiflow" loss function then pushes the model to find an efficient internal structure that can maintain performance on this diverse set of tasks.
Through extensive experiments, the authors demonstrate that the "multiflow" approach can achieve significant model compression (up to 5x reduction in parameters) without sacrificing performance on a wide range of vision-language benchmarks. This suggests that "multiflow" can be a powerful tool for making large, resource-intensive vision-language models more practical and deployable in real-world settings.
Critical Analysis
The "multiflow" approach presented in this paper is a promising step towards making vision-language AI models more efficient and accessible. By enabling task-agnostic pruning, the technique avoids the need for time-consuming fine-tuning on specific applications, which could greatly simplify the deployment of these powerful models.
However, the paper does not address some potential limitations and areas for further research. For example, it is unclear how well the "multiflow" approach would scale to extremely large-scale vision-language models, or how it would perform on more specialized or niche tasks that differ significantly from the benchmarks used in the experiments.
Additionally, the paper does not provide much insight into the internal mechanisms and trade-offs of the "multiflow" loss function. It would be valuable to understand more about how this function balances the objectives of maintaining performance and achieving model compression, and whether there are any inherent tensions or limitations in this approach.
Despite these caveats, the "multiflow" technique represents an important advance in the field of efficient vision-language AI. By decoupling model pruning from task-specific fine-tuning, it opens up new possibilities for deploying these powerful models in real-world applications where computational resources and time are limited. Further research and refinement of this approach could yield even greater benefits for the broader AI community.
Conclusion
The "multiflow" technique introduced in this paper is a significant step towards making vision-language AI models more efficient and widely deployable. By enabling task-agnostic pruning, it avoids the need for time-consuming fine-tuning on specific applications, which could greatly simplify the process of deploying these powerful models in the real world.
The authors' novel training pipeline and loss function allow the model to learn a compact and transferable representation that can maintain performance across a diverse set of vision-language tasks. This advancement could unlock new possibilities for applying large, resource-intensive vision-language models in scenarios where computing power and time are constrained, such as on edge devices or in resource-limited settings.
While the paper does not address all potential limitations and areas for further research, the "multiflow" approach represents an important contribution to the field of efficient AI. By decoupling model pruning from task-specific fine-tuning, it opens up new avenues for streamlining the deployment of advanced vision-language technologies and expanding their real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
FLoRA: Enhancing Vision-Language Models with Parameter-Efficient Federated Learning
Duy Phuong Nguyen, J. Pablo Munoz, Ali Jannesari
0
0
In the rapidly evolving field of artificial intelligence, multimodal models, e.g., integrating vision and language into visual-language models (VLMs), have become pivotal for many applications, ranging from image captioning to multimodal search engines. Among these models, the Contrastive Language-Image Pre-training (CLIP) model has demonstrated remarkable performance in understanding and generating nuanced relationships between text and images. However, the conventional training of such models often requires centralized aggregation of vast datasets, posing significant privacy and data governance challenges. To address these concerns, this paper proposes a novel approach that leverages Federated Learning and parameter-efficient adapters, i.e., Low-Rank Adaptation (LoRA), to train VLMs. This methodology preserves data privacy by training models across decentralized data sources and ensures model adaptability and efficiency through LoRA's parameter-efficient fine-tuning. Our approach accelerates training time by up to 34.72 times and requires 2.47 times less memory usage than full fine-tuning.
4/24/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024
💬
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
0
0
The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, OpenLLaMA and the concurrent TinyLlama models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building competitive small-scale LLMs
4/12/2024
Bridging Vision and Language Spaces with Assignment Prediction
Jungin Park, Jiyoung Lee, Kwanghoon Sohn
0
0
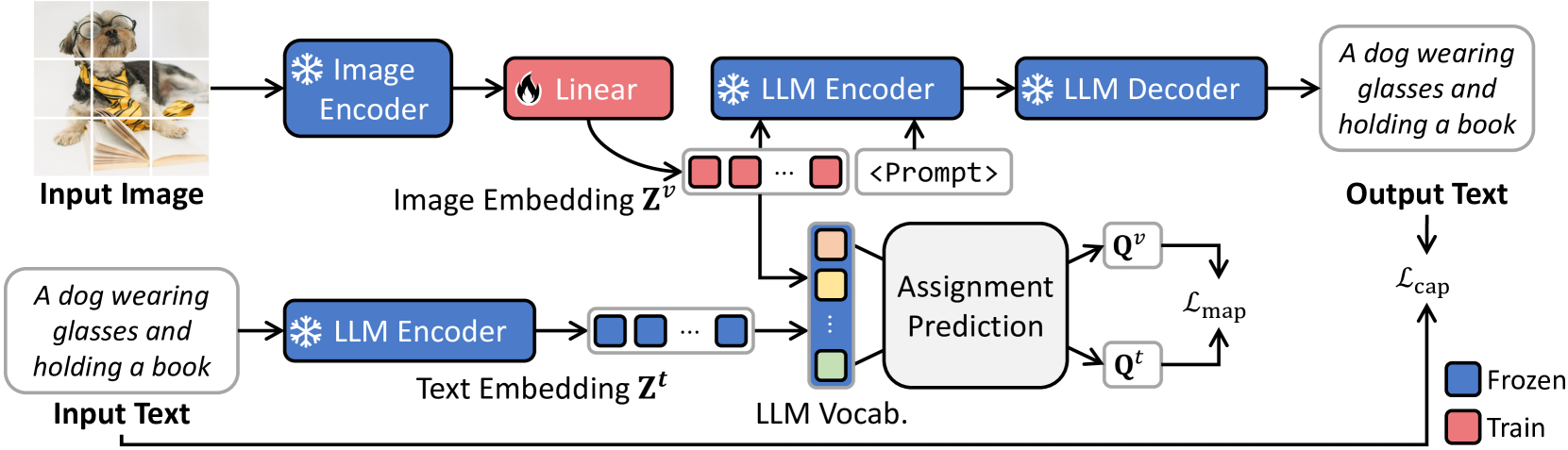
This paper introduces VLAP, a novel approach that bridges pretrained vision models and large language models (LLMs) to make frozen LLMs understand the visual world. VLAP transforms the embedding space of pretrained vision models into the LLMs' word embedding space using a single linear layer for efficient and general-purpose visual and language understanding. Specifically, we harness well-established word embeddings to bridge two modality embedding spaces. The visual and text representations are simultaneously assigned to a set of word embeddings within pretrained LLMs by formulating the assigning procedure as an optimal transport problem. We predict the assignment of one modality from the representation of another modality data, enforcing consistent assignments for paired multimodal data. This allows vision and language representations to contain the same information, grounding the frozen LLMs' word embedding space in visual data. Moreover, a robust semantic taxonomy of LLMs can be preserved with visual data since the LLMs interpret and reason linguistic information from correlations between word embeddings. Experimental results show that VLAP achieves substantial improvements over the previous linear transformation-based approaches across a range of vision-language tasks, including image captioning, visual question answering, and cross-modal retrieval. We also demonstrate the learned visual representations hold a semantic taxonomy of LLMs, making visual semantic arithmetic possible.
4/16/2024