Multimodal Methods for Analyzing Learning and Training Environments: A Systematic Literature Review

0

Sign in to get full access
Overview
- This paper presents a systematic literature review on the use of multimodal methods for analyzing learning and training environments.
- Multimodal data refers to the combination of different data modalities, such as audio, video, physiological signals, and behavioral data, to gain a more comprehensive understanding of a learning or training process.
- The review covers the key trends, methods, and applications of multimodal learning analytics in various educational and training contexts.
Plain English Explanation
The paper looks at how researchers are using multimodal data to study and improve learning and training environments. Multimodal data means collecting different types of information, like video, audio, physical measurements, and observational data, to get a more complete picture of what's happening.
For example, researchers might use multimodal large language models to analyze student engagement by looking at their facial expressions, tone of voice, and note-taking behavior during a lecture. Or they could use multimodal learning analytics to track how trainees in a simulation-based medical program are performing and adjust the training accordingly.
The review summarizes the key trends, techniques, and applications of this multimodal approach across various educational and training contexts. The goal is to understand how combining different data sources can provide deeper insights to help enhance the learning and training experience.
Technical Explanation
The paper presents a systematic literature review on the use of multimodal methods for analyzing learning and training environments. The review covers the key trends, methods, and applications of multimodal learning analytics (MMLA) in educational and training settings.
The researchers conducted a comprehensive search of relevant databases to identify peer-reviewed studies published between 2010 and 2022 that focused on the use of multimodal data and analytics for understanding and improving learning and training processes. They synthesized the findings from 97 papers that met the inclusion criteria.
The review examines how researchers are leveraging the combination of different data modalities, such as audio, video, physiological signals, and behavioral data, to gain a more holistic and nuanced understanding of learners' experiences, cognitive processes, and performance. It discusses the variety of sensors, wearable devices, and multimodal data fusion techniques employed in these studies.
The paper also outlines the key application areas of MMLA, including classroom interactions, online and distance learning, simulation-based training, and workplace learning. It highlights how multimodal analytics can provide insights into learner engagement, cognitive load, problem-solving strategies, and the effectiveness of instructional approaches.
Critical Analysis
The review provides a comprehensive overview of the current state of research on multimodal methods for analyzing learning and training environments. It suggests that the use of multimodal data and analytics is a promising approach for gaining deeper insights into complex learning processes and informing the design of more effective educational and training interventions.
However, the review also acknowledges some of the challenges and limitations associated with MMLA, such as the technical complexity of data collection and analysis, privacy concerns, and the need for interdisciplinary collaboration. It notes that the field is still relatively young, and more research is needed to establish best practices and standardize methodologies.
Additionally, the review does not delve into the potential biases and ethical considerations inherent in the use of multimodal data and analytics, particularly when it comes to issues of equity and access. As the use of these technologies becomes more widespread, it will be crucial to address these concerns and ensure that MMLA is implemented in a responsible and inclusive manner.
Conclusion
This systematic literature review highlights the growing interest and potential of multimodal methods for analyzing learning and training environments. By combining diverse data sources, researchers can gain a richer understanding of the complex cognitive, behavioral, and emotional processes involved in learning and skill development.
The review suggests that the application of multimodal learning analytics can lead to the design of more personalized, adaptive, and effective learning and training interventions. As the field continues to evolve, it will be important to address the technical, ethical, and practical challenges to ensure that these multimodal approaches are deployed in a responsible and equitable manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Methods for Analyzing Learning and Training Environments: A Systematic Literature Review
Clayton Cohn, Eduardo Davalos, Caleb Vatral, Joyce Horn Fonteles, Hanchen David Wang, Meiyi Ma, Gautam Biswas
Recent technological advancements have enhanced our ability to collect and analyze rich multimodal data (e.g., speech, video, and eye gaze) to better inform learning and training experiences. While previous reviews have focused on parts of the multimodal pipeline (e.g., conceptual models and data fusion), a comprehensive literature review on the methods informing multimodal learning and training environments has not been conducted. This literature review provides an in-depth analysis of research methods in these environments, proposing a taxonomy and framework that encapsulates recent methodological advances in this field and characterizes the multimodal domain in terms of five modality groups: Natural Language, Video, Sensors, Human-Centered, and Environment Logs. We introduce a novel data fusion category -- mid fusion -- and a graph-based technique for refining literature reviews, termed citation graph pruning. Our analysis reveals that leveraging multiple modalities offers a more holistic understanding of the behaviors and outcomes of learners and trainees. Even when multimodality does not enhance predictive accuracy, it often uncovers patterns that contextualize and elucidate unimodal data, revealing subtleties that a single modality may miss. However, there remains a need for further research to bridge the divide between multimodal learning and training studies and foundational AI research.
Read more8/28/2024

0
A Survey of Multimodal Large Language Model from A Data-centric Perspective
Tianyi Bai, Hao Liang, Binwang Wan, Yanran Xu, Xi Li, Shiyu Li, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, Ping Huang, Jiulong Shan, Conghui He, Binhang Yuan, Wentao Zhang
Multimodal large language models (MLLMs) enhance the capabilities of standard large language models by integrating and processing data from multiple modalities, including text, vision, audio, video, and 3D environments. Data plays a pivotal role in the development and refinement of these models. In this survey, we comprehensively review the literature on MLLMs from a data-centric perspective. Specifically, we explore methods for preparing multimodal data during the pretraining and adaptation phases of MLLMs. Additionally, we analyze the evaluation methods for the datasets and review the benchmarks for evaluating MLLMs. Our survey also outlines potential future research directions. This work aims to provide researchers with a detailed understanding of the data-driven aspects of MLLMs, fostering further exploration and innovation in this field.
Read more7/19/2024
📊
0
Vision+X: A Survey on Multimodal Learning in the Light of Data
Ye Zhu, Yu Wu, Nicu Sebe, Yan Yan
We are perceiving and communicating with the world in a multisensory manner, where different information sources are sophisticatedly processed and interpreted by separate parts of the human brain to constitute a complex, yet harmonious and unified sensing system. To endow the machines with true intelligence, multimodal machine learning that incorporates data from various sources has become an increasingly popular research area with emerging technical advances in recent years. In this paper, we present a survey on multimodal machine learning from a novel perspective considering not only the purely technical aspects but also the intrinsic nature of different data modalities. We analyze the commonness and uniqueness of each data format mainly ranging from vision, audio, text, and motions, and then present the methodological advancements categorized by the combination of data modalities, such as Vision+Text, with slightly inclined emphasis on the visual data. We investigate the existing literature on multimodal learning from both the representation learning and downstream application levels, and provide an additional comparison in the light of their technical connections with the data nature, e.g., the semantic consistency between image objects and textual descriptions, and the rhythm correspondence between video dance moves and musical beats. We hope that the exploitation of the alignment as well as the existing gap between the intrinsic nature of data modality and the technical designs, will benefit future research studies to better address a specific challenge related to the concrete multimodal task, prompting a unified multimodal machine learning framework closer to a real human intelligence system.
Read more6/12/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
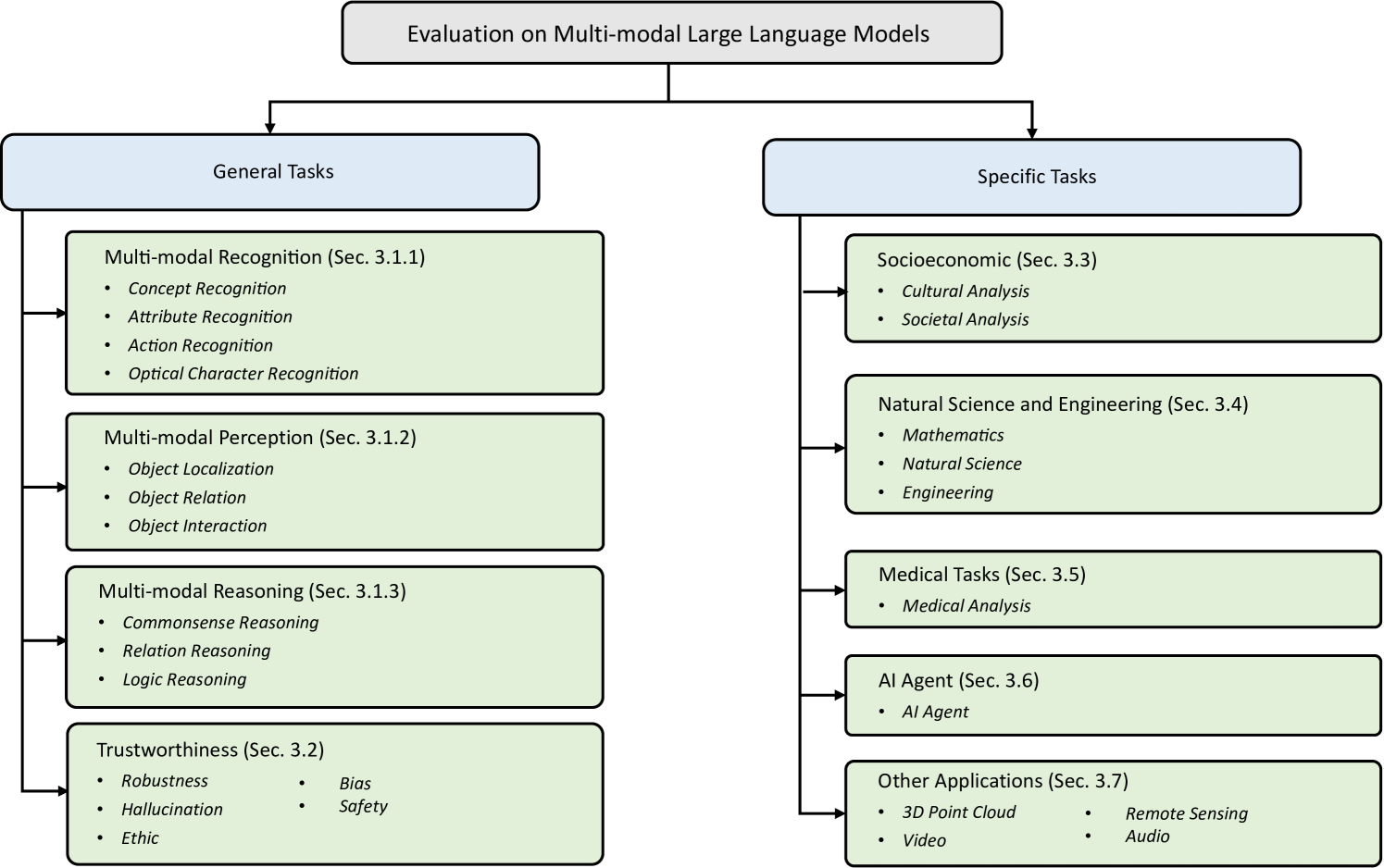
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024