Multimodal Label Relevance Ranking via Reinforcement Learning

0

Sign in to get full access
Overview
- This paper proposes a reinforcement learning-based approach for ranking the relevance of labels in a multimodal setting.
- The authors aim to learn a policy that can effectively rank the relevance of labels for a given input, combining information from multiple modalities.
- The proposed method leverages reinforcement learning to learn the ranking policy, with the goal of maximizing the relevance of the top-ranked labels.
Plain English Explanation
The paper discusses a new way to rank how relevant different labels are for a given input, such as an image or document. This is an important task in many real-world applications, like recommending relevant tags for an image or identifying the most salient information in a long text.
The key idea is to use reinforcement learning to train a model that can look at the input and the available labels, and then rank the labels in order of how relevant they are. The model learns this ranking policy by trial-and-error, trying different rankings and getting rewarded when it puts the most relevant labels at the top.
This reinforcement learning approach has some advantages over traditional supervised learning methods. For one, it doesn't require manual labeling of the "correct" ranking for each input - the model can learn the ranking just by getting feedback on how good its current ranking is. Additionally, the reinforcement learning framework allows the model to directly optimize for the desired objective (i.e., having the most relevant labels at the top), rather than having to learn an intermediate task.
The authors demonstrate their approach on several multimodal datasets, showing that it can outperform other label ranking methods. This suggests that reinforcement learning could be a powerful tool for tackling complex real-world label ranking problems that involve multiple sources of information.
Technical Explanation
The paper presents a reinforcement learning-based approach for ranking the relevance of labels in a multimodal setting. The key components are:
-
Multimodal Representation: The input is represented using a combination of visual, textual, and other modality-specific features. These features are encoded using pre-trained neural networks.
-
Reinforcement Learning Policy: The authors train a neural network policy using reinforcement learning. This policy takes the multimodal input representation and the set of available labels as input, and outputs a ranking of the labels.
-
Reward Function: The policy is trained to maximize a reward function that encourages putting the most relevant labels at the top of the ranking. This reward function is designed to capture the desired properties of a good ranking, such as having the most relevant labels appear early in the list.
-
Training Procedure: The policy is trained using proximal policy optimization (PPO), a popular reinforcement learning algorithm. During training, the policy interacts with a simulated environment that provides feedback on the quality of the generated rankings.
The authors evaluate their approach on several multimodal datasets, including image-text and document-image datasets. They compare their reinforcement learning-based method to various supervised and unsupervised baselines, and show that it outperforms these alternatives on standard label ranking metrics.
Critical Analysis
The paper presents a novel and promising approach for multimodal label relevance ranking. The key strengths of the work include:
- Flexibility: The reinforcement learning framework allows the model to directly optimize for the desired ranking objective, without requiring manually annotated "correct" rankings during training.
- Generalization: The multimodal representation and the policy-based approach make the method applicable to a wide range of multimodal input types and label sets.
- Empirical Performance: The experiments demonstrate the effectiveness of the proposed approach compared to other state-of-the-art methods.
However, the paper also has some limitations:
- Sample Efficiency: Reinforcement learning can be sample-intensive, requiring a large number of training samples to learn an effective policy. The authors do not provide a detailed analysis of the sample complexity of their approach.
- Interpretability: As with many deep learning-based methods, the trained policy may be difficult to interpret and understand the underlying reasoning for the generated rankings.
- Domain-Specific Biases: The performance of the method may be sensitive to the characteristics of the datasets used for training and evaluation. Further investigation is needed to understand how it would generalize to a broader range of multimodal tasks and datasets.
Overall, this paper presents an interesting and promising approach to the important problem of multimodal label relevance ranking. The reinforcement learning framework offers some unique advantages, but more research is needed to fully understand its capabilities and limitations.
Conclusion
This paper introduces a novel reinforcement learning-based approach for ranking the relevance of labels in a multimodal setting. The key idea is to train a policy network that can effectively combine information from multiple modalities to generate rankings that maximize the relevance of the top-ranked labels.
The proposed method offers several advantages over traditional supervised learning approaches, such as the ability to directly optimize for the desired ranking objective and the flexibility to handle a wide range of multimodal input types. The experimental results demonstrate the effectiveness of the approach on several benchmark datasets.
While the paper presents a promising direction, there are still some open challenges and areas for further research, such as improving the sample efficiency of the reinforcement learning training process and enhancing the interpretability of the learned policies. Overall, this work contributes valuable insights to the field of multimodal learning and reinforcement learning, with potential applications in a variety of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Label Relevance Ranking via Reinforcement Learning
Taian Guo, Taolin Zhang, Haoqian Wu, Hanjun Li, Ruizhi Qiao, Xing Sun
Conventional multi-label recognition methods often focus on label confidence, frequently overlooking the pivotal role of partial order relations consistent with human preference. To resolve these issues, we introduce a novel method for multimodal label relevance ranking, named Label Relevance Ranking with Proximal Policy Optimization (LRtextsuperscript{2}PPO), which effectively discerns partial order relations among labels. LRtextsuperscript{2}PPO first utilizes partial order pairs in the target domain to train a reward model, which aims to capture human preference intrinsic to the specific scenario. Furthermore, we meticulously design state representation and a policy loss tailored for ranking tasks, enabling LRtextsuperscript{2}PPO to boost the performance of label relevance ranking model and largely reduce the requirement of partial order annotation for transferring to new scenes. To assist in the evaluation of our approach and similar methods, we further propose a novel benchmark dataset, LRMovieNet, featuring multimodal labels and their corresponding partial order data. Extensive experiments demonstrate that our LRtextsuperscript{2}PPO algorithm achieves state-of-the-art performance, proving its effectiveness in addressing the multimodal label relevance ranking problem. Codes and the proposed LRMovieNet dataset are publicly available at url{https://github.com/ChazzyGordon/LR2PPO}.
Read more7/19/2024
0
LiPO: Listwise Preference Optimization through Learning-to-Rank
Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mohammad Saleh, Simon Baumgartner, Jialu Liu, Peter J. Liu, Xuanhui Wang
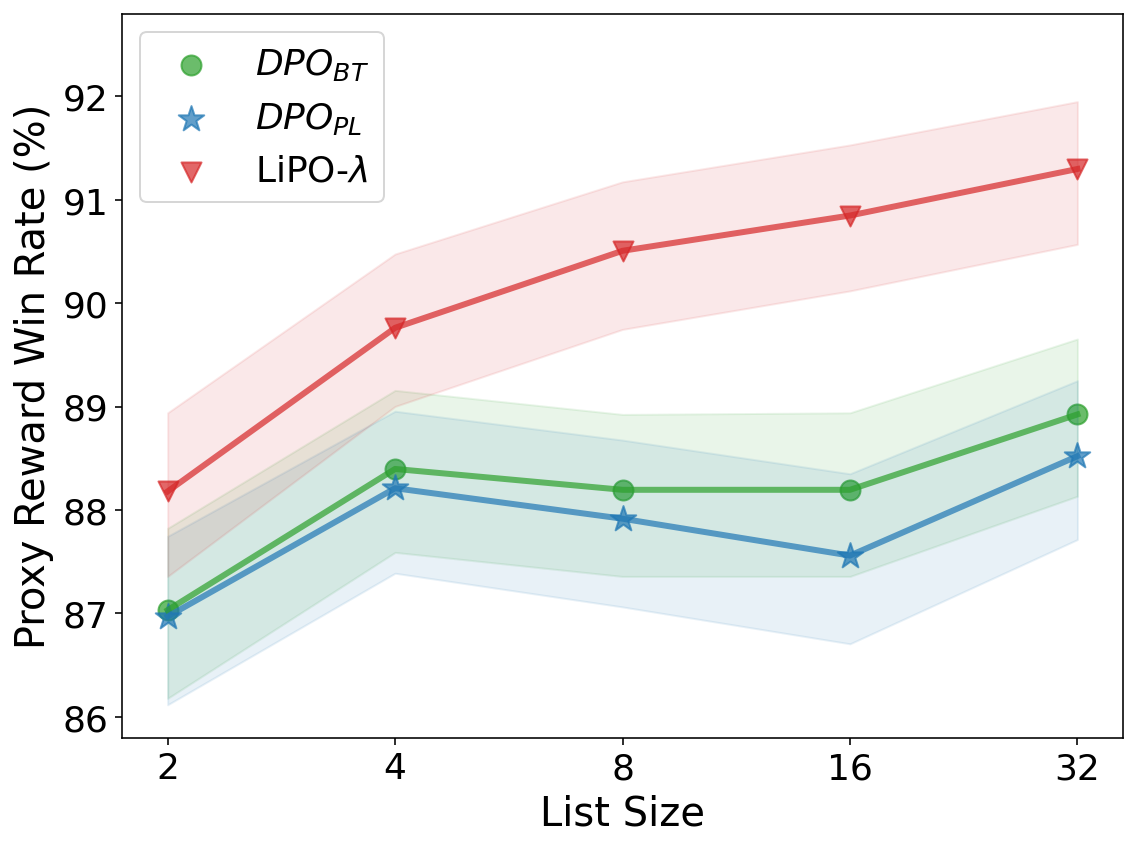
Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a thorough study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a textit{listwise} ranking problem and describe the LiPO framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment with DPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-$lambda$, which leverages a state-of-the-art textit{listwise} ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-$lambda$ can outperform DPO variants and SLiC by a clear margin on several preference alignment tasks with both curated and real rankwise preference data.
Read more5/24/2024
🏅
0
REBEL: Reinforcement Learning via Regressing Relative Rewards
Zhaolin Gao, Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Gokul Swamy, Kiant'e Brantley, Thorsten Joachims, J. Andrew Bagnell, Jason D. Lee, Wen Sun
While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications, including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping), and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative reward between two completions to a prompt in terms of the policy, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and be extended to handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally efficient than PPO. When fine-tuning Llama-3-8B-Instruct, REBEL achieves strong performance in AlpacaEval 2.0, MT-Bench, and Open LLM Leaderboard.
Read more9/4/2024

0
DPO Meets PPO: Reinforced Token Optimization for RLHF
Han Zhong, Guhao Feng, Wei Xiong, Xinle Cheng, Li Zhao, Di He, Jiang Bian, Liwei Wang
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
Read more7/23/2024