A Multimodal Framework for the Assessment of the Schizophrenia Spectrum
2406.09706
0
0

Abstract
This paper presents a novel multimodal framework to distinguish between different symptom classes of subjects in the schizophrenia spectrum and healthy controls using audio, video, and text modalities. We implemented Convolution Neural Network and Long Short Term Memory based unimodal models and experimented on various multimodal fusion approaches to come up with the proposed framework. We utilized a minimal Gated multimodal unit (mGMU) to obtain a bi-modal intermediate fusion of the features extracted from the input modalities before finally fusing the outputs of the bimodal fusions to perform subject-wise classifications. The use of mGMU units in the multimodal framework improved the performance in both weighted f1-score and weighted AUC-ROC scores.
Create account to get full access
Overview
- This paper presents a multimodal framework for assessing the schizophrenia spectrum disorder.
- The researchers used a dataset of MRI scans, speech samples, and clinical assessments to train a machine learning model to identify individuals with schizophrenia or related disorders.
- The model combines information from different modalities (brain imaging, speech, clinical data) to make more accurate predictions than using any single modality alone.
- The researchers believe this approach could lead to improved diagnosis and monitoring of schizophrenia spectrum disorders.
Plain English Explanation
Schizophrenia is a serious mental health condition that can be difficult to diagnose and manage. The symptoms of schizophrenia can vary widely between individuals, making it challenging for healthcare providers to accurately assess and treat the disorder.
In this research, the authors developed a new approach that combines different types of information to get a more complete picture of a person's mental health. They used brain scans, speech samples, and clinical assessments to train a machine learning model to identify individuals with schizophrenia or related disorders.
The key idea is that by looking at multiple factors, the model can make more accurate predictions than if it only considered one type of information, like a brain scan or a patient's self-reported symptoms. This multimodal approach allows the researchers to get a more holistic understanding of a person's mental health status.
The researchers believe this framework could lead to improvements in how schizophrenia is diagnosed and monitored over time. By combining different types of data, healthcare providers may be able to make more informed decisions about treatment and better support individuals living with this challenging condition.
Technical Explanation
The researchers used a dataset that included MRI scans, speech samples, and clinical assessments for individuals with schizophrenia spectrum disorders as well as healthy controls. They developed a multimodal machine learning model that could integrate information from these different data sources to predict whether a person had a schizophrenia spectrum disorder.
The model first processed each data modality (brain imaging, speech, clinical) independently using specialized neural network architectures. It then combined the representations learned from each modality through a fusion module to make the final classification prediction.
The researchers found that this multimodal approach outperformed models that relied on any single data modality alone. They attribute this improved performance to the model's ability to capture complementary information from the different data sources, providing a more comprehensive assessment of schizophrenia-related symptoms and characteristics.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the dataset used was relatively small, which may limit the generalizability of the findings. Larger and more diverse datasets will be needed to further validate the model's performance.
Additionally, the paper does not provide a detailed analysis of the specific contributions of each data modality to the model's predictions. Understanding which types of information are most useful for identifying schizophrenia spectrum disorders could help guide future research and clinical applications of this approach.
It would also be valuable to assess the model's ability to detect early signs of schizophrenia or track changes in symptoms over time. This could help demonstrate the potential clinical utility of the multimodal framework for improved disease monitoring and management.
Overall, this research represents an important step towards leveraging diverse data sources to enhance the assessment and understanding of complex mental health conditions like schizophrenia. Further development and validation of this approach could lead to more accurate and personalized care for individuals affected by these disorders.
Conclusion
This paper presents a promising multimodal framework for assessing schizophrenia spectrum disorders. By combining information from brain imaging, speech, and clinical data, the researchers developed a machine learning model that can more accurately identify individuals with these mental health conditions compared to using any single data source alone.
The researchers believe this approach could lead to improved diagnosis, monitoring, and ultimately, better treatment and support for people living with schizophrenia. While further research is needed to address the limitations and expand the applications of this framework, this work represents an important advancement in the use of multimodal data to enhance our understanding and management of complex mental health disorders.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A multi-modal approach for identifying schizophrenia using cross-modal attention
Gowtham Premananth, Yashish M. Siriwardena, Philip Resnik, Carol Espy-Wilson
0
0
This study focuses on how different modalities of human communication can be used to distinguish between healthy controls and subjects with schizophrenia who exhibit strong positive symptoms. We developed a multi-modal schizophrenia classification system using audio, video, and text. Facial action units and vocal tract variables were extracted as low-level features from video and audio respectively, which were then used to compute high-level coordination features that served as the inputs to the audio and video modalities. Context-independent text embeddings extracted from transcriptions of speech were used as the input for the text modality. The multi-modal system is developed by fusing a segment-to-session-level classifier for video and audio modalities with a text model based on a Hierarchical Attention Network (HAN) with cross-modal attention. The proposed multi-modal system outperforms the previous state-of-the-art multi-modal system by 8.53% in the weighted average F1 score.
4/22/2024

U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation
Bingyu Li, Da Zhang, Zhiyuan Zhao, Junyu Gao, Xuelong Li
0
0
Multimodal semantic segmentation is a pivotal component of computer vision and typically surpasses unimodal methods by utilizing rich information set from various sources.Current models frequently adopt modality-specific frameworks that inherently biases toward certain modalities. Although these biases might be advantageous in specific situations, they generally limit the adaptability of the models across different multimodal contexts, thereby potentially impairing performance. To address this issue, we leverage the inherent capabilities of the model itself to discover the optimal equilibrium in multimodal fusion and introduce U3M: An Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation. Specifically, this method involves an unbiased integration of multimodal visual data. Additionally, we employ feature fusion at multiple scales to ensure the effective extraction and integration of both global and local features. Experimental results demonstrate that our approach achieves superior performance across multiple datasets, verifing its efficacy in enhancing the robustness and versatility of semantic segmentation in diverse settings. Our code is available at U3M-multimodal-semantic-segmentation.
5/27/2024
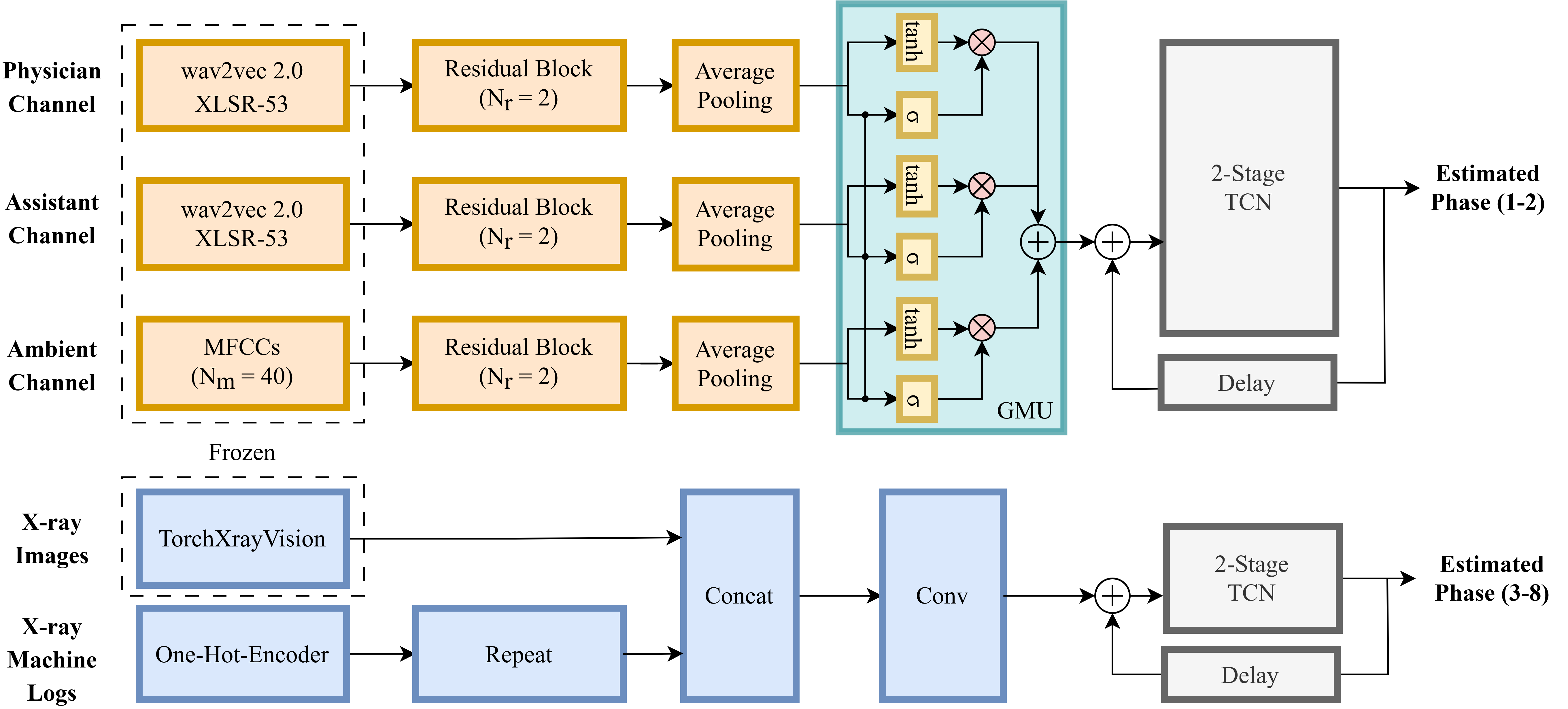
Towards Intelligent Speech Assistants in Operating Rooms: A Multimodal Model for Surgical Workflow Analysis
Kubilay Can Demir, Belen Lojo Rodriguez, Tobias Weise, Andreas Maier, Seung Hee Yang
0
0
To develop intelligent speech assistants and integrate them seamlessly with intra-operative decision-support frameworks, accurate and efficient surgical phase recognition is a prerequisite. In this study, we propose a multimodal framework based on Gated Multimodal Units (GMU) and Multi-Stage Temporal Convolutional Networks (MS-TCN) to recognize surgical phases of port-catheter placement operations. Our method merges speech and image models and uses them separately in different surgical phases. Based on the evaluation of 28 operations, we report a frame-wise accuracy of 92.65 $pm$ 3.52% and an F1-score of 92.30 $pm$ 3.82%. Our results show approximately 10% improvement in both metrics over previous work and validate the effectiveness of integrating multimodal data for the surgical phase recognition task. We further investigate the contribution of individual data channels by comparing mono-modal models with multimodal models.
6/24/2024
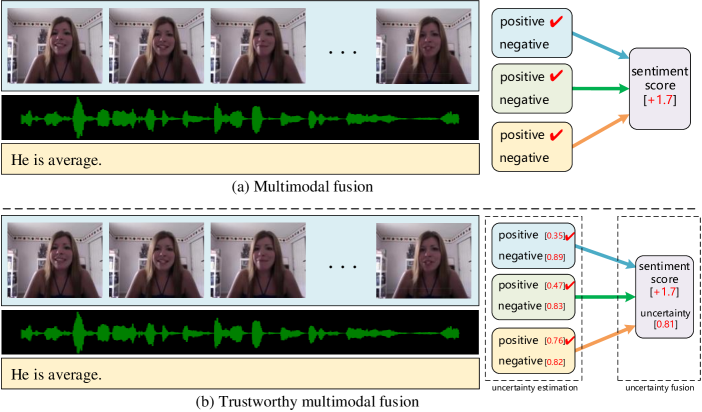
Trustworthy Multimodal Fusion for Sentiment Analysis in Ordinal Sentiment Space
Zhuyang Xie, Yan Yang, Jie Wang, Xiaorong Liu, Xiaofan Li
0
0
Multimodal video sentiment analysis aims to integrate multiple modal information to analyze the opinions and attitudes of speakers. Most previous work focuses on exploring the semantic interactions of intra- and inter-modality. However, these works ignore the reliability of multimodality, i.e., modalities tend to contain noise, semantic ambiguity, missing modalities, etc. In addition, previous multimodal approaches treat different modalities equally, largely ignoring their different contributions. Furthermore, existing multimodal sentiment analysis methods directly regress sentiment scores without considering ordinal relationships within sentiment categories, with limited performance. To address the aforementioned problems, we propose a trustworthy multimodal sentiment ordinal network (TMSON) to improve performance in sentiment analysis. Specifically, we first devise a unimodal feature extractor for each modality to obtain modality-specific features. Then, an uncertainty distribution estimation network is customized, which estimates the unimodal uncertainty distributions. Next, Bayesian fusion is performed on the learned unimodal distributions to obtain multimodal distributions for sentiment prediction. Finally, an ordinal-aware sentiment space is constructed, where ordinal regression is used to constrain the multimodal distributions. Our proposed TMSON outperforms baselines on multimodal sentiment analysis tasks, and empirical results demonstrate that TMSON is capable of reducing uncertainty to obtain more robust predictions.
4/16/2024