Multimodal Relational Triple Extraction with Query-based Entity Object Transformer

0

Sign in to get full access
Overview
- This paper presents a new approach for extracting relational triples from multimodal data, combining textual and visual information.
- The key innovation is the Query-based Entity Object Transformer (QEOT), which leverages entity-centric queries to guide the extraction process.
- The model demonstrates strong performance on multimodal relation extraction tasks compared to previous methods.
Plain English Explanation
The paper describes a way to extract relational triples from multimodal data - information that combines text and images. Relational triples are statements about the relationships between different entities, like "person X is the author of book Y".
The researchers developed a new model component called the Query-based Entity Object Transformer (QEOT). This allows the system to focus on the specific entities and relationships it's looking for, by using "queries" that describe what it should be searching for.
This query-based approach helps the model perform better at extracting relational triples from the multimodal data, compared to previous methods that didn't leverage this entity-centric querying. The paper shows the QEOT model achieves strong results on standard multimodal relation extraction benchmarks.
Technical Explanation
The paper introduces a multimodal relational triple extraction model that combines textual and visual information. The key innovation is the Query-based Entity Object Transformer (QEOT), which uses entity-centric queries to guide the extraction process.
The QEOT module takes as input the textual and visual features of the data, along with a query specifying the entities and relationships of interest. It then learns to attend to the relevant parts of the input that are most useful for extracting the desired relational triples.
This query-based approach allows the model to focus on the specific entities and relationships it's searching for, rather than trying to extract all possible triples indiscriminately. The authors show this leads to improved performance on benchmark multimodal relation extraction tasks compared to prior methods.
The full model architecture combines the QEOT module with other components for encoding the textual and visual inputs, and for predicting the final relational triples. Extensive experiments demonstrate the efficacy of the approach across different datasets and settings.
Critical Analysis
The paper makes a compelling contribution by introducing the QEOT module, which leverages entity-centric queries to improve multimodal relational triple extraction. This query-based approach is a novel and promising direction that helps the model focus on the most relevant information.
However, the paper does not fully address the limitations of this approach. For example, the quality of the extracted triples may depend heavily on the accuracy and completeness of the input queries. If the queries are missing key entities or relationships, the model may fail to extract important triples.
Additionally, the paper does not discuss potential scalability issues. As the number of entities and relations grows, constructing effective queries could become increasingly challenging. Further research may be needed to understand how the QEOT model would perform in large-scale, real-world settings.
Overall, the paper presents an interesting technical advance, but more work is likely needed to fully understand the strengths, weaknesses, and practical implications of the proposed approach.
Conclusion
This paper introduces a new method for multimodal relational triple extraction that leverages entity-centric queries to guide the extraction process. The key innovation is the Query-based Entity Object Transformer (QEOT), which allows the model to focus on the specific entities and relationships of interest.
The QEOT-based model demonstrates strong performance on benchmark tasks, highlighting the potential of this query-guided approach for multimodal relation extraction. While the paper makes a compelling technical contribution, further research is needed to address potential limitations around query quality and scalability.
Nevertheless, this work represents an important step forward in leveraging multimodal data for relational understanding, with broader implications for applications like knowledge graph construction, question answering, and commonsense reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Relational Triple Extraction with Query-based Entity Object Transformer
Lei Hei, Ning An, Tingjing Liao, Qi Ma, Jiaqi Wang, Feiliang Ren
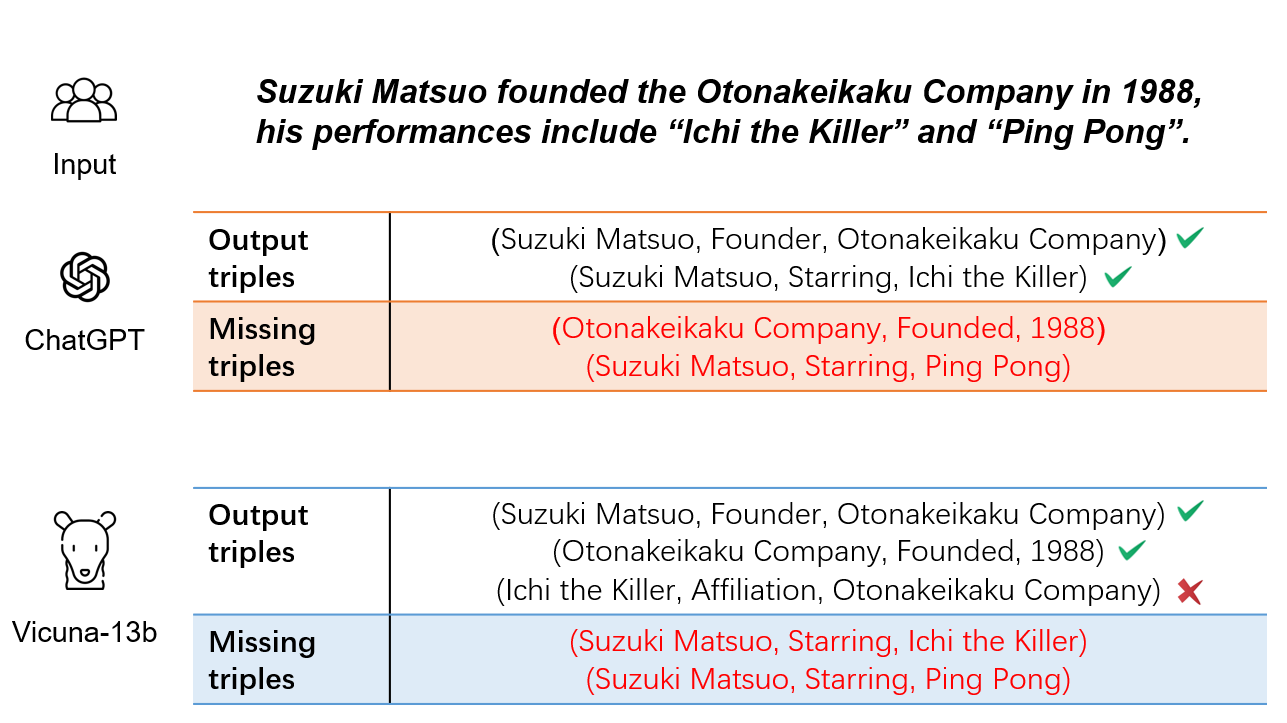
Multimodal Relation Extraction is crucial for constructing flexible and realistic knowledge graphs. Recent studies focus on extracting the relation type with entity pairs present in different modalities, such as one entity in the text and another in the image. However, existing approaches require entities and objects given beforehand, which is costly and impractical. To address the limitation, we propose a novel task, Multimodal Entity-Object Relational Triple Extraction, which aims to extract all triples (entity span, relation, object region) from image-text pairs. To facilitate this study, we modified a multimodal relation extraction dataset MORE, which includes 21 relation types, to create a new dataset containing 20,264 triples, averaging 5.75 triples per image-text pair. Moreover, we propose QEOT, a query-based model with a selective attention mechanism, to dynamically explore the interaction and fusion of textual and visual information. In particular, the proposed method can simultaneously accomplish entity extraction, relation classification, and object detection with a set of queries. Our method is suitable for downstream applications and reduces error accumulation due to the pipeline-style approaches. Extensive experimental results demonstrate that our proposed method outperforms the existing baselines by 8.06% and achieves state-of-the-art performance.
Read more8/19/2024
0
Improving Recall of Large Language Models: A Model Collaboration Approach for Relational Triple Extraction
Zepeng Ding, Wenhao Huang, Jiaqing Liang, Deqing Yang, Yanghua Xiao
Relation triple extraction, which outputs a set of triples from long sentences, plays a vital role in knowledge acquisition. Large language models can accurately extract triples from simple sentences through few-shot learning or fine-tuning when given appropriate instructions. However, they often miss out when extracting from complex sentences. In this paper, we design an evaluation-filtering framework that integrates large language models with small models for relational triple extraction tasks. The framework includes an evaluation model that can extract related entity pairs with high precision. We propose a simple labeling principle and a deep neural network to build the model, embedding the outputs as prompts into the extraction process of the large model. We conduct extensive experiments to demonstrate that the proposed method can assist large language models in obtaining more accurate extraction results, especially from complex sentences containing multiple relational triples. Our evaluation model can also be embedded into traditional extraction models to enhance their extraction precision from complex sentences.
Read more4/16/2024
0
A Bi-consolidating Model for Joint Relational Triple Extraction
Xiaocheng Luo, Yanping Chen, Ruixue Tang, Caiwei Yang, Ruizhang Huang, Yongbin Qin
Current methods to extract relational triples directly make a prediction based on a possible entity pair in a raw sentence without depending on entity recognition. The task suffers from a serious semantic overlapping problem, in which several relation triples may share one or two entities in a sentence. In this paper, based on a two-dimensional sentence representation, a bi-consolidating model is proposed to address this problem by simultaneously reinforcing the local and global semantic features relevant to a relation triple. This model consists of a local consolidation component and a global consolidation component. The first component uses a pixel difference convolution to enhance semantic information of a possible triple representation from adjacent regions and mitigate noise in neighbouring neighbours. The second component strengthens the triple representation based a channel attention and a spatial attention, which has the advantage to learn remote semantic dependencies in a sentence. They are helpful to improve the performance of both entity identification and relation type classification in relation triple extraction. After evaluated on several publish datasets, the bi-consolidating model achieves competitive performance. Analytical experiments demonstrate the effectiveness of our model for relational triple extraction and give motivation for other natural language processing tasks.
Read more7/11/2024

0
Leveraging Entity Information for Cross-Modality Correlation Learning: The Entity-Guided Multimodal Summarization
Yanghai Zhang, Ye Liu, Shiwei Wu, Kai Zhang, Xukai Liu, Qi Liu, Enhong Chen
The rapid increase in multimedia data has spurred advancements in Multimodal Summarization with Multimodal Output (MSMO), which aims to produce a multimodal summary that integrates both text and relevant images. The inherent heterogeneity of content within multimodal inputs and outputs presents a significant challenge to the execution of MSMO. Traditional approaches typically adopt a holistic perspective on coarse image-text data or individual visual objects, overlooking the essential connections between objects and the entities they represent. To integrate the fine-grained entity knowledge, we propose an Entity-Guided Multimodal Summarization model (EGMS). Our model, building on BART, utilizes dual multimodal encoders with shared weights to process text-image and entity-image information concurrently. A gating mechanism then combines visual data for enhanced textual summary generation, while image selection is refined through knowledge distillation from a pre-trained vision-language model. Extensive experiments on public MSMO dataset validate the superiority of the EGMS method, which also prove the necessity to incorporate entity information into MSMO problem.
Read more8/7/2024