Multimodal Contrastive In-Context Learning

0
Sign in to get full access
Overview
- Researchers explore a new approach called "Multimodal Contrastive In-Context Learning" to improve the performance of language models on various tasks.
- The paper investigates how incorporating visual information alongside text can enhance a model's understanding and generation capabilities.
- The researchers conduct experiments to evaluate their proposed method and provide insights into the mechanisms underlying this multimodal learning approach.
Plain English Explanation
In this research, the authors investigate a new way to train language models that can better understand and generate text by incorporating visual information. The idea is that by showing the model not just the text, but also related images, it can learn to make more meaningful connections and produce higher-quality outputs.
The core of the approach is to have the model learn to identify visual-textual relationships through a "contrastive" learning process. This means the model is trained to distinguish the correct image-text pairs from incorrect pairings, helping it develop a stronger grasp of how visual and linguistic information are related.
By incorporating this multimodal context, the researchers found that language models could perform better on a variety of tasks, such as generating more coherent and relevant text. The key insight is that visual information provides additional context that can supplement the model's understanding in ways that purely text-based training cannot.
Technical Explanation
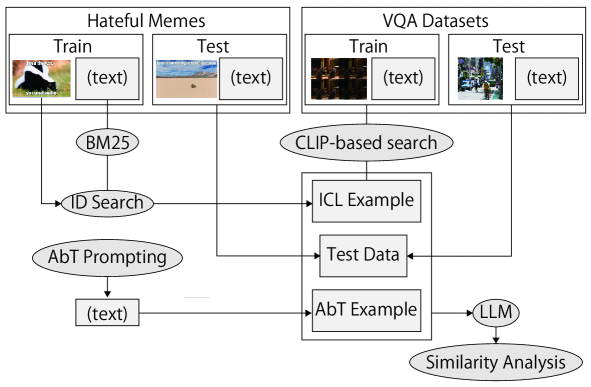
The paper introduces a new training approach called "Multimodal Contrastive In-Context Learning" (MCICL). The core idea is to have the language model learn visual-textual relationships by training it to distinguish correct image-text pairs from incorrect ones in a contrastive manner.
Specifically, the model is presented with a text prompt and multiple candidate images. It must learn to identify which image best matches the given text through a contrastive objective that encourages the model to assign higher scores to the correct image-text pairs.
The researchers hypothesize that this multimodal training process can help the language model develop a richer understanding of the content, leading to improved performance on various tasks compared to text-only training. They evaluate their MCICL approach on benchmarks for text generation, question answering, and other applications.
The results demonstrate that the MCICL-trained models outperform text-only baselines, highlighting the benefits of incorporating visual information to augment the language model's understanding and generation capabilities.
Critical Analysis
The paper presents a promising approach to improving language models by leveraging multimodal information. However, some potential limitations and areas for further research are worth considering:
- The experiments focus on controlled settings with curated image-text pairs. It would be valuable to explore how the MCICL approach generalizes to more diverse, real-world data sources.
- The paper does not delve deeply into the interpretability of the learned representations or the specific mechanisms by which the visual information benefits the language model. Further analysis in this direction could provide valuable insights.
- While the performance gains are demonstrated, the paper does not fully address potential trade-offs or computational costs associated with the multimodal training process.
Overall, the research presents an intriguing approach to leveraging multimodal information for language modeling and highlights the potential benefits of this line of inquiry. Continued exploration and refinement of the MCICL method could lead to further advancements in the field of natural language processing.
Conclusion
This paper introduces a novel training approach called Multimodal Contrastive In-Context Learning (MCICL) that aims to enhance language models by incorporating visual information alongside text. The key idea is to have the model learn to recognize the relationships between images and text through a contrastive objective, which can lead to improved performance on various language-based tasks.
The experimental results demonstrate the benefits of this multimodal learning approach, suggesting that the additional contextual cues provided by visual data can supplement and strengthen the language model's understanding. While further research is needed to fully explore the mechanisms and potential limitations, this work highlights the promising avenue of leveraging multimodal information to advance the capabilities of natural language processing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Contrastive In-Context Learning
Yosuke Miyanishi, Minh Le Nguyen
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
Read more8/26/2024
0
What Makes Multimodal In-Context Learning Work?
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. Code available at https://gitlab.com/folbaeni/multimodal-icl
Read more4/26/2024
💬
0
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun Gao, Qian Qiao, Ziqiang Cao, Zili Wang, Wenjie Li
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework textbf{AIM} to tackle the mentioned problems through textbf{A}ggregating textbf{I}mage information of textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
Read more7/2/2024
🌿
0
A Survey on In-context Learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, Zhifang Sui
With the increasing capabilities of large language models (LLMs), in-context learning (ICL) has emerged as a new paradigm for natural language processing (NLP), where LLMs make predictions based on contexts augmented with a few examples. It has been a significant trend to explore ICL to evaluate and extrapolate the ability of LLMs. In this paper, we aim to survey and summarize the progress and challenges of ICL. We first present a formal definition of ICL and clarify its correlation to related studies. Then, we organize and discuss advanced techniques, including training strategies, prompt designing strategies, and related analysis. Additionally, we explore various ICL application scenarios, such as data engineering and knowledge updating. Finally, we address the challenges of ICL and suggest potential directions for further research. We hope that our work can encourage more research on uncovering how ICL works and improving ICL.
Read more6/19/2024