Towards Multimodal In-Context Learning for Vision & Language Models

0
👀
Sign in to get full access
Overview
- State-of-the-art Vision-Language Models (VLMs) connect the visual and language domains by mapping vision tokens to language-like tokens, which are then fed to a Large Language Model (LLM) decoder.
- These VLMs have shown impressive performance on many zero-shot tasks like image captioning and question answering.
- However, little emphasis has been placed on transferring one of the core capabilities of LLMs - In-Context Learning (ICL).
- ICL is the ability of a model to reason about a downstream task using a few example demonstrations embedded in the prompt.
- Through extensive evaluations, the researchers found that current state-of-the-art VLMs lack the ability to effectively follow ICL instructions.
Plain English Explanation
Vision-Language Models (VLMs) are a type of artificial intelligence that can understand and connect the visual and language domains. For example, they can generate captions for images or answer questions about images. These VLMs have shown remarkable performance on many tasks where they don't need to be trained specifically for the task (known as "zero-shot" tasks).
However, the researchers found that these VLMs struggle with a particular capability called "In-Context Learning" (ICL). ICL is when a model can learn to perform a new task by just being given a few example demonstrations, without needing extensive training. This is a powerful capability that many language models possess, but the researchers discovered that current VLMs don't do this well.
To improve the ICL abilities of VLMs, the researchers developed a simple but effective training method that involves gradually building up the model's skills through a "curriculum-based learning" approach. This led to a significant 21% boost in ICL performance compared to the previous best VLMs.
The researchers also contributed new benchmarks for evaluating ICL in VLMs, which they say are better than previous methods. Overall, this work is an important step in making VLMs more capable of learning new tasks flexibly, just like humans can.
Technical Explanation
The researchers evaluated the in-context learning (ICL) capabilities of state-of-the-art Vision-Language Models (VLMs). VLMs connect the visual and language domains by projecting visual tokens from the encoder to language-like tokens, which are then fed to a Large Language Model (LLM) decoder.
While these VLMs have exhibited unprecedented performance on various zero-shot tasks, the researchers found that they somewhat lack the ability to effectively follow ICL instructions. Even models that underwent large-scale multimodal pre-training and were designed to leverage interleaved image and text information (to consume helpful context from multiple modalities) underperformed when prompted with few-shot demonstrations in an ICL setting.
To enhance the ICL abilities of VLMs, the researchers proposed a simple yet effective multi-turn curriculum-based learning methodology with carefully designed data mixes. This approach led to a significant 21.03% (and 11.3% on average) improvement in ICL performance over the strongest VLM baselines across a variety of ICL benchmarks.
Additionally, the researchers contributed new benchmarks for evaluating ICL in VLMs, which they argue offer advantages over prior art, such as better capturing the nuances of multimodal ICL.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work. First, they note that the proposed curriculum-based learning approach, while effective, is not the only way to enhance ICL capabilities in VLMs. Alternative methods, such as continual learning strategies, may also be explored.
Additionally, the researchers highlight that the new ICL benchmarks they introduced, while more comprehensive than previous ones, may still not fully capture the complexities of real-world multimodal reasoning tasks. [Further advancements in learnable context vectors and other techniques may be needed to truly assess the nuances of ICL in VLMs.
Overall, this work represents an important step in understanding and improving the in-context learning abilities of state-of-the-art Vision-Language Models. The insights and methodologies presented here can serve as a foundation for future research in this area, ultimately leading to more flexible and capable multimodal AI systems.
Conclusion
This research paper has revealed that while current state-of-the-art Vision-Language Models (VLMs) excel at many zero-shot tasks, they struggle with a core capability of large language models: in-context learning (ICL). ICL is the ability to learn new tasks using just a few example demonstrations, without extensive training.
The researchers developed a simple yet effective curriculum-based learning approach that significantly boosts the ICL performance of VLMs. They also contributed new benchmarks for evaluating ICL in multimodal settings, which can help drive further advancements in this area.
Overall, this work highlights the importance of developing VLMs that can flexibly learn new tasks, just like humans can. By bridging the gap between the visual and language domains while also empowering models with strong in-context learning abilities, the researchers have taken an important step towards creating more versatile and intelligent multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Towards Multimodal In-Context Learning for Vision & Language Models
Sivan Doveh, Shaked Perek, M. Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, Leonid Karlinsky
State-of-the-art Vision-Language Models (VLMs) ground the vision and the language modality primarily via projecting the vision tokens from the encoder to language-like tokens, which are directly fed to the Large Language Model (LLM) decoder. While these models have shown unprecedented performance in many downstream zero-shot tasks (eg image captioning, question answers, etc), still little emphasis has been put on transferring one of the core LLM capability of In-Context Learning (ICL). ICL is the ability of a model to reason about a downstream task with a few examples demonstrations embedded in the prompt. In this work, through extensive evaluations, we find that the state-of-the-art VLMs somewhat lack the ability to follow ICL instructions. In particular, we discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot demonstrations (in an ICL way), likely due to their lack of direct ICL instruction tuning. To enhance the ICL abilities of the present VLM, we propose a simple yet surprisingly effective multi-turn curriculum-based learning methodology with effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. Furthermore, we also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Read more7/18/2024
0
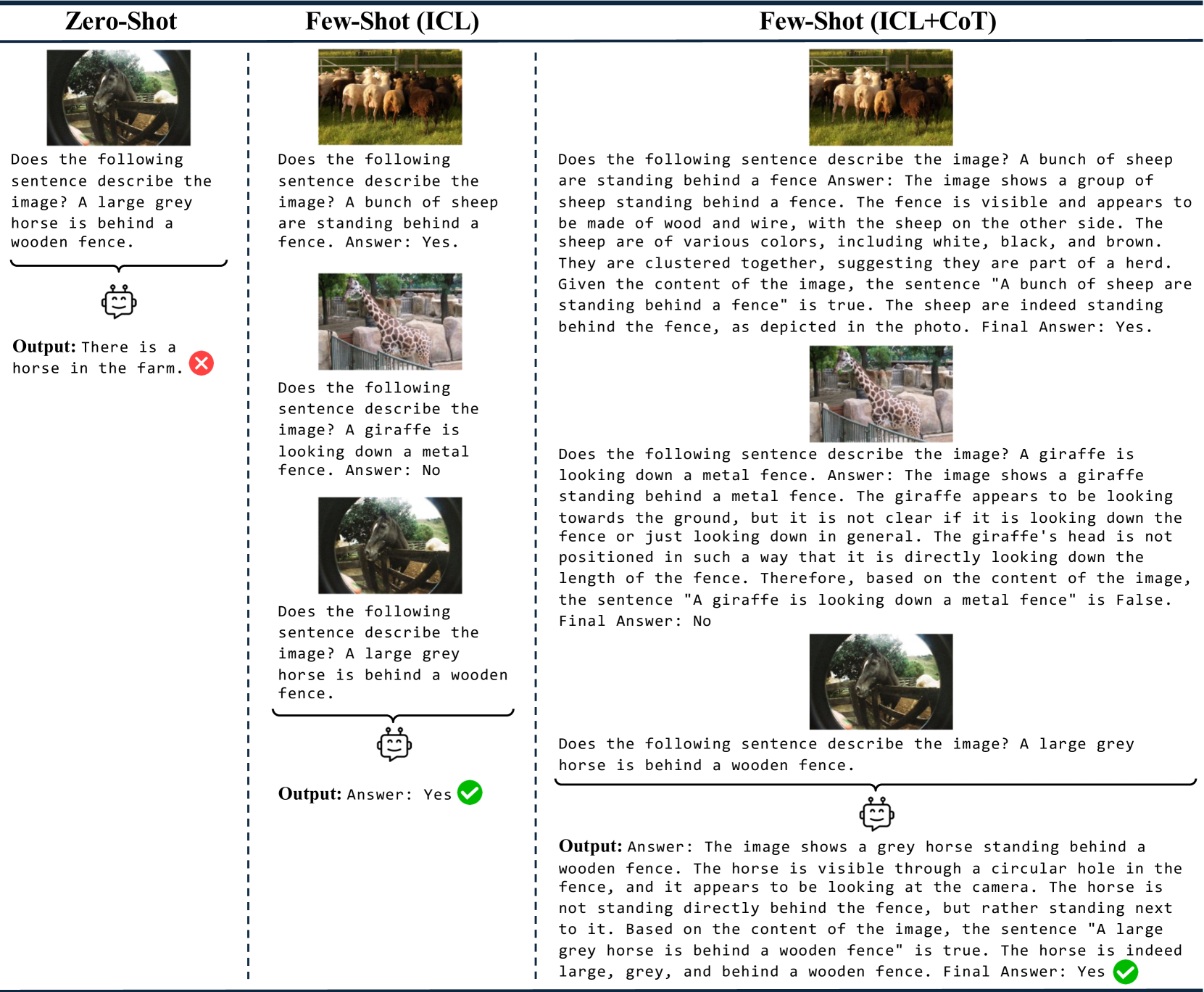
Evaluating Linguistic Capabilities of Multimodal LLMs in the Lens of Few-Shot Learning
Mustafa Dogan, Ilker Kesen, Iacer Calixto, Aykut Erdem, Erkut Erdem
The linguistic capabilities of Multimodal Large Language Models (MLLMs) are critical for their effective application across diverse tasks. This study aims to evaluate the performance of MLLMs on the VALSE benchmark, focusing on the efficacy of few-shot In-Context Learning (ICL), and Chain-of-Thought (CoT) prompting. We conducted a comprehensive assessment of state-of-the-art MLLMs, varying in model size and pretraining datasets. The experimental results reveal that ICL and CoT prompting significantly boost model performance, particularly in tasks requiring complex reasoning and contextual understanding. Models pretrained on captioning datasets show superior zero-shot performance, while those trained on interleaved image-text data benefit from few-shot learning. Our findings provide valuable insights into optimizing MLLMs for better grounding of language in visual contexts, highlighting the importance of the composition of pretraining data and the potential of few-shot learning strategies to improve the reasoning abilities of MLLMs.
Read more7/18/2024
💬
0
AIM: Let Any Multi-modal Large Language Models Embrace Efficient In-Context Learning
Jun Gao, Qian Qiao, Ziqiang Cao, Zili Wang, Wenjie Li
In-context learning (ICL) facilitates Large Language Models (LLMs) exhibiting emergent ability on downstream tasks without updating billions of parameters. However, in the area of multi-modal Large Language Models (MLLMs), two problems hinder the application of multi-modal ICL: (1) Most primary MLLMs are only trained on single-image datasets, making them unable to read multi-modal demonstrations. (2) With the demonstrations increasing, thousands of visual tokens highly challenge hardware and degrade ICL performance. During preliminary explorations, we discovered that the inner LLM tends to focus more on the linguistic modality within multi-modal demonstrations to generate responses. Therefore, we propose a general and light-weighted framework textbf{AIM} to tackle the mentioned problems through textbf{A}ggregating textbf{I}mage information of textbf{M}ultimodal demonstrations to the dense latent space of the corresponding linguistic part. Specifically, AIM first uses the frozen backbone MLLM to read each image-text demonstration and extracts the vector representations on top of the text. These vectors naturally fuse the information of the image-text pair, and AIM transforms them into fused virtual tokens acceptable for the inner LLM via a trainable projection layer. Ultimately, these fused tokens function as variants of multi-modal demonstrations, fed into the MLLM to direct its response to the current query as usual. Because these fused tokens stem from the textual component of the image-text pair, a multi-modal demonstration is nearly reduced to a pure textual demonstration, thus seamlessly applying to any MLLMs. With its de facto MLLM frozen, AIM is parameter-efficient and we train it on public multi-modal web corpora which have nothing to do with downstream test tasks.
Read more7/2/2024
0
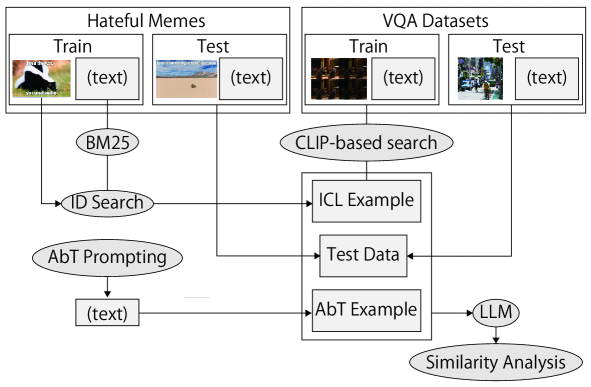
Multimodal Contrastive In-Context Learning
Yosuke Miyanishi, Minh Le Nguyen
The rapid growth of Large Language Models (LLMs) usage has highlighted the importance of gradient-free in-context learning (ICL). However, interpreting their inner workings remains challenging. This paper introduces a novel multimodal contrastive in-context learning framework to enhance our understanding of ICL in LLMs. First, we present a contrastive learning-based interpretation of ICL in real-world settings, marking the distance of the key-value representation as the differentiator in ICL. Second, we develop an analytical framework to address biases in multimodal input formatting for real-world datasets. We demonstrate the effectiveness of ICL examples where baseline performance is poor, even when they are represented in unseen formats. Lastly, we propose an on-the-fly approach for ICL (Anchored-by-Text ICL) that demonstrates effectiveness in detecting hateful memes, a task where typical ICL struggles due to resource limitations. Extensive experiments on multimodal datasets reveal that our approach significantly improves ICL performance across various scenarios, such as challenging tasks and resource-constrained environments. Moreover, it provides valuable insights into the mechanisms of in-context learning in LLMs. Our findings have important implications for developing more interpretable, efficient, and robust multimodal AI systems, especially in challenging tasks and resource-constrained environments.
Read more8/26/2024