Multilateral Temporal-view Pyramid Transformer for Video Inpainting Detection
2404.11054
0
0
Abstract
The task of video inpainting detection is to expose the pixel-level inpainted regions within a video sequence. Existing methods usually focus on leveraging spatial and temporal inconsistencies. However, these methods typically employ fixed operations to combine spatial and temporal clues, limiting their applicability in different scenarios. In this paper, we introduce a novel Multilateral Temporal-view Pyramid Transformer ({em MumPy}) that collaborates spatial-temporal clues flexibly. Our method utilizes a newly designed multilateral temporal-view encoder to extract various collaborations of spatial-temporal clues and introduces a deformable window-based temporal-view interaction module to enhance the diversity of these collaborations. Subsequently, we develop a multi-pyramid decoder to aggregate the various types of features and generate detection maps. By adjusting the contribution strength of spatial and temporal clues, our method can effectively identify inpainted regions. We validate our method on existing datasets and also introduce a new challenging and large-scale Video Inpainting dataset based on the YouTube-VOS dataset, which employs several more recent inpainting methods. The results demonstrate the superiority of our method in both in-domain and cross-domain evaluation scenarios.
Create account to get full access
Overview
- This paper introduces a novel Multilateral Temporal-view Pyramid Transformer (MTPT) model for video inpainting detection.
- Video inpainting is the task of filling in missing or corrupted regions in a video sequence, which is important for various applications like video restoration and video surveillance.
- The proposed MTPT model leverages a multi-scale transformer architecture and a multilateral temporal-view pyramid to capture both spatial and temporal information for effective video inpainting detection.
Plain English Explanation
The paper describes a new deep learning model called the Multilateral Temporal-view Pyramid Transformer (MTPT) that can be used for video inpainting detection. Video inpainting is the process of automatically filling in missing or corrupted regions in a video, which is important for things like video restoration and video surveillance.
The key innovation of the MTPT model is that it uses a multi-scale transformer architecture and a multilateral temporal-view pyramid to capture both the spatial and temporal information in the video. This allows the model to effectively detect and localize areas in the video that need to be inpainted or filled in.
Transformers are a type of deep learning model that are particularly good at processing sequential data like text or video. The MTPT model uses multiple transformer layers at different scales to analyze the video at different levels of detail. And the multilateral temporal-view pyramid allows the model to look at the video from multiple time perspectives, not just the current frame.
By combining these two techniques - multi-scale transformers and multilateral temporal-views - the MTPT model is able to accurately detect areas in a video that are corrupted or missing, which is an important first step for video inpainting applications.
Technical Explanation
The core innovation of the MTPT model is its use of a multi-scale transformer architecture combined with a multilateral temporal-view pyramid. This allows the model to effectively capture both the spatial and temporal information in the video for video inpainting detection.
The multi-scale transformer consists of multiple transformer layers that operate at different resolutions. This enables the model to analyze the video at multiple levels of detail, from coarse-grained global features to fine-grained local features. Transformer-based models have shown strong performance on sequence-to-sequence tasks like video processing.
The multilateral temporal-view pyramid allows the model to inspect the video from multiple time perspectives, not just the current frame. This helps the model better understand the temporal dynamics and context of the video. The pyramid structure extracts features from multiple adjacent frames at different scales, providing a richer representation of the video.
By combining the multi-scale transformer and multilateral temporal-view components, the MTPT model is able to effectively detect and localize corrupted or missing regions in video sequences, which is a crucial first step for video inpainting tasks. This enables applications like video restoration, video surveillance, and video editing.
Critical Analysis
The authors thoroughly evaluate the MTPT model on several video inpainting detection benchmarks and demonstrate state-of-the-art performance. However, the paper does not provide much insight into the limitations or potential drawbacks of the approach.
One potential issue is the computational complexity of the multi-scale transformer and multilateral temporal-view components, which could make the model slower or more resource-intensive than simpler approaches. The authors do not discuss the trade-offs between model accuracy and inference speed.
Additionally, the paper focuses only on video inpainting detection, but does not cover the subsequent video inpainting task of actually filling in the missing regions. Other research has looked at combining detection and inpainting, which could be an interesting avenue for future work.
Overall, the MTPT model represents a promising advance in video inpainting detection, but further research is needed to understand its practical limitations and how it might be integrated into end-to-end video inpainting pipelines. Readers are encouraged to think critically about the model's strengths, weaknesses, and potential real-world applications.
Conclusion
This paper introduces a novel Multilateral Temporal-view Pyramid Transformer (MTPT) model for video inpainting detection. The key innovation is the combination of a multi-scale transformer architecture and a multilateral temporal-view pyramid, which allows the model to effectively capture both spatial and temporal information in video sequences.
The MTPT model demonstrates state-of-the-art performance on several video inpainting detection benchmarks, making it a promising tool for applications like video restoration, video surveillance, and video editing. While the paper does not deeply explore the limitations of the approach, it represents an important advance in the field of video inpainting that could inspire future research into more efficient and versatile video processing models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Trusted Video Inpainting Localization via Deep Attentive Noise Learning
Zijie Lou, Gang Cao, Man Lin
0
0
Digital video inpainting techniques have been substantially improved with deep learning in recent years. Although inpainting is originally designed to repair damaged areas, it can also be used as malicious manipulation to remove important objects for creating false scenes and facts. As such it is significant to identify inpainted regions blindly. In this paper, we present a Trusted Video Inpainting Localization network (TruVIL) with excellent robustness and generalization ability. Observing that high-frequency noise can effectively unveil the inpainted regions, we design deep attentive noise learning in multiple stages to capture the inpainting traces. Firstly, a multi-scale noise extraction module based on 3D High Pass (HP3D) layers is used to create the noise modality from input RGB frames. Then the correlation between such two complementary modalities are explored by a cross-modality attentive fusion module to facilitate mutual feature learning. Lastly, spatial details are selectively enhanced by an attentive noise decoding module to boost the localization performance of the network. To prepare enough training samples, we also build a frame-level video object segmentation dataset of 2500 videos with pixel-level annotation for all frames. Extensive experimental results validate the superiority of TruVIL compared with the state-of-the-arts. In particular, both quantitative and qualitative evaluations on various inpainted videos verify the remarkable robustness and generalization ability of our proposed TruVIL. Code and dataset will be available at https://github.com/multimediaFor/TruVIL.
6/21/2024
📶
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Dylan Green, William Harvey, Saeid Naderiparizi, Matthew Niedoba, Yunpeng Liu, Xiaoxuan Liang, Jonathan Lavington, Ke Zhang, Vasileios Lioutas, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, Frank Wood
0
0
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
5/2/2024

VIP: Versatile Image Outpainting Empowered by Multimodal Large Language Model
Jinze Yang, Haoran Wang, Zining Zhu, Chenglong Liu, Meng Wymond Wu, Zeke Xie, Zhong Ji, Jungong Han, Mingming Sun
0
0
In this paper, we focus on resolving the problem of image outpainting, which aims to extrapolate the surrounding parts given the center contents of an image. Although recent works have achieved promising performance, the lack of versatility and customization hinders their practical applications in broader scenarios. Therefore, this work presents a novel image outpainting framework that is capable of customizing the results according to the requirement of users. First of all, we take advantage of a Multimodal Large Language Model (MLLM) that automatically extracts and organizes the corresponding textual descriptions of the masked and unmasked part of a given image. Accordingly, the obtained text prompts are introduced to endow our model with the capacity to customize the outpainting results. In addition, a special Cross-Attention module, namely Center-Total-Surrounding (CTS), is elaborately designed to enhance further the the interaction between specific space regions of the image and corresponding parts of the text prompts. Note that unlike most existing methods, our approach is very resource-efficient since it is just slightly fine-tuned on the off-the-shelf stable diffusion (SD) model rather than being trained from scratch. Finally, the experimental results on three commonly used datasets, i.e. Scenery, Building, and WikiArt, demonstrate our model significantly surpasses the SoTA methods. Moreover, versatile outpainting results are listed to show its customized ability.
6/4/2024
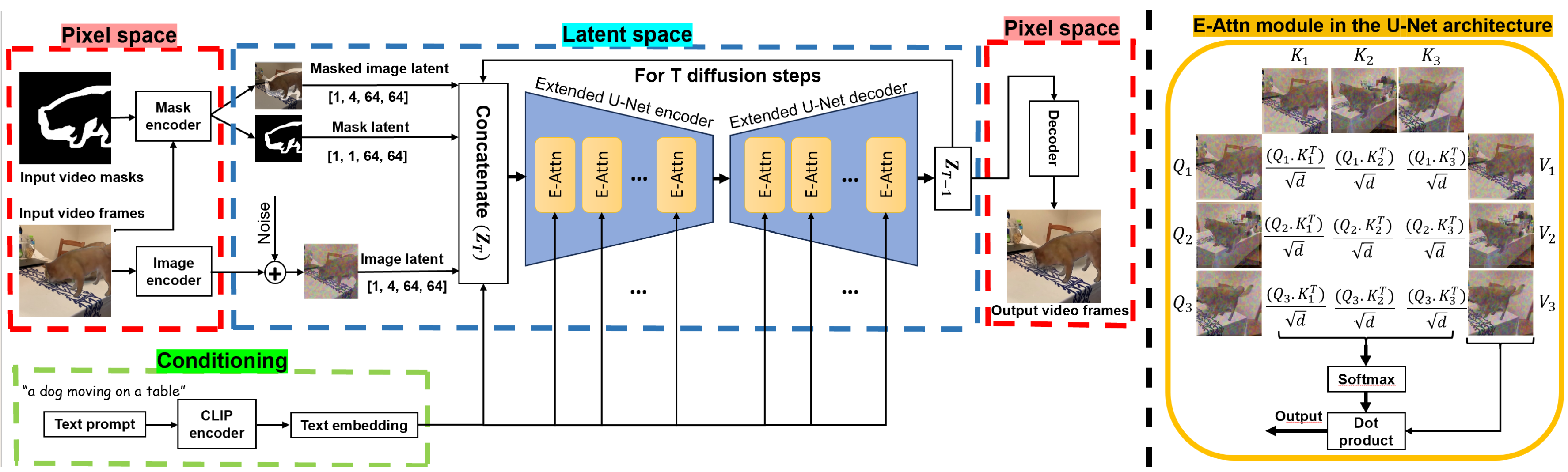
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
0
0
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
6/4/2024