Multimodal Emotion Recognition using Audio-Video Transformer Fusion with Cross Attention

0
👁️
Sign in to get full access
Overview
- Emotion recognition is crucial for human communication
- Combining audio and video signals can provide a more comprehensive understanding of emotional states
- Multimodal emotion recognition faces challenges with synchronization, feature extraction, and data fusion
Plain English Explanation
Recognizing and understanding emotions is a fundamental part of how humans communicate with each other. Using both audio and video signals can give us a more complete picture of a person's emotional state, compared to just looking at things like speech or facial expressions alone.
However, developing systems that can effectively combine these different types of data sources to recognize emotions faces some significant challenges. Getting the audio and video signals properly synchronized, extracting the most relevant features from each type of data, and then fusing them together in a way that provides accurate emotion recognition is quite difficult.
Technical Explanation
To address these challenges, the researchers introduce a new transformer-based model called Audio-Video Transformer Fusion with Cross Attention (AVT-CA). The AVT-CA model uses a transformer fusion approach to effectively capture and synchronize the interconnected features from both audio and video inputs. This helps resolve the synchronization problems that can arise when working with multimodal data.
Additionally, the Cross Attention mechanism within AVT-CA selectively extracts and emphasizes the most critical features from both the audio and video modalities, while discarding irrelevant ones. This helps address the feature extraction and fusion challenges inherent in multimodal emotion recognition.
The researchers conducted extensive experiments on several benchmark datasets, including CMU-MOSEI, RAVDESS, and CREMA-D. The results demonstrate the effectiveness of the AVT-CA model in developing precise and reliable multimodal emotion recognition systems for practical applications.
Critical Analysis
The paper provides a thorough and well-designed approach to addressing the key challenges in multimodal emotion recognition. The use of transformer-based fusion and cross-attention mechanisms appears to be a promising direction for improving the performance and robustness of these types of systems.
However, the paper does not delve deeply into the potential limitations or caveats of the proposed model. For example, it would be useful to understand how the AVT-CA model might perform in real-world scenarios with noisy or incomplete data, or how it compares to other state-of-the-art multimodal emotion recognition approaches.
Additionally, the researchers could have explored the potential biases or ethical considerations that might arise from deploying such emotion recognition systems in practical applications. These are important factors to consider as the technology becomes more widely adopted.
Conclusion
This paper presents a novel transformer-based model, AVT-CA, that effectively addresses the synchronization, feature extraction, and fusion challenges in multimodal emotion recognition. The experimental results demonstrate the model's ability to achieve high accuracy in emotion recognition tasks, which could have important implications for improving human-computer interaction and communication in various applications.
While the technical approach appears sound, the paper could have benefited from a more critical analysis of the model's limitations and potential ethical considerations. Nonetheless, the research represents a significant advance in the field of multimodal emotion recognition and lays the groundwork for further developments in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
Multimodal Emotion Recognition using Audio-Video Transformer Fusion with Cross Attention
Joe Dhanith P R, Shravan Venkatraman, Modigari Narendra, Vigya Sharma, Santhosh Malarvannan, Amir H. Gandomi
Understanding emotions is a fundamental aspect of human communication. Integrating audio and video signals offers a more comprehensive understanding of emotional states compared to traditional methods that rely on a single data source, such as speech or facial expressions. Despite its potential, multimodal emotion recognition faces significant challenges, particularly in synchronization, feature extraction, and fusion of diverse data sources. To address these issues, this paper introduces a novel transformer-based model named Audio-Video Transformer Fusion with Cross Attention (AVT-CA). The AVT-CA model employs a transformer fusion approach to effectively capture and synchronize interlinked features from both audio and video inputs, thereby resolving synchronization problems. Additionally, the Cross Attention mechanism within AVT-CA selectively extracts and emphasizes critical features while discarding irrelevant ones from both modalities, addressing feature extraction and fusion challenges. Extensive experimental analysis conducted on the CMU-MOSEI, RAVDESS and CREMA-D datasets demonstrates the efficacy of the proposed model. The results underscore the importance of AVT-CA in developing precise and reliable multimodal emotion recognition systems for practical applications.
Read more8/16/2024
👁️
0
Cross Attentional Audio-Visual Fusion for Dimensional Emotion Recognition
R. Gnana Praveen, Eric Granger, Patrick Cardinal
Multimodal analysis has recently drawn much interest in affective computing, since it can improve the overall accuracy of emotion recognition over isolated uni-modal approaches. The most effective techniques for multimodal emotion recognition efficiently leverage diverse and complimentary sources of information, such as facial, vocal, and physiological modalities, to provide comprehensive feature representations. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos, where complex spatiotemporal relationships may be captured. Most of the existing fusion techniques rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complimentary nature of audio-visual (A-V) modalities. We introduce a cross-attentional fusion approach to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. Our new cross-attentional A-V fusion model efficiently leverages the inter-modal relationships. In particular, it computes cross-attention weights to focus on the more contributive features across individual modalities, and thereby combine contributive feature representations, which are then fed to fully connected layers for the prediction of valence and arousal. The effectiveness of the proposed approach is validated experimentally on videos from the RECOLA and Fatigue (private) data-sets. Results indicate that our cross-attentional A-V fusion model is a cost-effective approach that outperforms state-of-the-art fusion approaches. Code is available: url{https://github.com/praveena2j/Cross-Attentional-AV-Fusion}
Read more7/9/2024
📈
0
A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Wheidima Carneiro de Melo, Nasib Ullah, Haseeb Aslam, Osama Zeeshan, Th'eo Denorme, Marco Pedersoli, Alessandro Koerich, Simon Bacon, Patrick Cardinal, Eric Granger
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.
Read more7/9/2024
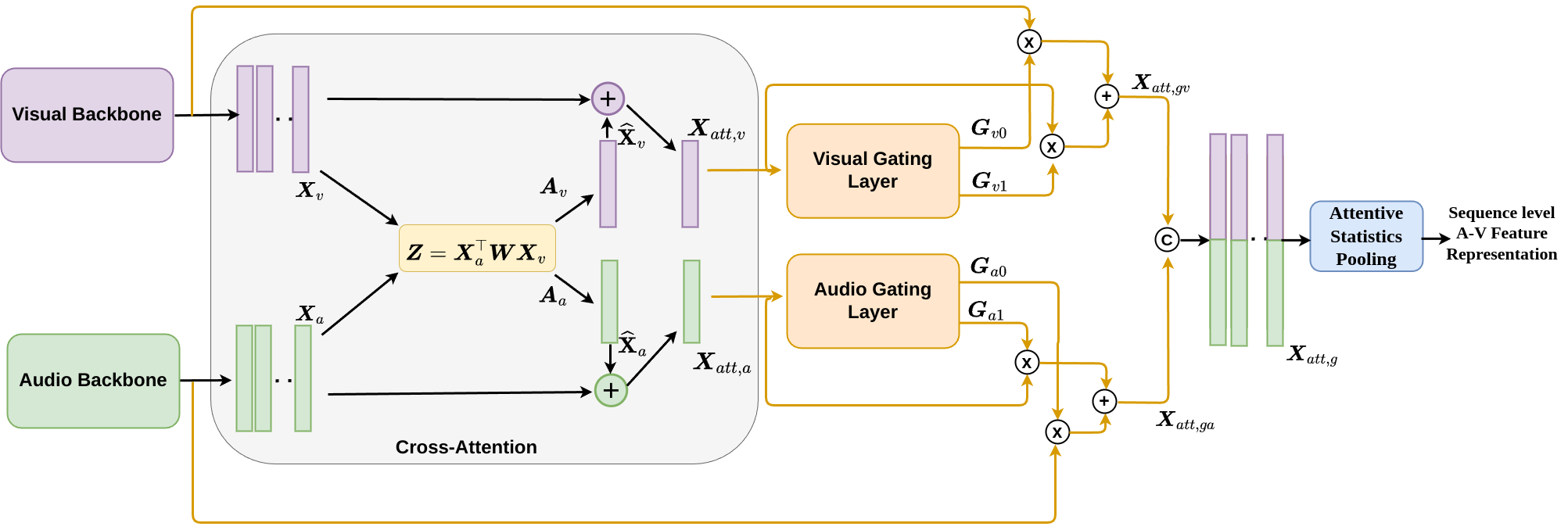
0
Dynamic Cross Attention for Audio-Visual Person Verification
R. Gnana Praveen, Jahangir Alam
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
Read more4/23/2024