Leveraging Entity Information for Cross-Modality Correlation Learning: The Entity-Guided Multimodal Summarization

0

Sign in to get full access
Overview
- This paper introduces a new approach for multimodal summarization that leverages entity information to improve cross-modality correlation learning.
- The proposed "Entity-Guided Multimodal Summarization" (EGMS) model incorporates entity-level information to better align and integrate textual and visual features.
- The EGMS model outperforms state-of-the-art multimodal summarization methods on benchmark datasets, demonstrating the benefits of incorporating entity knowledge.
Plain English Explanation
The paper presents a new way to summarize information that combines text and images. The key idea is to use information about the entities (people, places, things) mentioned in the text and shown in the images to help the model understand the connections between the text and visuals.
Typically, multimodal summarization models try to capture the relationships between text and images, but they don't specifically leverage the entities involved. The EGMS model introduced in this paper focuses on the entities as the linking point between the two modalities.
By incorporating entity-level information, the EGMS model is able to better align the text and visual features and integrate them more effectively to produce higher quality summaries. This approach outperforms other state-of-the-art multimodal summarization methods on standard benchmarks.
The main advantage of the EGMS model is that it can better understand the connections between the textual and visual content by focusing on the key entities mentioned and depicted. This leads to more coherent and informative summaries that capture the most salient information from both modalities.
Technical Explanation
The EGMS model consists of three main components:
-
Entity Extraction: This module identifies the key entities mentioned in the text and detected in the images using pre-trained models.
-
Entity-Aware Multimodal Alignment: The extracted entity information is used to learn better cross-modal alignments between the textual and visual features.
-
Entity-Guided Multimodal Integration: The aligned features are then integrated with the entity representations to produce the final multimodal summary.
The key innovation is the entity-guided approach, which allows the model to focus on the most important semantic concepts (the entities) when learning the relationships between the text and images.
Experiments on benchmark datasets like link and link show that the EGMS model outperforms previous state-of-the-art methods by a significant margin. This demonstrates the benefits of incorporating entity-level information for effective multimodal summarization.
Critical Analysis
The paper provides a thorough evaluation of the EGMS model and highlights its advantages over prior work. However, a few potential limitations or areas for further research are worth noting:
-
The entity extraction performance is crucial to the overall model effectiveness, and the paper does not provide a detailed analysis of the entity recognition accuracy.
-
The experiments are conducted on relatively constrained datasets, and it would be valuable to assess the EGMS model's generalization to more diverse and challenging multimodal summarization scenarios.
-
The computational complexity of the entity-guided approach is not discussed, and it would be important to understand the model's scalability for real-world applications.
-
While the entity-centric focus is a key strength, there may be cases where other semantic relationships beyond entities are also important for effective multimodal summarization.
Overall, the EGMS model represents an important step forward in leveraging entity information for cross-modal correlation learning, but further research and evaluation could help identify its limitations and potential areas for improvement.
Conclusion
This paper introduces the Entity-Guided Multimodal Summarization (EGMS) model, which leverages entity-level information to improve cross-modality correlation learning for multimodal summarization. By focusing on the key entities mentioned in the text and depicted in the images, the EGMS model is able to better align and integrate the textual and visual features, leading to more coherent and informative summaries.
The experimental results demonstrate the advantages of the EGMS approach over previous state-of-the-art multimodal summarization methods, highlighting the benefits of incorporating entity knowledge. While the paper identifies some potential areas for further research, the EGMS model represents an important contribution to the field of multimodal summarization, with implications for a wide range of applications that involve understanding and summarizing information from multiple modalities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leveraging Entity Information for Cross-Modality Correlation Learning: The Entity-Guided Multimodal Summarization
Yanghai Zhang, Ye Liu, Shiwei Wu, Kai Zhang, Xukai Liu, Qi Liu, Enhong Chen
The rapid increase in multimedia data has spurred advancements in Multimodal Summarization with Multimodal Output (MSMO), which aims to produce a multimodal summary that integrates both text and relevant images. The inherent heterogeneity of content within multimodal inputs and outputs presents a significant challenge to the execution of MSMO. Traditional approaches typically adopt a holistic perspective on coarse image-text data or individual visual objects, overlooking the essential connections between objects and the entities they represent. To integrate the fine-grained entity knowledge, we propose an Entity-Guided Multimodal Summarization model (EGMS). Our model, building on BART, utilizes dual multimodal encoders with shared weights to process text-image and entity-image information concurrently. A gating mechanism then combines visual data for enhanced textual summary generation, while image selection is refined through knowledge distillation from a pre-trained vision-language model. Extensive experiments on public MSMO dataset validate the superiority of the EGMS method, which also prove the necessity to incorporate entity information into MSMO problem.
Read more8/7/2024
0
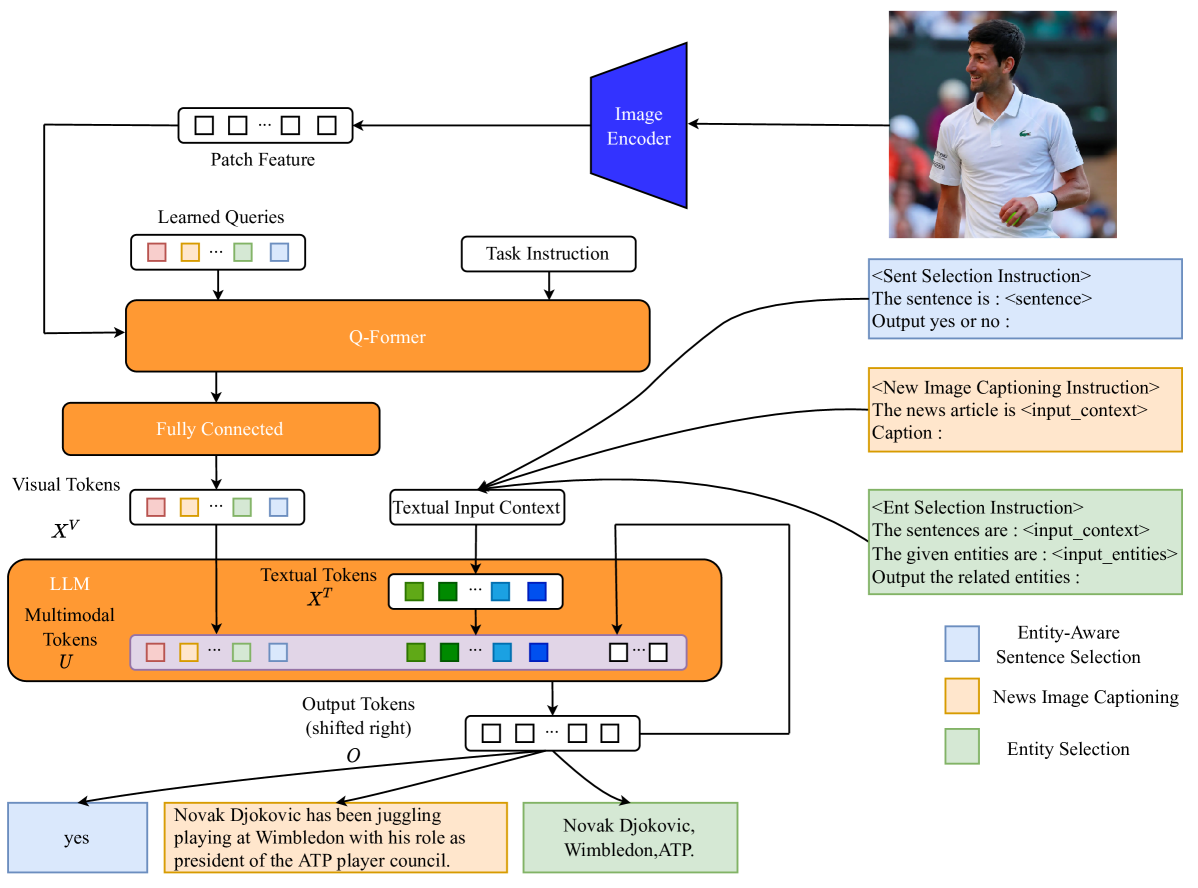
EAMA : Entity-Aware Multimodal Alignment Based Approach for News Image Captioning
Junzhe Zhang, Huixuan Zhang, Xunjian Yin, Xiaojun Wan
News image captioning requires model to generate an informative caption rich in entities, with the news image and the associated news article. Though Multimodal Large Language Models (MLLMs) have demonstrated remarkable capabilities in addressing various vision-language tasks, our research finds that current MLLMs still bear limitations in handling entity information on news image captioning task. Besides, while MLLMs have the ability to process long inputs, generating high-quality news image captions still requires a trade-off between sufficiency and conciseness of textual input information. To explore the potential of MLLMs and address problems we discovered, we propose : an Entity-Aware Multimodal Alignment based approach for news image captioning. Our approach first aligns the MLLM through Balance Training Strategy with two extra alignment tasks: Entity-Aware Sentence Selection task and Entity Selection task, together with News Image Captioning task, to enhance its capability in handling multimodal entity information. The aligned MLLM will utilizes the additional entity-related information it explicitly extracts to supplement its textual input while generating news image captions. Our approach achieves better results than all previous models in CIDEr score on GoodNews dataset (72.33 -> 88.39) and NYTimes800k dataset (70.83 -> 85.61).
Read more5/7/2024
👀
0
Detecting Misinformation in Multimedia Content through Cross-Modal Entity Consistency: A Dual Learning Approach
Zhe Fu, Kanlun Wang, Wangjiaxuan Xin, Lina Zhou, Shi Chen, Yaorong Ge, Daniel Janies, Dongsong Zhang
The landscape of social media content has evolved significantly, extending from text to multimodal formats. This evolution presents a significant challenge in combating misinformation. Previous research has primarily focused on single modalities or text-image combinations, leaving a gap in detecting multimodal misinformation. While the concept of entity consistency holds promise in detecting multimodal misinformation, simplifying the representation to a scalar value overlooks the inherent complexities of high-dimensional representations across different modalities. To address these limitations, we propose a Multimedia Misinformation Detection (MultiMD) framework for detecting misinformation from video content by leveraging cross-modal entity consistency. The proposed dual learning approach allows for not only enhancing misinformation detection performance but also improving representation learning of entity consistency across different modalities. Our results demonstrate that MultiMD outperforms state-of-the-art baseline models and underscore the importance of each modality in misinformation detection. Our research provides novel methodological and technical insights into multimodal misinformation detection.
Read more9/4/2024

0
SITransformer: Shared Information-Guided Transformer for Extreme Multimodal Summarization
Sicheng Liu, Lintao Wang, Xiaogan Zhu, Xuequan Lu, Zhiyong Wang, Kun Hu
Extreme Multimodal Summarization with Multimodal Output (XMSMO) becomes an attractive summarization approach by integrating various types of information to create extremely concise yet informative summaries for individual modalities. Existing methods overlook the issue that multimodal data often contains more topic irrelevant information, which can mislead the model into producing inaccurate summaries especially for extremely short ones. In this paper, we propose SITransformer, a Shared Information-guided Transformer for extreme multimodal summarization. It has a shared information guided pipeline which involves a cross-modal shared information extractor and a cross-modal interaction module. The extractor formulates semantically shared salient information from different modalities by devising a novel filtering process consisting of a differentiable top-k selector and a shared-information guided gating unit. As a result, the common, salient, and relevant contents across modalities are identified. Next, a transformer with cross-modal attentions is developed for intra- and inter-modality learning with the shared information guidance to produce the extreme summary. Comprehensive experiments demonstrate that SITransformer significantly enhances the summarization quality for both video and text summaries for XMSMO. Our code will be publicly available at https://github.com/SichengLeoLiu/MMAsia24-XMSMO.
Read more8/30/2024