MultiFuser: Multimodal Fusion Transformer for Enhanced Driver Action Recognition

0

Sign in to get full access
Overview
- MultiFuser is a multimodal fusion transformer model for enhanced driver action recognition
- It combines visual and audio inputs to improve the accuracy of detecting driver actions
- The model uses a vision transformer architecture with a novel fusion mechanism to integrate the different modalities
Plain English Explanation
MultiFuser is a machine learning model that aims to improve the recognition of driver actions. Driver action recognition is the task of identifying what a driver is doing, such as signaling a turn, braking, or adjusting the radio.
This model takes in visual information (like camera footage of the driver) and audio information (like sounds inside the car) and combines them to make more accurate predictions about the driver's actions. The key innovation is the fusion mechanism, which allows the model to effectively integrate the different types of sensory inputs.
By using both visual and audio cues, the MultiFuser model can potentially detect driver actions more reliably than a model that only uses one type of input. This could be useful for applications like advanced driver assistance systems or autonomous vehicles, where understanding the driver's behavior is important for safety and control.
Technical Explanation
The MultiFuser model uses a vision transformer architecture as its backbone. Transformers are a type of neural network that have shown promising results for various computer vision tasks.
The key component of MultiFuser is the fusion mechanism, which integrates the visual and audio inputs. This is done by first encoding the inputs into feature representations using separate encoders. Then, a fusion module combines these features by attending to relevant information from both modalities.
The fused features are then passed through additional transformer layers to produce the final driver action predictions. The authors experimented with different fusion strategies and found that a cross-attention based approach, where the visual features attend to the audio features and vice versa, worked best.
The MultiFuser model was evaluated on a dataset of driver actions and demonstrated improved performance compared to baseline models that used only visual or audio inputs.
Critical Analysis
The paper provides a thorough evaluation of the MultiFuser model and discusses its strengths and limitations. One potential limitation is that the model was trained and tested on a specific dataset of driver actions, so its performance may not generalize well to other driving scenarios or datasets.
Additionally, the authors note that the fusion mechanism adds computational complexity to the model, which could be a concern for real-time applications. Further research is needed to optimize the efficiency of the fusion process.
It would also be interesting to see how MultiFuser performs compared to other multimodal fusion approaches, such as CM2-Net or DeepInteraction, to better understand its relative strengths and weaknesses.
Conclusion
The MultiFuser model demonstrates the potential of using multimodal fusion techniques to enhance driver action recognition. By effectively combining visual and audio cues, the model can make more accurate predictions about driver behavior, which could have important implications for safety-critical applications in the automotive industry.
While the paper provides a solid technical foundation, further research is needed to address the model's computational complexity and generalization capabilities. Overall, the MultiFuser approach represents an interesting and promising step forward in the field of multimodal driver monitoring and action recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MultiFuser: Multimodal Fusion Transformer for Enhanced Driver Action Recognition
Ruoyu Wang, Wenqian Wang, Jianjun Gao, Dan Lin, Kim-Hui Yap, Bingbing Li
Driver action recognition, aiming to accurately identify drivers' behaviours, is crucial for enhancing driver-vehicle interactions and ensuring driving safety. Unlike general action recognition, drivers' environments are often challenging, being gloomy and dark, and with the development of sensors, various cameras such as IR and depth cameras have emerged for analyzing drivers' behaviors. Therefore, in this paper, we propose a novel multimodal fusion transformer, named MultiFuser, which identifies cross-modal interrelations and interactions among multimodal car cabin videos and adaptively integrates different modalities for improved representations. Specifically, MultiFuser comprises layers of Bi-decomposed Modules to model spatiotemporal features, with a modality synthesizer for multimodal features integration. Each Bi-decomposed Module includes a Modal Expertise ViT block for extracting modality-specific features and a Patch-wise Adaptive Fusion block for efficient cross-modal fusion. Extensive experiments are conducted on Drive&Act dataset and the results demonstrate the efficacy of our proposed approach.
Read more8/20/2024
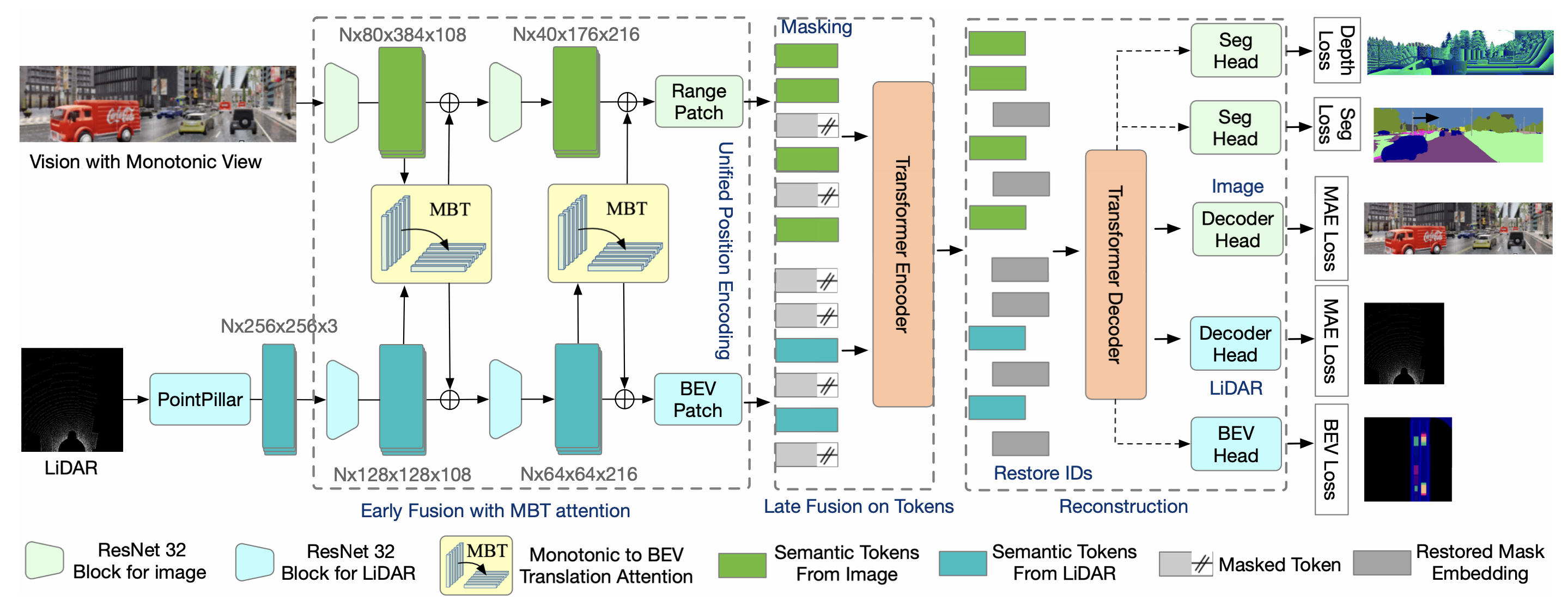
0
MaskFuser: Masked Fusion of Joint Multi-Modal Tokenization for End-to-End Autonomous Driving
Yiqun Duan, Xianda Guo, Zheng Zhu, Zhen Wang, Yu-Kai Wang, Chin-Teng Lin
Current multi-modality driving frameworks normally fuse representation by utilizing attention between single-modality branches. However, the existing networks still suppress the driving performance as the Image and LiDAR branches are independent and lack a unified observation representation. Thus, this paper proposes MaskFuser, which tokenizes various modalities into a unified semantic feature space and provides a joint representation for further behavior cloning in driving contexts. Given the unified token representation, MaskFuser is the first work to introduce cross-modality masked auto-encoder training. The masked training enhances the fusion representation by reconstruction on masked tokens. Architecturally, a hybrid-fusion network is proposed to combine advantages from both early and late fusion: For the early fusion stage, modalities are fused by performing monotonic-to-BEV translation attention between branches; Late fusion is performed by tokenizing various modalities into a unified token space with shared encoding on it. MaskFuser respectively reaches a driving score of 49.05 and route completion of 92.85% on the CARLA LongSet6 benchmark evaluation, which improves the best of previous baselines by 1.74 and 3.21%. The introduced masked fusion increases driving stability under damaged sensory inputs. MaskFuser outperforms the best of previous baselines on driving score by 6.55 (27.8%), 1.53 (13.8%), 1.57 (30.9%), respectively given sensory masking ratios 25%, 50%, and 75%.
Read more5/14/2024

0
CM2-Net: Continual Cross-Modal Mapping Network for Driver Action Recognition
Ruoyu Wang, Chen Cai, Wenqian Wang, Jianjun Gao, Dan Lin, Wenyang Liu, Kim-Hui Yap
Driver action recognition has significantly advanced in enhancing driver-vehicle interactions and ensuring driving safety by integrating multiple modalities, such as infrared and depth. Nevertheless, compared to RGB modality only, it is always laborious and costly to collect extensive data for all types of non-RGB modalities in car cabin environments. Therefore, previous works have suggested independently learning each non-RGB modality by fine-tuning a model pre-trained on RGB videos, but these methods are less effective in extracting informative features when faced with newly-incoming modalities due to large domain gaps. In contrast, we propose a Continual Cross-Modal Mapping Network (CM2-Net) to continually learn each newly-incoming modality with instructive prompts from the previously-learned modalities. Specifically, we have developed Accumulative Cross-modal Mapping Prompting (ACMP), to map the discriminative and informative features learned from previous modalities into the feature space of newly-incoming modalities. Then, when faced with newly-incoming modalities, these mapped features are able to provide effective prompts for which features should be extracted and prioritized. These prompts are accumulating throughout the continual learning process, thereby boosting further recognition performances. Extensive experiments conducted on the Drive&Act dataset demonstrate the performance superiority of CM2-Net on both uni- and multi-modal driver action recognition.
Read more6/19/2024

0
DeepInteraction++: Multi-Modality Interaction for Autonomous Driving
Zeyu Yang, Nan Song, Wei Li, Xiatian Zhu, Li Zhang, Philip H. S. Torr
Existing top-performance autonomous driving systems typically rely on the multi-modal fusion strategy for reliable scene understanding. This design is however fundamentally restricted due to overlooking the modality-specific strengths and finally hampering the model performance. To address this limitation, in this work, we introduce a novel modality interaction strategy that allows individual per-modality representations to be learned and maintained throughout, enabling their unique characteristics to be exploited during the whole perception pipeline. To demonstrate the effectiveness of the proposed strategy, we design DeepInteraction++, a multi-modal interaction framework characterized by a multi-modal representational interaction encoder and a multi-modal predictive interaction decoder. Specifically, the encoder is implemented as a dual-stream Transformer with specialized attention operation for information exchange and integration between separate modality-specific representations. Our multi-modal representational learning incorporates both object-centric, precise sampling-based feature alignment and global dense information spreading, essential for the more challenging planning task. The decoder is designed to iteratively refine the predictions by alternately aggregating information from separate representations in a unified modality-agnostic manner, realizing multi-modal predictive interaction. Extensive experiments demonstrate the superior performance of the proposed framework on both 3D object detection and end-to-end autonomous driving tasks. Our code is available at https://github.com/fudan-zvg/DeepInteraction.
Read more8/16/2024