On the Multilingual Ability of Decoder-based Pre-trained Language Models: Finding and Controlling Language-Specific Neurons
2404.02431
0
0
Abstract
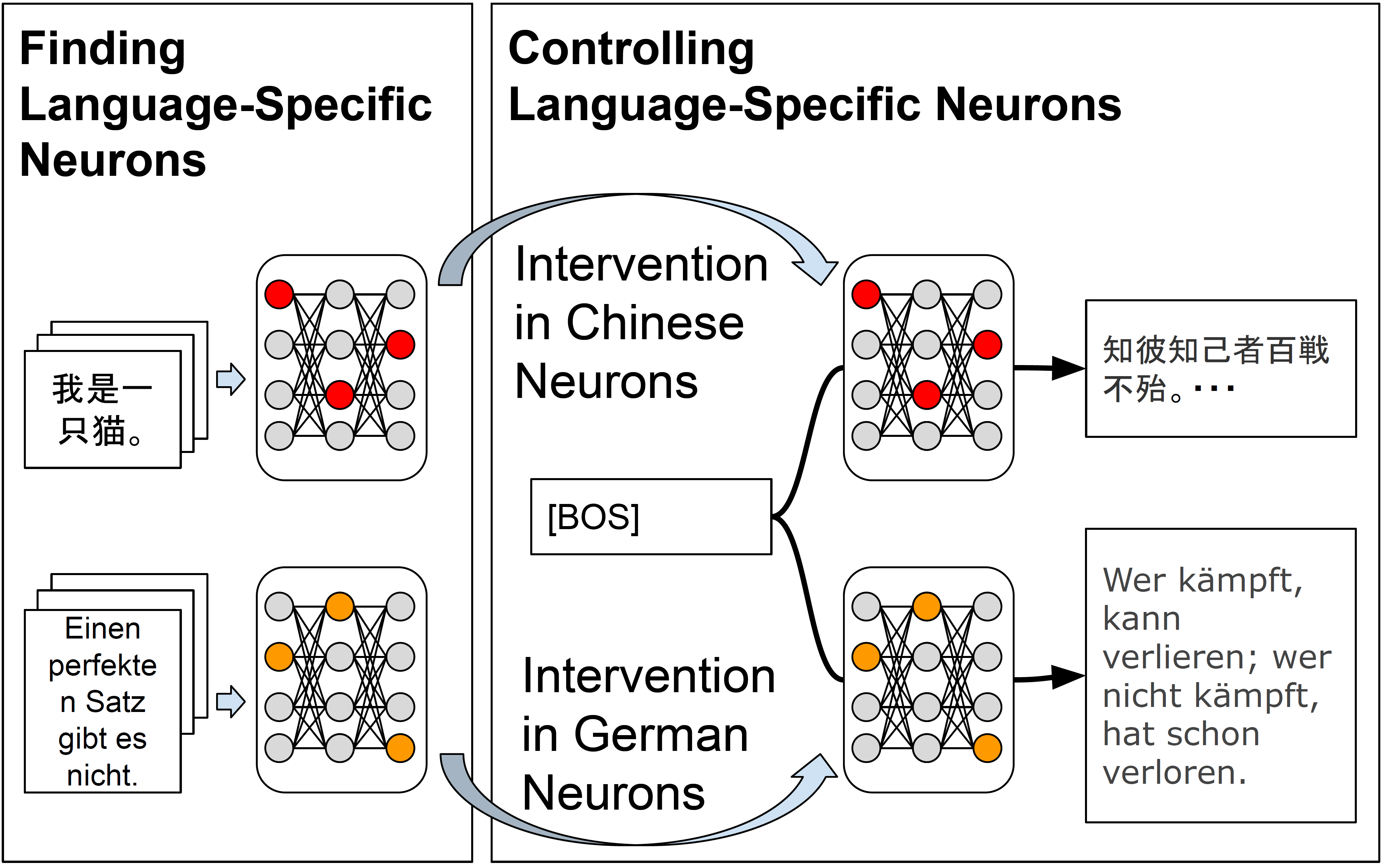
Current decoder-based pre-trained language models (PLMs) successfully demonstrate multilingual capabilities. However, it is unclear how these models handle multilingualism. We analyze the neuron-level internal behavior of multilingual decoder-based PLMs, Specifically examining the existence of neurons that fire ``uniquely for each language'' within decoder-only multilingual PLMs. We analyze six languages: English, German, French, Spanish, Chinese, and Japanese, and show that language-specific neurons are unique, with a slight overlap (< 5%) between languages. These neurons are mainly distributed in the models' first and last few layers. This trend remains consistent across languages and models. Additionally, we tamper with less than 1% of the total neurons in each model during inference and demonstrate that tampering with a few language-specific neurons drastically changes the probability of target language occurrence in text generation.
Create account to get full access
Overview
- This paper investigates the multilingual capabilities of decoder-based pre-trained language models.
- The researchers aimed to identify and control language-specific neurons within these models.
- They conducted experiments to understand how the models represent and process different languages.
Plain English Explanation
The researchers were curious about how well pre-trained language models, which are AI systems trained on vast amounts of text data, can handle multiple languages. These models are often used for tasks like translation and text generation, so it's important to understand their multilingual abilities.
The key idea was to look inside the "black box" of these models and see if there are specific neurons or components that are responsible for processing particular languages. If so, the researchers wanted to see if they could control and manipulate these language-specific parts of the model.
To do this, they ran a series of experiments where they fed the models text in different languages and analyzed the model's responses. They looked for patterns in the model's internal activations that were unique to each language. Ultimately, they were able to identify language-specific neurons and demonstrate ways to selectively activate or deactivate them to influence the model's multilingual behavior.
Technical Explanation
The researchers used decoder-based pre-trained language models, specifically GPT-2 and GPT-Neo, as the basis for their investigations. They first probed the models' multilingual capabilities by testing their performance on a range of cross-lingual tasks, including translation, text generation, and language identification.
To analyze the inner workings of the models, the researchers employed techniques like neuron ablation and neuron edit, which allow them to isolate and manipulate individual neurons within the neural network. By carefully analyzing the model's responses before and after these interventions, they were able to identify neurons that were strongly associated with specific languages.
Further experiments demonstrated that these language-specific neurons could be selectively activated or deactivated to control the model's output in predictable ways. For example, they could force the model to generate text in a particular language or translate between languages more effectively.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the language-specific neurons they identified may not be the only way the models represent multilingual knowledge, and there may be more complex interactions between different components of the models. Additionally, the experiments were conducted on a relatively small set of languages, so the findings may not generalize to a broader range of languages.
Another potential concern is the potential for misuse of these techniques, as the ability to selectively control a model's language output could be used for malicious purposes, such as generating biased or harmful content in specific languages. The researchers emphasize the importance of responsible development and deployment of such capabilities.
Further research is needed to fully understand the multilingual representations and processing mechanisms in large language models. Exploring the generalizability of the findings, as well as examining the ethical implications of this work, will be important next steps.
Conclusion
This paper provides valuable insights into the multilingual abilities of decoder-based pre-trained language models. By identifying and manipulating language-specific neurons within these models, the researchers have demonstrated new ways to understand and control their multilingual behavior. This knowledge has the potential to improve the development of more robust and versatile multilingual AI systems, with applications in areas like machine translation, language generation, and multilingual content moderation. However, the findings also highlight the need for careful consideration of the ethical implications of such capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, Ji-Rong Wen
0
0
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
6/7/2024
How do Large Language Models Handle Multilingualism?
Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, Lidong Bing
0
0
Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query. To verify $texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $texttt{PLND}$, we validate $texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures. Moreover, $texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6%$ for high-resource languages and $2.3%$ for low-resource languages across all tasks with just $400$ documents.
5/27/2024
🐍
Finding and Editing Multi-Modal Neurons in Pre-Trained Transformers
Haowen Pan, Yixin Cao, Xiaozhi Wang, Xun Yang, Meng Wang
0
0
Understanding the internal mechanisms by which multi-modal large language models (LLMs) interpret different modalities and integrate cross-modal representations is becoming increasingly critical for continuous improvements in both academia and industry. In this paper, we propose a novel method to identify key neurons for interpretability -- how multi-modal LLMs bridge visual and textual concepts for captioning. Our method improves conventional works upon efficiency and applied range by removing needs of costly gradient computation. Based on those identified neurons, we further design a multi-modal knowledge editing method, beneficial to mitigate sensitive words or hallucination. For rationale of our design, we provide theoretical assumption. For empirical evaluation, we have conducted extensive quantitative and qualitative experiments. The results not only validate the effectiveness of our methods, but also offer insightful findings that highlight three key properties of multi-modal neurons: sensitivity, specificity and causal-effect, to shed light for future research.
6/12/2024

Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their Applications
Weize Liu, Yinlong Xu, Hongxia Xu, Jintai Chen, Xuming Hu, Jian Wu
0
0
Recently, large language models (LLMs) have achieved tremendous breakthroughs in the field of NLP, but still lack understanding of their internal activities when processing different languages. We designed a method to convert dense LLMs into fine-grained MoE architectures, and then visually studied the multilingual activation patterns of LLMs through expert activation frequency heatmaps. Through comprehensive experiments on different model families, different model sizes, and different variants, we analyzed the distribution of high-frequency activated experts, multilingual shared experts, whether the activation patterns of different languages are related to language families, and the impact of instruction tuning on activation patterns. We further explored leveraging the discovered differences in expert activation frequencies to guide unstructured pruning in two different ways. Experimental results demonstrated that our method significantly outperformed random expert pruning and even exceeded the performance of the original unpruned models in some languages. Additionally, we found that configuring different pruning rates for different layers based on activation level differences could achieve better results. Our findings reveal the multilingual processing mechanisms within LLMs and utilize these insights to offer new perspectives for applications such as model pruning.
6/19/2024