Multilingual Knowledge Editing with Language-Agnostic Factual Neurons

0

Sign in to get full access
Methodology
Multilingual Knowledge Editing with Language-Agnostic Factual Neurons
Overview
- The paper proposes a novel approach for multilingual knowledge editing that leverages "factual neurons" - language-agnostic neural representations of factual knowledge.
- This approach allows for efficient, accurate, and multilingual knowledge editing by decoupling the language-specific and language-agnostic components of large language models.
- The authors introduce a multilingual knowledge editing benchmark, MLAKE, to evaluate the proposed method.
Plain English Explanation
The researchers have developed a new way to edit and update the factual knowledge stored in large language models, like those used for tasks like translation and question answering. Their key insight is to identify and isolate the parts of the model that represent factual information, which they call "factual neurons."
By separating the language-specific and language-agnostic components of the model, they can efficiently make changes to the factual knowledge without having to retrain the entire model from scratch. This allows the model to be updated with new information in multiple languages at the same time.
To test this approach, the researchers created a new benchmark dataset called MLAKE, which evaluates how well models can edit and update their factual knowledge across different languages. This provides a way to measure the effectiveness of their proposed method.
Technical Explanation
The key innovation of this work is the identification and leveraging of "factual neurons" - language-agnostic neural representations of factual knowledge within large language models. By decoupling the language-specific and language-agnostic components of the model, the authors are able to efficiently edit and update the factual knowledge without having to retrain the entire model.
The authors introduce a novel multilingual knowledge editing benchmark, MLAKE, which they use to evaluate their proposed approach. MLAKE tests a model's ability to edit factual knowledge across multiple languages, providing a robust evaluation of the effectiveness of the language-agnostic factual neurons.
The MEMLA model architecture, which builds on the UNKE framework, is used to implement the language-agnostic factual neurons. This allows for efficient, accurate, and multilingual knowledge editing, as demonstrated on the MLAKE benchmark.
Critical Analysis
The paper makes a compelling case for the utility of language-agnostic factual neurons in enabling efficient and accurate multilingual knowledge editing. The MLAKE benchmark provides a valuable tool for evaluating progress in this area.
However, the paper does not address the potential limitations of this approach, such as the risk of introducing inconsistencies or biases when updating knowledge across multiple languages. Additionally, the UNKE and MEMLA frameworks are not thoroughly critiqued, and their potential drawbacks or areas for improvement are not discussed.
Further research could explore the robustness of the language-agnostic factual neurons, as well as investigate potential issues with degenerate knowledge in large language models and how they might be addressed in the context of multilingual knowledge editing.
Conclusion
The proposed approach of leveraging language-agnostic factual neurons for multilingual knowledge editing represents a significant advance in the field. By decoupling the language-specific and language-agnostic components of large language models, the authors have enabled efficient, accurate, and scalable knowledge updating across multiple languages.
The introduction of the MLAKE benchmark provides a valuable tool for evaluating progress in this area, and the demonstrated performance of the MEMLA model on this benchmark is an encouraging result. While the paper does not address all potential limitations, it lays the groundwork for further advancements in multilingual knowledge editing and the broader challenge of maintaining factual integrity in large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multilingual Knowledge Editing with Language-Agnostic Factual Neurons
Xue zhang, Yunlong Liang, Fandong Meng, Songming Zhang, Yufeng Chen, Jinan Xu, Jie Zhou
Multilingual knowledge editing (MKE) aims to simultaneously revise factual knowledge across multilingual languages within large language models (LLMs). However, most existing MKE methods just adapt existing monolingual editing methods to multilingual scenarios, overlooking the deep semantic connections of the same factual knowledge between different languages, thereby limiting edit performance. To address this issue, we first investigate how LLMs represent multilingual factual knowledge and discover that the same factual knowledge in different languages generally activates a shared set of neurons, which we call language-agnostic factual neurons. These neurons represent the semantic connections between multilingual knowledge and are mainly located in certain layers. Inspired by this finding, we propose a new MKE method by locating and modifying Language-Agnostic Factual Neurons (LAFN) to simultaneously edit multilingual knowledge. Specifically, we first generate a set of paraphrases for each multilingual knowledge to be edited to precisely locate the corresponding language-agnostic factual neurons. Then we optimize the update values for modifying these located neurons to achieve simultaneous modification of the same factual knowledge in multiple languages. Experimental results on Bi-ZsRE and MzsRE benchmarks demonstrate that our method outperforms existing MKE methods and achieves remarkable edit performance, indicating the importance of considering the semantic connections among multilingual knowledge.
Read more6/26/2024
0
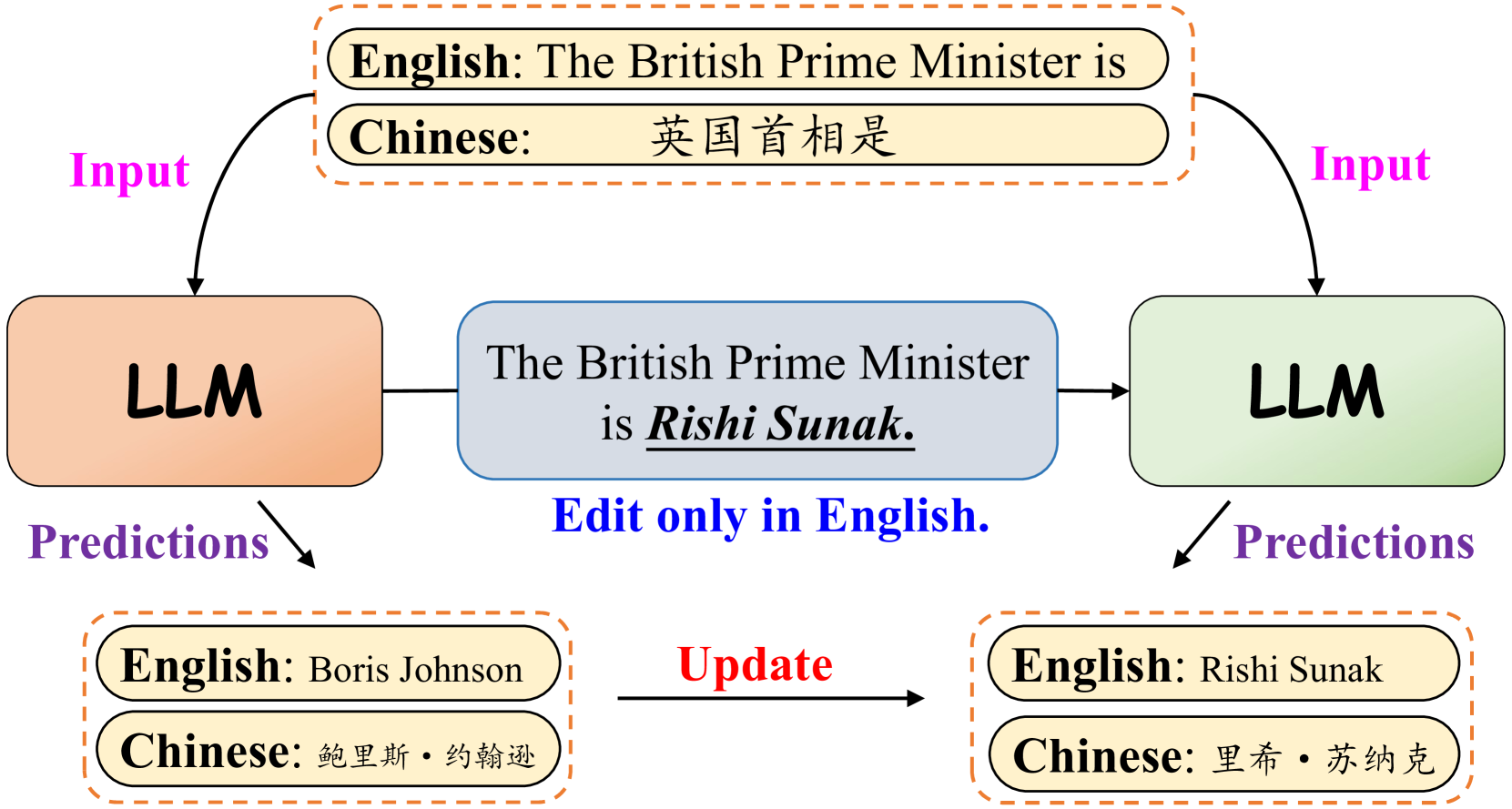
MEMLA: Enhancing Multilingual Knowledge Editing with Neuron-Masked Low-Rank Adaptation
Jiakuan Xie, Pengfei Cao, Yuheng Chen, Yubo Chen, Kang Liu, Jun Zhao
Knowledge editing aims to adjust the knowledge within large language models (LLMs) to prevent their responses from becoming obsolete or inaccurate. However, existing works on knowledge editing are primarily conducted in a single language, which is inadequate for multilingual language models. In this paper, we focus on multilingual knowledge editing (MKE), which requires propagating updates across multiple languages. This necessity poses a significant challenge for the task. Furthermore, the limited availability of a comprehensive dataset for MKE exacerbates this challenge, hindering progress in this area. Hence, we introduce the Multilingual Knowledge Editing Benchmark (MKEB), a novel dataset comprising 12 languages and providing a complete evaluation framework. Additionally, we propose a method that enhances Multilingual knowledge Editing with neuron-Masked Low-Rank Adaptation (MEMLA). Specifically, we identify two categories of knowledge neurons to improve editing precision. Moreover, we perform LoRA-based editing with neuron masks to efficiently modify parameters and facilitate the propagation of updates across multiple languages. Experiments demonstrate that our method outperforms existing baselines and significantly enhances the multi-hop reasoning capability of the edited model, with minimal impact on its downstream task performance. The dataset and code will be made publicly available.
Read more6/18/2024
0
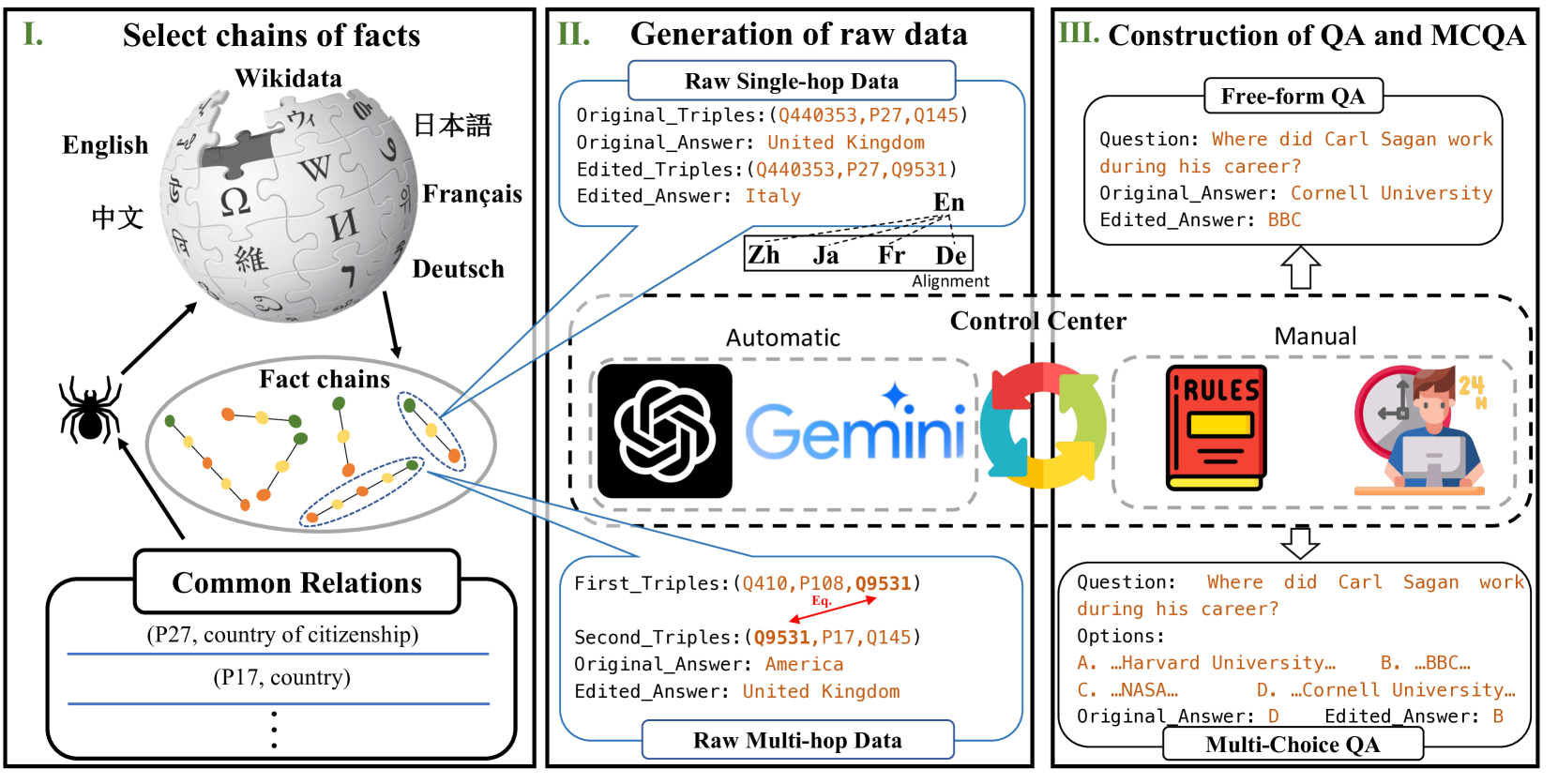
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Zihao Wei, Jingcheng Deng, Liang Pang, Hanxing Ding, Huawei Shen, Xueqi Cheng
The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Read more4/9/2024
📶
0
Knowledge Localization: Mission Not Accomplished? Enter Query Localization!
Yuheng Chen, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
Large language models (LLMs) store extensive factual knowledge, but the mechanisms behind how they store and express this knowledge remain unclear. The Knowledge Neuron (KN) thesis is a prominent theory for explaining these mechanisms. This theory is based on the knowledge localization (KL) assumption, which suggests that a fact can be localized to a few knowledge storage units, namely knowledge neurons. However, this assumption may be overly strong regarding knowledge storage and neglects knowledge expression mechanisms. Thus, we re-examine the KL assumption and confirm the existence of facts that do not adhere to it from both statistical and knowledge modification perspectives. Furthermore, we propose the Query Localization (QL) assumption. (1) Query-KN Mapping: The localization results are associated with the query rather than the fact. (2) Dynamic KN Selection: The attention module contributes to the selection of KNs for answering a query. Based on this, we further propose the Consistency-Aware KN modification method, which improves the performance of knowledge modification. We conduct 39 sets of experiments, along with additional visualization experiments, to rigorously validate our conclusions.
Read more5/24/2024