MEMLA: Enhancing Multilingual Knowledge Editing with Neuron-Masked Low-Rank Adaptation

0
Sign in to get full access
Overview
- Provides instructions for authors submitting papers to *ACL (Association for Computational Linguistics) conferences
- Covers key formatting, structure, and submission requirements
- Ensures consistent presentation and quality of published works
Plain English Explanation
These instructions outline the proper way to format and submit a paper for publication in a conference organized by the Association for Computational Linguistics (ACL). The goal is to ensure a consistent look and feel across all accepted papers, making it easier for readers to navigate and understand the research.
The instructions cover important details like the required structure of the paper, formatting of text and citations, and the submission process. Following these guidelines helps authors present their work in a clear and professional manner, which can improve the overall quality and impact of the published research.
Technical Explanation
The instructions provide a comprehensive set of guidelines for authors submitting papers to *ACL conferences. This includes requirements around paper structure, such as the inclusion of specific sections (e.g. introduction, related work, experiments) and formatting of headings.
There are also detailed instructions on text formatting, including font sizes, margins, and spacing. The instructions specify the required citation style and formatting for references. Finally, the document outlines the submission process, including deadlines, file formats, and any extra materials that must be provided.
Critical Analysis
The instructions provide clear and comprehensive guidance to help authors prepare their papers for *ACL conferences. The level of detail is appropriate and should ensure a consistent format across all accepted submissions.
One potential limitation is that the instructions may not fully account for emerging publication practices, such as the inclusion of code or data supplements. As research evolves, the instructions may need periodic updates to stay relevant.
Additionally, the instructions could be further improved by including more guidance on ethical considerations, such as responsible data use and potential societal impacts of the research. This would help authors think critically about these important issues.
Conclusion
These instructions serve an important role in maintaining the quality and consistency of publications in *ACL conferences. By providing authors with clear formatting and submission requirements, the instructions help ensure that accepted papers are presented in a clear and professional manner. This ultimately benefits the research community by making it easier to discover, understand, and build upon the published work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MEMLA: Enhancing Multilingual Knowledge Editing with Neuron-Masked Low-Rank Adaptation
Jiakuan Xie, Pengfei Cao, Yuheng Chen, Yubo Chen, Kang Liu, Jun Zhao
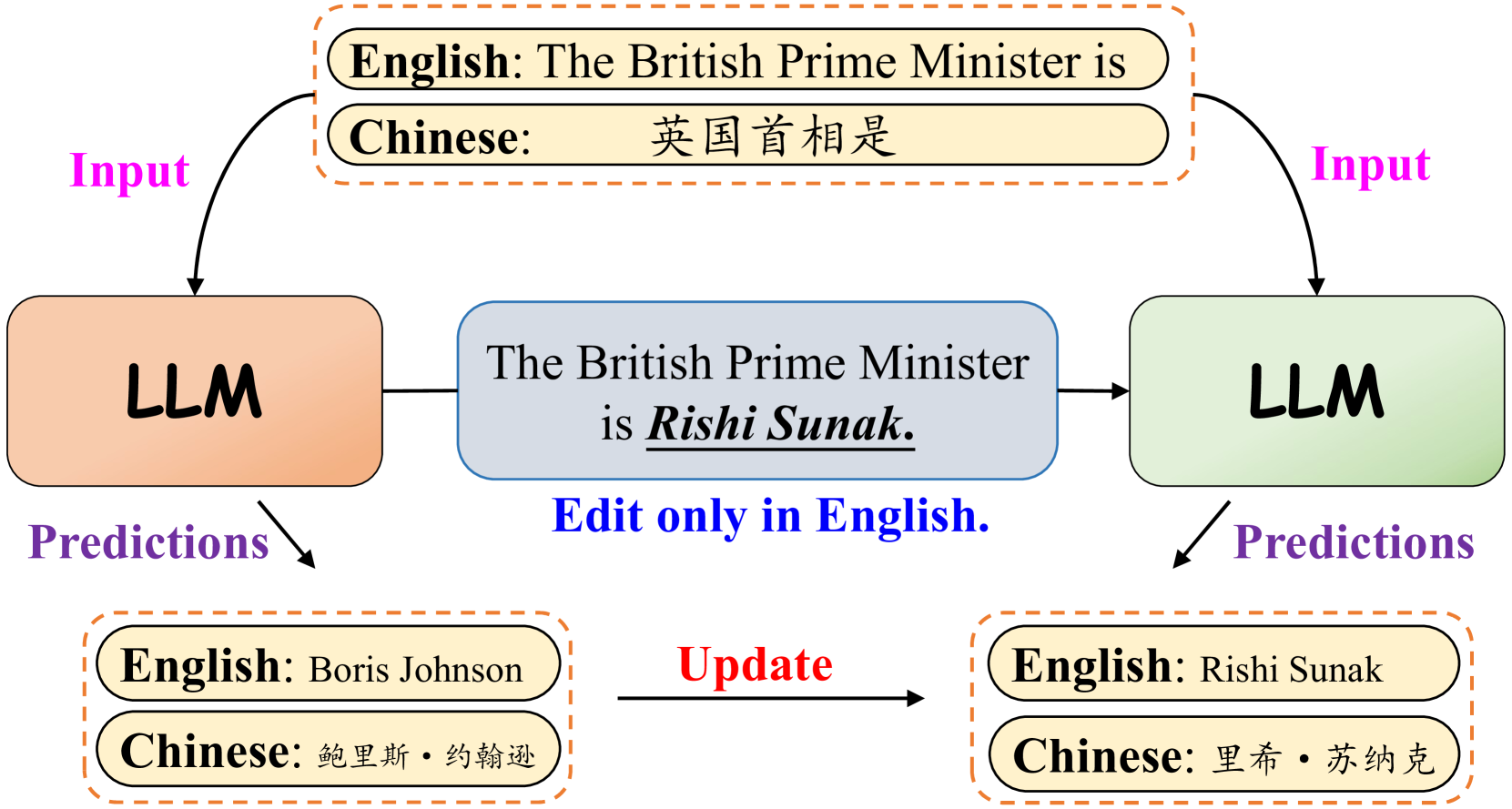
Knowledge editing aims to adjust the knowledge within large language models (LLMs) to prevent their responses from becoming obsolete or inaccurate. However, existing works on knowledge editing are primarily conducted in a single language, which is inadequate for multilingual language models. In this paper, we focus on multilingual knowledge editing (MKE), which requires propagating updates across multiple languages. This necessity poses a significant challenge for the task. Furthermore, the limited availability of a comprehensive dataset for MKE exacerbates this challenge, hindering progress in this area. Hence, we introduce the Multilingual Knowledge Editing Benchmark (MKEB), a novel dataset comprising 12 languages and providing a complete evaluation framework. Additionally, we propose a method that enhances Multilingual knowledge Editing with neuron-Masked Low-Rank Adaptation (MEMLA). Specifically, we identify two categories of knowledge neurons to improve editing precision. Moreover, we perform LoRA-based editing with neuron masks to efficiently modify parameters and facilitate the propagation of updates across multiple languages. Experiments demonstrate that our method outperforms existing baselines and significantly enhances the multi-hop reasoning capability of the edited model, with minimal impact on its downstream task performance. The dataset and code will be made publicly available.
Read more6/18/2024
0
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Zihao Wei, Jingcheng Deng, Liang Pang, Hanxing Ding, Huawei Shen, Xueqi Cheng
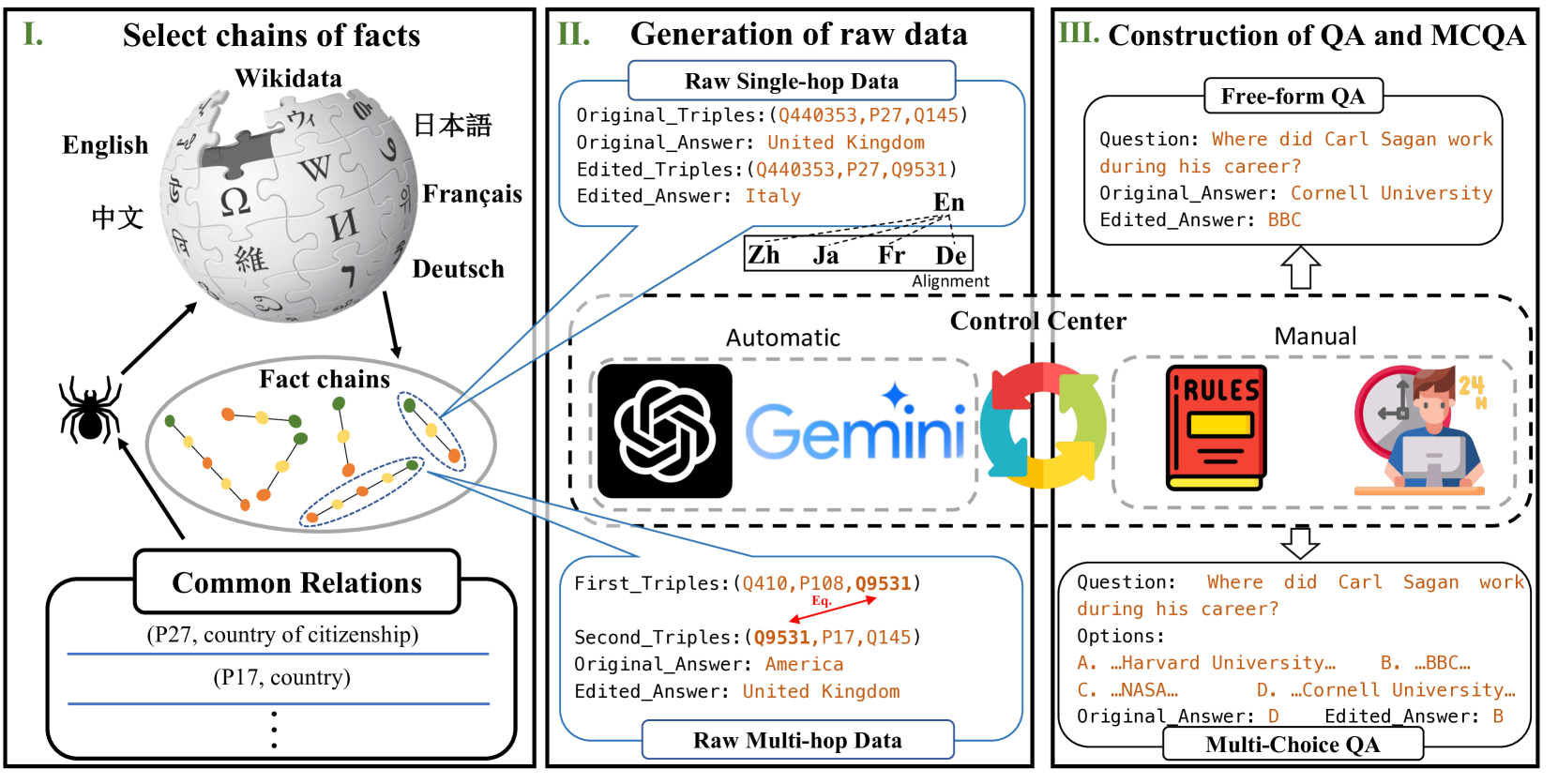
The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Read more4/9/2024

0
Multilingual Knowledge Editing with Language-Agnostic Factual Neurons
Xue zhang, Yunlong Liang, Fandong Meng, Songming Zhang, Yufeng Chen, Jinan Xu, Jie Zhou
Multilingual knowledge editing (MKE) aims to simultaneously revise factual knowledge across multilingual languages within large language models (LLMs). However, most existing MKE methods just adapt existing monolingual editing methods to multilingual scenarios, overlooking the deep semantic connections of the same factual knowledge between different languages, thereby limiting edit performance. To address this issue, we first investigate how LLMs represent multilingual factual knowledge and discover that the same factual knowledge in different languages generally activates a shared set of neurons, which we call language-agnostic factual neurons. These neurons represent the semantic connections between multilingual knowledge and are mainly located in certain layers. Inspired by this finding, we propose a new MKE method by locating and modifying Language-Agnostic Factual Neurons (LAFN) to simultaneously edit multilingual knowledge. Specifically, we first generate a set of paraphrases for each multilingual knowledge to be edited to precisely locate the corresponding language-agnostic factual neurons. Then we optimize the update values for modifying these located neurons to achieve simultaneous modification of the same factual knowledge in multiple languages. Experimental results on Bi-ZsRE and MzsRE benchmarks demonstrate that our method outperforms existing MKE methods and achieves remarkable edit performance, indicating the importance of considering the semantic connections among multilingual knowledge.
Read more6/26/2024
💬
1
Knowledge Editing for Large Language Models: A Survey
Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, Jundong Li
Large language models (LLMs) have recently transformed both the academic and industrial landscapes due to their remarkable capacity to understand, analyze, and generate texts based on their vast knowledge and reasoning ability. Nevertheless, one major drawback of LLMs is their substantial computational cost for pre-training due to their unprecedented amounts of parameters. The disadvantage is exacerbated when new knowledge frequently needs to be introduced into the pre-trained model. Therefore, it is imperative to develop effective and efficient techniques to update pre-trained LLMs. Traditional methods encode new knowledge in pre-trained LLMs through direct fine-tuning. However, naively re-training LLMs can be computationally intensive and risks degenerating valuable pre-trained knowledge irrelevant to the update in the model. Recently, Knowledge-based Model Editing (KME) has attracted increasing attention, which aims to precisely modify the LLMs to incorporate specific knowledge, without negatively influencing other irrelevant knowledge. In this survey, we aim to provide a comprehensive and in-depth overview of recent advances in the field of KME. We first introduce a general formulation of KME to encompass different KME strategies. Afterward, we provide an innovative taxonomy of KME techniques based on how the new knowledge is introduced into pre-trained LLMs, and investigate existing KME strategies while analyzing key insights, advantages, and limitations of methods from each category. Moreover, representative metrics, datasets, and applications of KME are introduced accordingly. Finally, we provide an in-depth analysis regarding the practicality and remaining challenges of KME and suggest promising research directions for further advancement in this field.
Read more9/23/2024