Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
2406.01987
0
0
Abstract
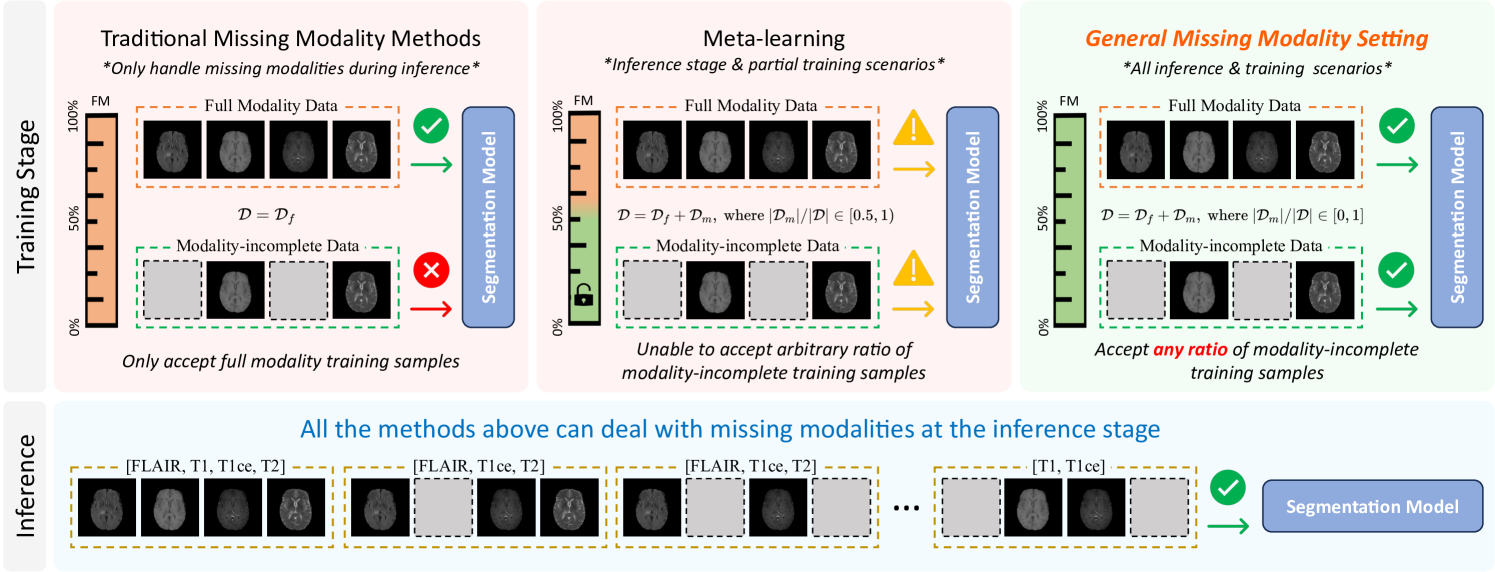
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Create account to get full access
Overview
- The paper focuses on the challenge of dealing with "all-stage missing modality" in multi-modal machine learning tasks, where some data modalities (e.g., image, text, audio) may be missing during training, validation, or testing.
- The authors propose a "Universal Model" that can robustly handle missing modalities at any stage and also offer personalization capabilities.
- Key ideas include a modality-agnostic feature extraction module, a reconstruction module to impute missing modalities, and a personalization module to adapt the model to individual users.
Plain English Explanation
Modern AI systems often work with multiple types of data, such as images, text, and audio. This is known as "multi-modal" learning. However, in real-world scenarios, some of these data types may be missing at different stages of the machine learning process - during training, validation, or even when making predictions.
The paper introduces a new approach called the "Universal Model" that can effectively deal with this challenge of "all-stage missing modality." The key idea is to build a model that can work robustly even when some data types are unavailable.
The Universal Model has three main components:
- A modality-agnostic feature extractor: This module can extract useful features from any available data, without relying on the presence of a specific data type.
- A reconstruction module: This part of the model can impute or "fill in" the missing data, allowing the system to make predictions even when some modalities are absent.
- A personalization module: This component adapts the model to the preferences and characteristics of individual users, improving the model's performance for each person.
By combining these innovative techniques, the Universal Model can handle missing data more effectively than traditional multi-modal approaches, making it a promising solution for real-world AI applications where data availability can be inconsistent.
Technical Explanation
The paper proposes a "Universal Model" that can handle "all-stage missing modality" in multi-modal learning tasks. The key elements of the model are:
-
Modality-Agnostic Feature Extractor: This module uses a shared encoder to extract features from any available data modality, without relying on the presence of a specific modality. This helps the model operate robustly even when some modalities are missing.
-
Reconstruction Module: This component uses a modality-specific decoder to impute or "reconstruct" the missing modalities based on the available data. This allows the model to make predictions even when some modalities are absent.
-
Personalization Module: This module adapts the model to the preferences and characteristics of individual users, improving the model's performance for each person. This is achieved through a user-specific embedding and a personalization network.
The authors evaluate the Universal Model on various multi-modal benchmarks, including combating missing modalities in egocentric videos, multimodal multi-view representation learning, and dynamic modality selection for emotion recognition. The results demonstrate the model's ability to outperform traditional approaches in scenarios with missing modalities at any stage of the machine learning pipeline.
Critical Analysis
The paper presents a comprehensive and innovative solution to the challenging problem of all-stage missing modality in multi-modal learning. The authors have thoughtfully addressed key limitations of existing approaches, such as the inability to handle missing modalities at test time or the lack of personalization capabilities.
One potential area for further research could be the exploration of more advanced reconstruction techniques, such as the use of Fourier prompt tuning for modality-incomplete scene segmentation or learning noise-robust joint representations for multimodal emotion recognition. Additionally, the authors could investigate the Universal Model's performance in a wider range of real-world applications and its ability to handle more complex patterns of missing data.
Overall, the Universal Model presented in this paper represents a significant advancement in the field of multi-modal machine learning and has the potential to enable more robust and personalized AI systems that can operate effectively in the face of incomplete data.
Conclusion
The paper introduces the "Universal Model," a novel approach to dealing with the challenge of "all-stage missing modality" in multi-modal machine learning tasks. By combining a modality-agnostic feature extractor, a reconstruction module, and a personalization component, the Universal Model can handle missing data more effectively than traditional methods.
The evaluation results demonstrate the model's superior performance on various benchmarks, highlighting its potential to enable more robust and personalized AI applications in real-world scenarios where data availability can be inconsistent. The authors' innovative solutions to this important problem represent a significant contribution to the field of multi-modal machine learning and pave the way for more versatile and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unveiling Incomplete Modality Brain Tumor Segmentation: Leveraging Masked Predicted Auto-Encoder and Divergence Learning
Zhongao Sun, Jiameng Li, Yuhan Wang, Jiarong Cheng, Qing Zhou, Chun Li
0
0
Brain tumor segmentation remains a significant challenge, particularly in the context of multi-modal magnetic resonance imaging (MRI) where missing modality images are common in clinical settings, leading to reduced segmentation accuracy. To address this issue, we propose a novel strategy, which is called masked predicted pre-training, enabling robust feature learning from incomplete modality data. Additionally, in the fine-tuning phase, we utilize a knowledge distillation technique to align features between complete and missing modality data, simultaneously enhancing model robustness. Notably, we leverage the Holder pseudo-divergence instead of the KLD for distillation loss, offering improve mathematical interpretability and properties. Extensive experiments on the BRATS2018 and BRATS2020 datasets demonstrate significant performance enhancements compared to existing state-of-the-art methods.
6/14/2024
Multimodal Sentiment Analysis with Missing Modality: A Knowledge-Transfer Approach
Weide Liu, Huijing Zhan, Hao Chen, Fengmao Lv
0
0
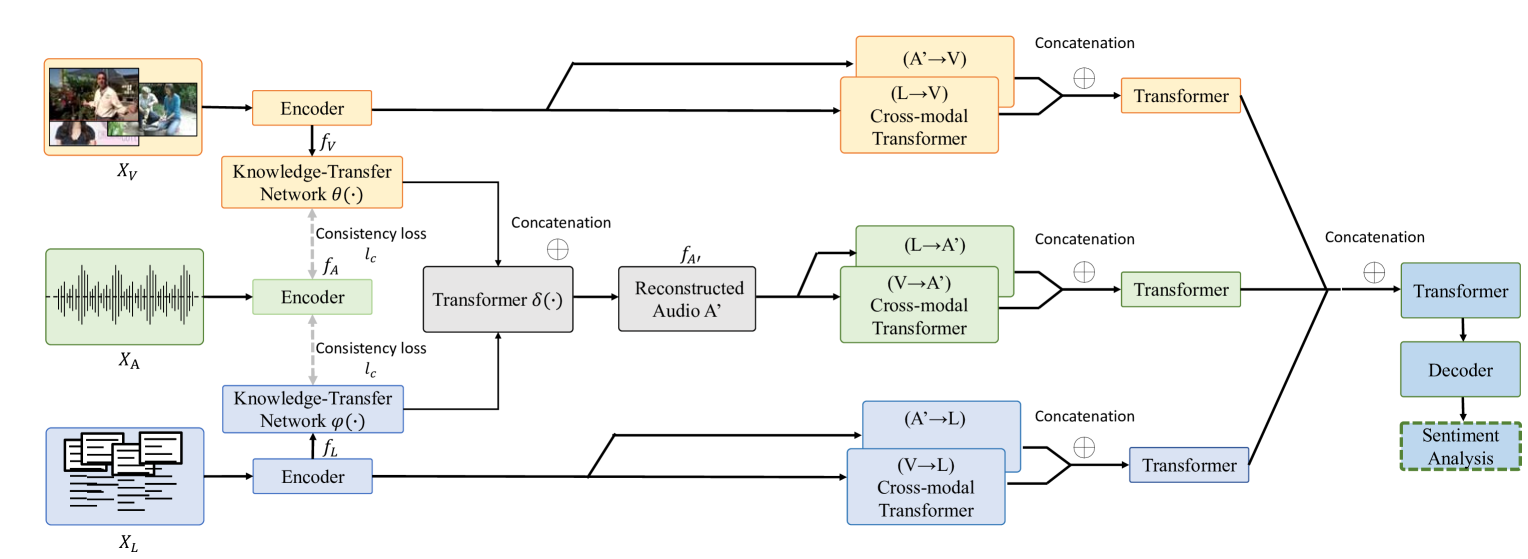
Multimodal sentiment analysis aims to identify the emotions expressed by individuals through visual, language, and acoustic cues. However, most of the existing research efforts assume that all modalities are available during both training and testing, making their algorithms susceptible to the missing modality scenario. In this paper, we propose a novel knowledge-transfer network to translate between different modalities to reconstruct the missing audio modalities. Moreover, we develop a cross-modality attention mechanism to retain the maximal information of the reconstructed and observed modalities for sentiment prediction. Extensive experiments on three publicly available datasets demonstrate significant improvements over baselines and achieve comparable results to the previous methods with complete multi-modality supervision.
6/21/2024
🌿
Combating Missing Modalities in Egocentric Videos at Test Time
Merey Ramazanova, Alejandro Pardo, Bernard Ghanem, Motasem Alfarra
0
0
Understanding videos that contain multiple modalities is crucial, especially in egocentric videos, where combining various sensory inputs significantly improves tasks like action recognition and moment localization. However, real-world applications often face challenges with incomplete modalities due to privacy concerns, efficiency needs, or hardware issues. Current methods, while effective, often necessitate retraining the model entirely to handle missing modalities, making them computationally intensive, particularly with large training datasets. In this study, we propose a novel approach to address this issue at test time without requiring retraining. We frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time. Our method, MiDl~(Mutual information with self-Distillation), encourages the model to be insensitive to the specific modality source present during testing by minimizing the mutual information between the prediction and the available modality. Additionally, we incorporate self-distillation to maintain the model's original performance when both modalities are available. MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, MiDl demonstrates substantial performance improvement without the need for retraining.
4/24/2024
Dynamic Modality and View Selection for Multimodal Emotion Recognition with Missing Modalities
Luciana Trinkaus Menon, Luiz Carlos Ribeiro Neduziak, Jean Paul Barddal, Alessandro Lameiras Koerich, Alceu de Souza Britto Jr
0
0
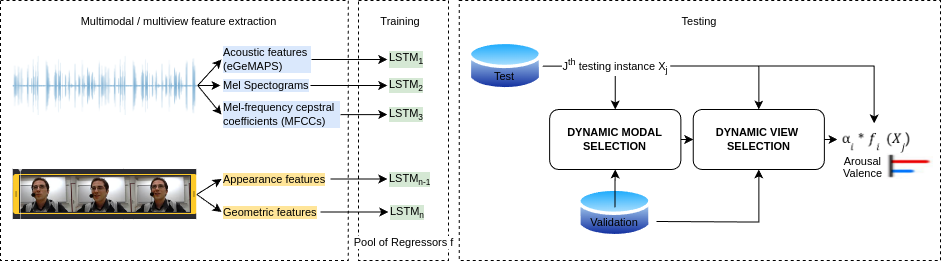
The study of human emotions, traditionally a cornerstone in fields like psychology and neuroscience, has been profoundly impacted by the advent of artificial intelligence (AI). Multiple channels, such as speech (voice) and facial expressions (image), are crucial in understanding human emotions. However, AI's journey in multimodal emotion recognition (MER) is marked by substantial technical challenges. One significant hurdle is how AI models manage the absence of a particular modality - a frequent occurrence in real-world situations. This study's central focus is assessing the performance and resilience of two strategies when confronted with the lack of one modality: a novel multimodal dynamic modality and view selection and a cross-attention mechanism. Results on the RECOLA dataset show that dynamic selection-based methods are a promising approach for MER. In the missing modalities scenarios, all dynamic selection-based methods outperformed the baseline. The study concludes by emphasizing the intricate interplay between audio and video modalities in emotion prediction, showcasing the adaptability of dynamic selection methods in handling missing modalities.
4/19/2024