LiPO: Listwise Preference Optimization through Learning-to-Rank
2402.01878
0
0
Abstract
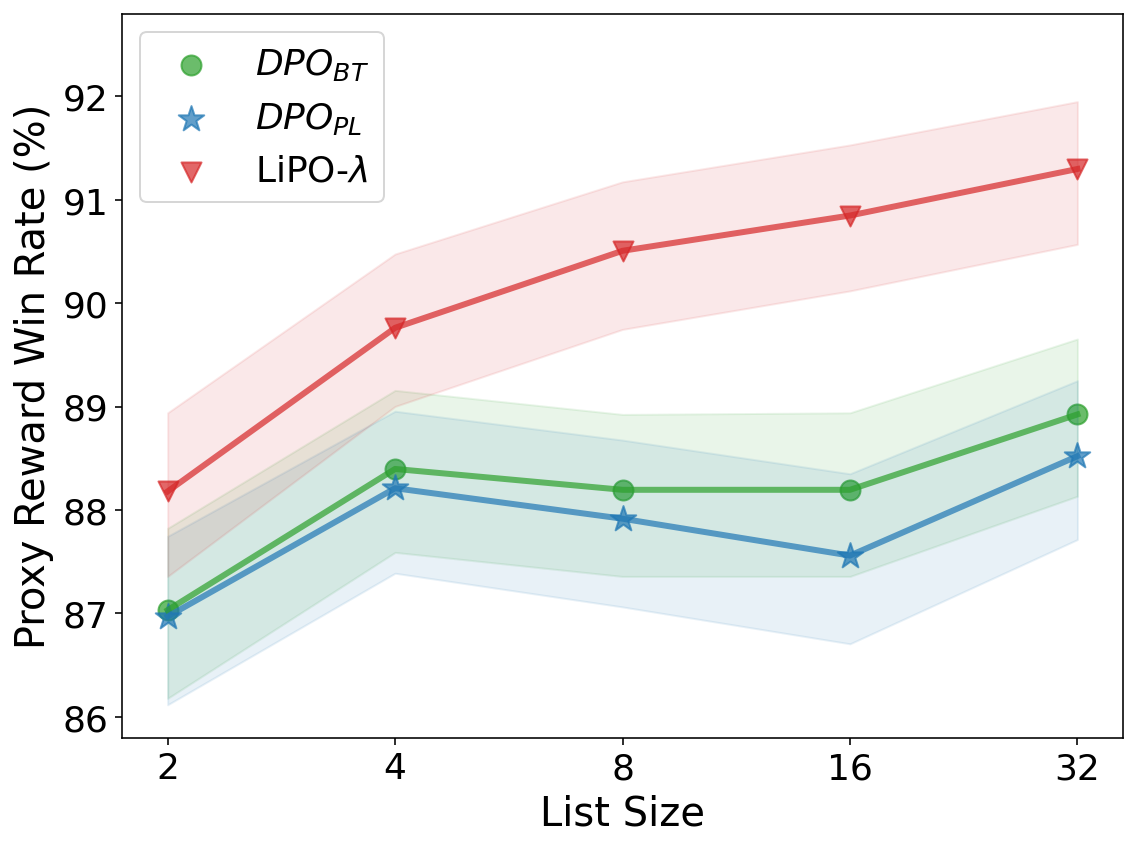
Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a thorough study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a textit{listwise} ranking problem and describe the LiPO framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment with DPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-$lambda$, which leverages a state-of-the-art textit{listwise} ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-$lambda$ can outperform DPO variants and SLiC by a clear margin on several preference alignment tasks with both curated and real rankwise preference data.
Create account to get full access
Overview
- This paper proposes a new framework called LiPO (Listwise Preference Optimization) for optimizing machine learning models to align with human preferences.
- LiPO uses a learning-to-rank approach to directly optimize a model's outputs to match a set of preference judgments provided by humans.
- The authors claim LiPO can achieve higher preference alignment than previous methods like token-level direct preference optimization or listwise reward enhancement.
Plain English Explanation
The key idea behind LiPO is to train a machine learning model to produce outputs that closely match the preferences expressed by humans. Rather than just trying to maximize some reward signal, the model is directly optimized to rank different options in the same order as human raters would.
Imagine you're building an AI assistant to recommend products or services. With LiPO, you could give the model a set of product comparisons made by real people - for example, "Product A is better than Product B, but Product C is the best." The model would then learn to output rankings that align with these human preferences, rather than just trying to predict high scores for the best products.
This listwise approach is claimed to be more effective than previous methods that optimize at the individual token level or try to shape the overall reward function. By directly targeting the model's ability to rank options correctly, LiPO can create AI systems that make choices more in line with human values and priorities.
Technical Explanation
The LiPO framework formulates preference optimization as a learning-to-rank problem. Given a set of ranked item lists (preferences) provided by human raters, the goal is to train a model that can produce rankings matching these preferences as closely as possible.
Specifically, LiPO uses a pairwise ranking loss to encourage the model's output scores for each item pair to match the relative preferences in the training data. This loss is combined with a standard cross-entropy term to ensure the model's overall ranking is well-calibrated.
The authors show that LiPO can outperform previous methods like token-level direct preference optimization and listwise reward enhancement on benchmark preference alignment tasks. They also demonstrate the approach's robustness to noisy or incomplete preference data.
Critical Analysis
The LiPO framework provides a principled way to directly optimize machine learning models for preference alignment, going beyond simple reward maximization. By framing the problem as learning-to-rank, the authors leverage well-established techniques from the information retrieval literature.
However, a potential limitation is the reliance on having a well-defined set of preference judgments from human raters. Collecting such data can be costly and time-consuming, especially for complex or subjective domains. The authors acknowledge this challenge and suggest future work on incorporating other forms of feedback, such as implicit preferences or active learning.
Additionally, the experiments in the paper focus on relatively simple item ranking tasks. It remains to be seen how well LiPO scales to more complex, open-ended preference alignment problems, such as those involving language model outputs or multi-modal inputs. Further research is needed to explore the broader applicability and limitations of the approach.
Conclusion
The LiPO framework represents an interesting advance in the field of preference-aligned machine learning. By directly optimizing a model's ranking outputs to match human preferences, it offers a promising approach for creating AI systems that make choices more in line with human values and priorities.
While the current work has some limitations, the authors have laid the groundwork for further research and development in this area. As the quest for AI alignment continues, techniques like LiPO could play an important role in ensuring that advanced AI systems behave in ways that are acceptable and beneficial to humanity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Relative Preference Optimization: Enhancing LLM Alignment through Contrasting Responses across Identical and Diverse Prompts
Yueqin Yin, Zhendong Wang, Yi Gu, Hai Huang, Weizhu Chen, Mingyuan Zhou
0
0
In the field of large language models (LLMs), aligning models with the diverse preferences of users is a critical challenge. Direct Preference Optimization (DPO) has played a key role in this area. It works by using pairs of preferences derived from the same prompts, and it functions without needing an additional reward model. However, DPO does not fully reflect the complex nature of human learning, which often involves understanding contrasting responses to not only identical but also similar questions. To overcome this shortfall, we propose Relative Preference Optimization (RPO). RPO is designed to discern between more and less preferred responses derived from both identical and related prompts. It introduces a contrastive weighting mechanism, enabling the tuning of LLMs using a broader range of preference data, including both paired and unpaired sets. This approach expands the learning capabilities of the model, allowing it to leverage insights from a more varied set of prompts. Through empirical tests, including dialogue and summarization tasks, and evaluations using the AlpacaEval2.0 leaderboard, RPO has demonstrated a superior ability to align LLMs with user preferences and to improve their adaptability during the training process. Our code can be viewed at https://github.com/yinyueqin/relative-preference-optimization
5/29/2024

New!Active Preference Learning for Large Language Models
William Muldrew, Peter Hayes, Mingtian Zhang, David Barber
0
0
As large language models (LLMs) become more capable, fine-tuning techniques for aligning with human intent are increasingly important. A key consideration for aligning these models is how to most effectively use human resources, or model resources in the case where LLMs themselves are used as oracles. Reinforcement learning from Human or AI preferences (RLHF/RLAIF) is the most prominent example of such a technique, but is complex and often unstable. Direct Preference Optimization (DPO) has recently been proposed as a simpler and more stable alternative. In this work, we develop an active learning strategy for DPO to make better use of preference labels. We propose a practical acquisition function for prompt/completion pairs based on the predictive entropy of the language model and a measure of certainty of the implicit preference model optimized by DPO. We demonstrate how our approach improves both the rate of learning and final performance of fine-tuning on pairwise preference data.
7/1/2024
Robust Preference Optimization with Provable Noise Tolerance for LLMs
Xize Liang, Chao Chen, Shuang Qiu, Jie Wang, Yue Wu, Zhihang Fu, Zhihao Shi, Feng Wu, Jieping Ye
0
0
Preference alignment is pivotal for empowering large language models (LLMs) to generate helpful and harmless responses. However, the performance of preference alignment is highly sensitive to the prevalent noise in the preference data. Recent efforts for this problem either marginally alleviate the impact of noise without the ability to actually reduce its presence, or rely on costly teacher LLMs prone to reward misgeneralization. To address these challenges, we propose the RObust Preference Optimization (ROPO) framework, an iterative alignment approach that integrates noise-tolerance and filtering of noisy samples without the aid of external models. Specifically, ROPO iteratively solves a constrained optimization problem, where we dynamically assign a quality-aware weight for each sample and constrain the sum of the weights to the number of samples we intend to retain. For noise-tolerant training and effective noise identification, we derive a robust loss by suppressing the gradients of samples with high uncertainty. We demonstrate both empirically and theoretically that the derived loss is critical for distinguishing noisy samples from clean ones. Furthermore, inspired by our derived loss, we propose a robustness-guided rejection sampling technique to compensate for the potential important information in discarded queries. Experiments on three widely-used datasets with Mistral-7B and Llama-2-7B demonstrate that ROPO significantly outperforms existing preference alignment methods, with its superiority growing as the noise rate increases.
5/29/2024
Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study
Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, Yi Wu
0
0
Reinforcement Learning from Human Feedback (RLHF) is currently the most widely used method to align large language models (LLMs) with human preferences. Existing RLHF methods can be roughly categorized as either reward-based or reward-free. Novel applications such as ChatGPT and Claude leverage reward-based methods that first learn a reward model and apply actor-critic algorithms, such as Proximal Policy Optimization (PPO). However, in academic benchmarks, state-of-the-art results are often achieved via reward-free methods, such as Direct Preference Optimization (DPO). Is DPO truly superior to PPO? Why does PPO perform poorly on these benchmarks? In this paper, we first conduct both theoretical and empirical studies on the algorithmic properties of DPO and show that DPO may have fundamental limitations. Moreover, we also comprehensively examine PPO and reveal the key factors for the best performances of PPO in fine-tuning LLMs. Finally, we benchmark DPO and PPO across a collection of RLHF testbeds, ranging from dialogue to code generation. Experiment results demonstrate that PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
4/23/2024