Multimodal Language Models for Domain-Specific Procedural Video Summarization

0

Sign in to get full access
Overview
- This paper presents a novel approach for domain-specific procedural video summarization using multimodal language models.
- The researchers fine-tuned large language models on domain-specific datasets to improve their ability to understand and summarize videos in that particular context.
- The approach combines visual and textual information to generate concise yet informative summaries of procedural videos, which could be useful for various applications like online tutorials or product assembly instructions.
Plain English Explanation
The researchers in this paper wanted to find a better way to automatically summarize instructional videos, like those for assembling furniture or cooking a meal. Existing video summarization techniques often struggle with these types of domain-specific videos, as they don't fully capture the step-by-step nature of the procedures being shown.
To address this, the researchers used large language models that had been trained on a huge amount of text data. They then "fine-tuned" these models on specific datasets related to the types of videos they wanted to summarize, like cooking or home repair. This allowed the models to better understand the language and concepts used in those domains.
The models also incorporated visual information from the videos, not just the text. By combining the visual and textual data, the researchers were able to create concise yet informative summaries of the key steps and actions in the procedural videos. This multimodal approach helps the models understand the full context of what's happening in the videos.
The end result is a system that can take a procedural video, analyze it, and generate a helpful summary that captures the essential information. This could be useful for things like online tutorials, product assembly instructions, or other applications where clear, step-by-step guidance is important.
Technical Explanation
The researchers in this paper tackled the challenge of domain-specific procedural video summarization using multimodal language models. They hypothesized that fine-tuning large language models on domain-specific datasets would improve their ability to generate concise yet informative summaries of procedural videos in those particular contexts.
To test this, the researchers used a pre-trained multimodal model as a starting point and fine-tuned it on datasets related to cooking, home repair, and other domains. This directed domain fine-tuning approach allowed the model to better understand the language, concepts, and visual cues associated with those types of procedural tasks.
The fine-tuned models were then evaluated on their ability to summarize procedural videos from the corresponding domains. The researchers found that the multimodal, domain-specific models outperformed generic video summarization approaches, producing summaries that were more accurate, concise, and aligned with the key steps and actions shown in the videos.
Critical Analysis
The research presented in this paper offers a promising approach for improving procedural video summarization, but it also has some limitations that should be considered.
One potential concern is the reliance on fine-tuning large language models, which can be computationally expensive and require access to sizable domain-specific datasets. This may limit the accessibility of the technique, especially for smaller organizations or individuals without significant resources.
Additionally, the paper does not deeply explore the impact of different fine-tuning strategies or the relative importance of the visual and textual modalities in the summarization process. Further research could investigate these aspects to optimize the approach and better understand the underlying mechanisms.
It would also be valuable to assess the summaries generated by the models through user studies, evaluating their usefulness, clarity, and alignment with human-generated summaries. This could help identify areas for improvement and ensure the summaries are truly beneficial for end-users.
Conclusion
This paper presents a novel approach for domain-specific procedural video summarization using multimodal language models. By fine-tuning large language models on specific datasets, the researchers were able to create models that could generate concise yet informative summaries of procedural videos, capturing the key steps and actions.
The multimodal nature of the approach, which combines visual and textual information, is a key strength, allowing the models to better understand the full context of the videos. This could have important applications in areas like online tutorials, product assembly instructions, and other domains where clear, step-by-step guidance is crucial.
While the research shows promising results, there are also some limitations that warrant further investigation, such as the computational requirements and the impact of different fine-tuning strategies. Ultimately, this work represents an important step forward in the field of video summarization, particularly for domain-specific, procedural content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Language Models for Domain-Specific Procedural Video Summarization
Nafisa Hussain
Videos serve as a powerful medium to convey ideas, tell stories, and provide detailed instructions, especially through long-format tutorials. Such tutorials are valuable for learning new skills at one's own pace, yet they can be overwhelming due to their length and dense content. Viewers often seek specific information, like precise measurements or step-by-step execution details, making it essential to extract and summarize key segments efficiently. An intelligent, time-sensitive video assistant capable of summarizing and detecting highlights in long videos is highly sought after. Recent advancements in Multimodal Large Language Models offer promising solutions to develop such an assistant. Our research explores the use of multimodal models to enhance video summarization and step-by-step instruction generation within specific domains. These models need to understand temporal events and relationships among actions across video frames. Our approach focuses on fine-tuning TimeChat to improve its performance in specific domains: cooking and medical procedures. By training the model on domain-specific datasets like Tasty for cooking and MedVidQA for medical procedures, we aim to enhance its ability to generate concise, accurate summaries of instructional videos. We curate and restructure these datasets to create high-quality video-centric instruction data. Our findings indicate that when finetuned on domain-specific procedural data, TimeChat can significantly improve the extraction and summarization of key instructional steps in long-format videos. This research demonstrates the potential of specialized multimodal models to assist with practical tasks by providing personalized, step-by-step guidance tailored to the unique aspects of each domain.
Read more7/9/2024
🏋️
0
Directed Domain Fine-Tuning: Tailoring Separate Modalities for Specific Training Tasks
Daniel Wen, Nafisa Hussain
Large language models (LLMs) and large visual language models (LVLMs) have been at the forefront of the artificial intelligence field, particularly for tasks like text generation, video captioning, and question-answering. Typically, it is more applicable to train these models on broader knowledge bases or datasets to increase generalizability, learn relationships between topics, and recognize patterns. Instead, we propose to provide instructional datasets specific to the task of each modality within a distinct domain and then fine-tune the parameters of the model using LORA. With our approach, we can eliminate all noise irrelevant to the given task while also ensuring that the model generates with enhanced precision. For this work, we use Video-LLaVA to generate recipes given cooking videos without transcripts. Video-LLaVA's multimodal architecture allows us to provide cooking images to its image encoder, cooking videos to its video encoder, and general cooking questions to its text encoder. Thus, we aim to remove all noise unrelated to cooking while improving our model's capabilities to generate specific ingredient lists and detailed instructions. As a result, our approach to fine-tuning Video-LLaVA leads to gains over the baseline Video-LLaVA by 2% on the YouCook2 dataset. While this may seem like a marginal increase, our model trains on an image instruction dataset 2.5% the size of Video-LLaVA's and a video instruction dataset 23.76% of Video-LLaVA's.
Read more6/26/2024
0
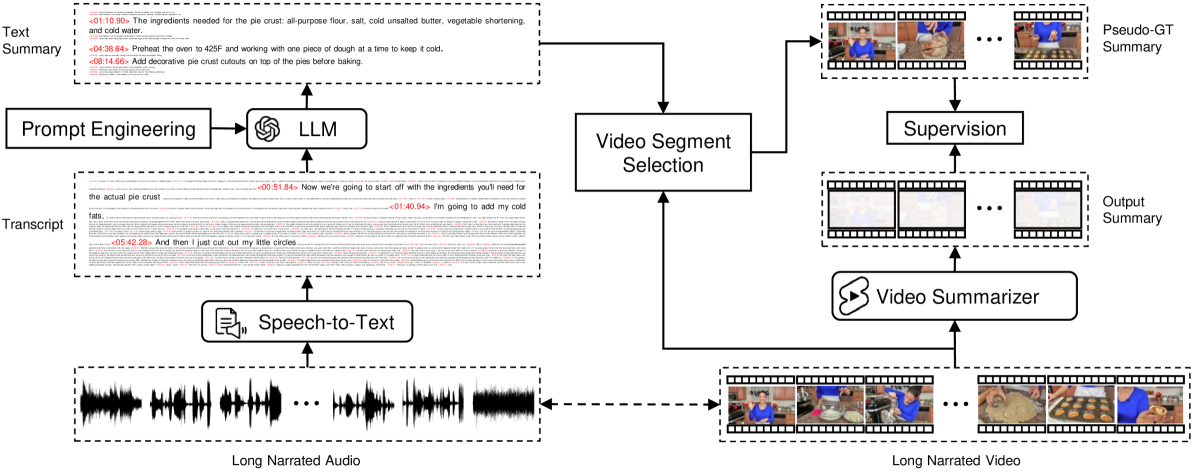
Scaling Up Video Summarization Pretraining with Large Language Models
Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
Long-form video content constitutes a significant portion of internet traffic, making automated video summarization an essential research problem. However, existing video summarization datasets are notably limited in their size, constraining the effectiveness of state-of-the-art methods for generalization. Our work aims to overcome this limitation by capitalizing on the abundance of long-form videos with dense speech-to-video alignment and the remarkable capabilities of recent large language models (LLMs) in summarizing long text. We introduce an automated and scalable pipeline for generating a large-scale video summarization dataset using LLMs as Oracle summarizers. By leveraging the generated dataset, we analyze the limitations of existing approaches and propose a new video summarization model that effectively addresses them. To facilitate further research in the field, our work also presents a new benchmark dataset that contains 1200 long videos each with high-quality summaries annotated by professionals. Extensive experiments clearly indicate that our proposed approach sets a new state-of-the-art in video summarization across several benchmarks.
Read more4/5/2024
🌐
0
Towards Multi-Task Multi-Modal Models: A Video Generative Perspective
Lijun Yu
Advancements in language foundation models have primarily fueled the recent surge in artificial intelligence. In contrast, generative learning of non-textual modalities, especially videos, significantly trails behind language modeling. This thesis chronicles our endeavor to build multi-task models for generating videos and other modalities under diverse conditions, as well as for understanding and compression applications. Given the high dimensionality of visual data, we pursue concise and accurate latent representations. Our video-native spatial-temporal tokenizers preserve high fidelity. We unveil a novel approach to mapping bidirectionally between visual observation and interpretable lexical terms. Furthermore, our scalable visual token representation proves beneficial across generation, compression, and understanding tasks. This achievement marks the first instances of language models surpassing diffusion models in visual synthesis and a video tokenizer outperforming industry-standard codecs. Within these multi-modal latent spaces, we study the design of multi-task generative models. Our masked multi-task transformer excels at the quality, efficiency, and flexibility of video generation. We enable a frozen language model, trained solely on text, to generate visual content. Finally, we build a scalable generative multi-modal transformer trained from scratch, enabling the generation of videos containing high-fidelity motion with the corresponding audio given diverse conditions. Throughout the course, we have shown the effectiveness of integrating multiple tasks, crafting high-fidelity latent representation, and generating multiple modalities. This work suggests intriguing potential for future exploration in generating non-textual data and enabling real-time, interactive experiences across various media forms.
Read more5/28/2024