Multimodal Prompt Learning with Missing Modalities for Sentiment Analysis and Emotion Recognition

0

Sign in to get full access
Overview
- This paper proposes a multimodal prompt learning approach to tackle the challenge of sentiment analysis and emotion recognition with missing modalities.
- The key ideas include token-level contrastive learning, multi-prompt depth-partitioned cross-modal learning, and dynamic modality view selection to handle missing modalities.
- The method is evaluated on various multimodal sentiment analysis and emotion recognition benchmarks, demonstrating its effectiveness in dealing with all-stage missing modality scenarios.
Plain English Explanation
The paper introduces a new approach to handling sentiment analysis and emotion recognition tasks when some of the input data (such as text, audio, or video) is missing. This is a common challenge in real-world applications, where we may not always have access to all the relevant information.
The key idea is to use "prompts" - short text descriptions that provide additional context and guidance to the AI model. By learning how to effectively use these prompts, the model can still make accurate predictions even when some of the input data is missing.
The researchers use several techniques to make this work:
- Token-level contrastive learning: This helps the model learn better representations of the input data by comparing similar and dissimilar parts of the input.
- Multi-prompt depth-partitioned cross-modal learning: This allows the model to learn how to combine information from different types of input (e.g., text and audio) using multiple prompts.
- Dynamic modality view selection: This enables the model to automatically choose the most relevant input data to focus on, depending on what information is available.
By using these advanced techniques, the researchers show that their approach can outperform other methods on standard benchmarks for sentiment analysis and emotion recognition, even when dealing with incomplete input data.
Technical Explanation
The paper presents a Multimodal Prompt Learning (MPL) framework to tackle the problem of sentiment analysis and emotion recognition with missing modalities. The key components of the MPL framework include:
-
Token-level Contrastive Learning: The model learns better representations of the input data by comparing similar and dissimilar token-level features across modalities using a contrastive loss function. This helps the model capture cross-modal relationships even when some modalities are missing.
-
Multi-Prompt Depth-Partitioned Cross-modal Learning: The model learns to effectively combine information from different modalities using multiple prompts that are tailored to different depth levels of the model. This allows the model to learn more robust cross-modal interactions.
-
Dynamic Modality View Selection: The model dynamically selects the most relevant modality views to focus on during inference, depending on the available input data. This helps the model adapt to various missing modality scenarios.
The MPL framework is evaluated on several multimodal sentiment analysis and emotion recognition benchmarks, including CMU-MOSI, CMU-MOSEI, and IEMOCAP. The results demonstrate the effectiveness of the proposed approach in handling all-stage missing modality scenarios, outperforming state-of-the-art methods.
Critical Analysis
The paper presents a promising approach to dealing with missing modalities in multimodal sentiment analysis and emotion recognition tasks. The key strengths of the proposed MPL framework include its ability to learn robust cross-modal representations using contrastive learning, effectively combine information from different modalities using multiple prompts, and dynamically select the most relevant modalities during inference.
However, the paper also acknowledges some limitations and areas for further research. For instance, the performance of the MPL framework may be sensitive to the quality and relevance of the prompts used, and the optimal number of prompts may vary depending on the task and dataset. Additionally, the paper does not explore how the MPL framework might generalize to other multimodal tasks beyond sentiment analysis and emotion recognition.
Future research could investigate strategies for automatically generating or optimizing the prompts used in the MPL framework, as well as exploring its applicability to a wider range of multimodal learning problems, such as multimodal action recognition or multimodal visual question answering. Addressing these areas could further enhance the robustness and versatility of the MPL approach.
Conclusion
This paper presents a novel Multimodal Prompt Learning (MPL) framework that addresses the challenge of sentiment analysis and emotion recognition with missing modalities. By leveraging techniques such as token-level contrastive learning, multi-prompt depth-partitioned cross-modal learning, and dynamic modality view selection, the MPL framework demonstrates effective performance on standard benchmarks, even when dealing with incomplete input data.
The paper's key contributions lie in its ability to learn robust cross-modal representations, combine information from different modalities flexibly, and adapt to various missing modality scenarios. While the approach shows promise, future research could explore ways to further optimize the prompt design and expand the framework's applicability to a broader range of multimodal learning tasks. Overall, this work represents an important step towards building more robust and versatile multimodal AI systems that can handle the challenges of real-world data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Prompt Learning with Missing Modalities for Sentiment Analysis and Emotion Recognition
Zirun Guo, Tao Jin, Zhou Zhao
The development of multimodal models has significantly advanced multimodal sentiment analysis and emotion recognition. However, in real-world applications, the presence of various missing modality cases often leads to a degradation in the model's performance. In this work, we propose a novel multimodal Transformer framework using prompt learning to address the issue of missing modalities. Our method introduces three types of prompts: generative prompts, missing-signal prompts, and missing-type prompts. These prompts enable the generation of missing modality features and facilitate the learning of intra- and inter-modality information. Through prompt learning, we achieve a substantial reduction in the number of trainable parameters. Our proposed method outperforms other methods significantly across all evaluation metrics. Extensive experiments and ablation studies are conducted to demonstrate the effectiveness and robustness of our method, showcasing its ability to effectively handle missing modalities.
Read more7/9/2024
0
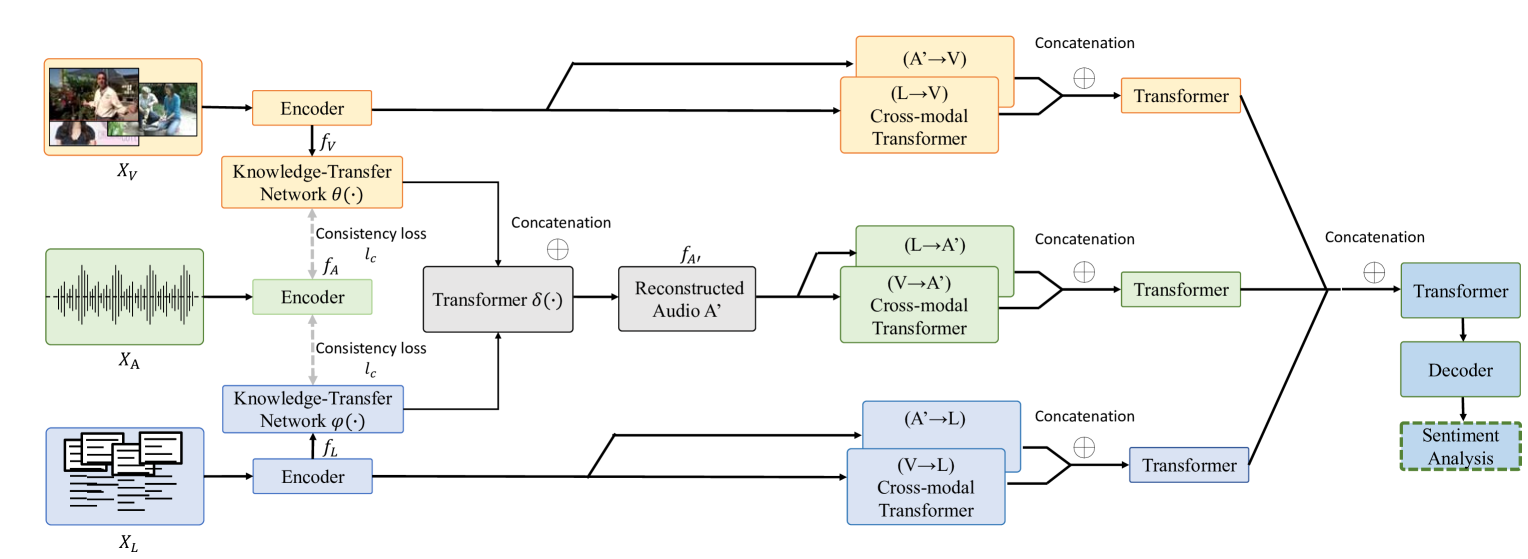
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
Read more7/12/2024

0
Multimodal Emotion Recognition with Vision-language Prompting and Modality Dropout
Anbin QI, Zhongliang Liu, Xinyong Zhou, Jinba Xiao, Fengrun Zhang, Qi Gan, Ming Tao, Gaozheng Zhang, Lu Zhang
In this paper, we present our solution for the Second Multimodal Emotion Recognition Challenge Track 1(MER2024-SEMI). To enhance the accuracy and generalization performance of emotion recognition, we propose several methods for Multimodal Emotion Recognition. Firstly, we introduce EmoVCLIP, a model fine-tuned based on CLIP using vision-language prompt learning, designed for video-based emotion recognition tasks. By leveraging prompt learning on CLIP, EmoVCLIP improves the performance of pre-trained CLIP on emotional videos. Additionally, to address the issue of modality dependence in multimodal fusion, we employ modality dropout for robust information fusion. Furthermore, to aid Baichuan in better extracting emotional information, we suggest using GPT-4 as the prompt for Baichuan. Lastly, we utilize a self-training strategy to leverage unlabeled videos. In this process, we use unlabeled videos with high-confidence pseudo-labels generated by our model and incorporate them into the training set. Experimental results demonstrate that our model ranks 1st in the MER2024-SEMI track, achieving an accuracy of 90.15% on the test set.
Read more9/12/2024

0
MuAP: Multi-step Adaptive Prompt Learning for Vision-Language Model with Missing Modality
Ruiting Dai, Yuqiao Tan, Lisi Mo, Tao He, Ke Qin, Shuang Liang
Recently, prompt learning has garnered considerable attention for its success in various Vision-Language (VL) tasks. However, existing prompt-based models are primarily focused on studying prompt generation and prompt strategies with complete modality settings, which does not accurately reflect real-world scenarios where partial modality information may be missing. In this paper, we present the first comprehensive investigation into prompt learning behavior when modalities are incomplete, revealing the high sensitivity of prompt-based models to missing modalities. To this end, we propose a novel Multi-step Adaptive Prompt Learning (MuAP) framework, aiming to generate multimodal prompts and perform multi-step prompt tuning, which adaptively learns knowledge by iteratively aligning modalities. Specifically, we generate multimodal prompts for each modality and devise prompt strategies to integrate them into the Transformer model. Subsequently, we sequentially perform prompt tuning from single-stage and alignment-stage, allowing each modality-prompt to be autonomously and adaptively learned, thereby mitigating the imbalance issue caused by only textual prompts that are learnable in previous works. Extensive experiments demonstrate the effectiveness of our MuAP and this model achieves significant improvements compared to the state-of-the-art on all benchmark datasets
Read more9/10/2024