Multimodal Task Vectors Enable Many-Shot Multimodal In-Context Learning

0

Sign in to get full access
Overview
- This paper introduces "Multimodal Task Vectors" (MTVs), a novel approach to enable many-shot multimodal in-context learning.
- MTVs allow large language models to efficiently adapt to a wide range of multimodal tasks using only a few examples, without the need for extensive fine-tuning.
- The authors demonstrate the effectiveness of MTVs on various multimodal benchmarks, showing significant improvements over existing methods.
Plain English Explanation
The paper presents a new technique called "Multimodal Task Vectors" (MTVs) that enables large language models to quickly adapt to a wide variety of multimodal tasks, such as visual question answering or image captioning, using only a small number of examples. Learnable Context Vector for Visual Question Answering, What Makes Multimodal Context Learning Work, and AIM: Let Any Multi-Modal Large Language are some related works that explore similar ideas.
The key idea behind MTVs is to provide the language model with a compact, task-specific representation that can be quickly learned from a few examples. This allows the model to "understand" the task at hand and adapt its behavior accordingly, without requiring extensive fine-tuning on large datasets. Many-Shot Context Learning is another related work that explores similar concepts.
By using MTVs, the authors demonstrate significant performance improvements on various multimodal benchmarks, compared to existing methods. This suggests that MTVs are a powerful tool for enabling large language models to tackle a wide range of multimodal tasks with just a small number of training examples, which is particularly useful in real-world scenarios where data may be scarce.
Technical Explanation
The paper introduces "Multimodal Task Vectors" (MTVs), a novel approach to enable many-shot multimodal in-context learning. MTVs are compact, task-specific representations that allow large language models to efficiently adapt to a wide range of multimodal tasks using only a few examples, without the need for extensive fine-tuning.
The key components of the MTV approach are:
- Multimodal Prompt Encoding: The model takes a multimodal prompt (e.g., an image and a question) and encodes it into a compact vector representation.
- Task Vector Prediction: Based on the multimodal prompt, the model predicts a task-specific vector, the "Multimodal Task Vector" (MTV), that captures the essential information about the task.
- In-Context Adaptation: The language model uses the predicted MTV to adapt its internal representations and generate the desired output (e.g., an answer to the question).
The authors demonstrate the effectiveness of MTVs on various multimodal benchmarks, including Adapting Large Multimodal Models to Distribution Shifts, showing significant improvements over existing methods. This suggests that MTVs are a powerful tool for enabling large language models to tackle a wide range of multimodal tasks with just a small number of training examples.
Critical Analysis
The paper presents a novel and promising approach to enable many-shot multimodal in-context learning. The authors provide a thorough experimental evaluation, demonstrating the effectiveness of MTVs on several benchmark tasks.
One potential limitation of the approach is the reliance on the language model's ability to accurately predict the task-specific MTV from the multimodal prompt. If the MTV prediction is inaccurate, it could negatively impact the model's ability to adapt and perform the desired task. The authors acknowledge this limitation and suggest further research to improve the MTV prediction.
Additionally, the paper does not explore the transferability of MTVs across different tasks or domains. It would be interesting to see how well the learned MTVs generalize to new tasks or how they could be efficiently updated or fine-tuned for new scenarios. Adapting Large Multimodal Models to Distribution Shifts is a related work that explores similar issues.
Overall, the paper presents a compelling approach to enable many-shot multimodal in-context learning, which could have significant implications for real-world applications where data is scarce. Further research into the limitations and transferability of MTVs could help strengthen the approach and expand its potential applications.
Conclusion
The paper introduces "Multimodal Task Vectors" (MTVs), a novel technique that enables large language models to quickly adapt to a wide range of multimodal tasks using only a small number of examples. By providing the model with a compact, task-specific representation, MTVs allow for efficient in-context learning without the need for extensive fine-tuning.
The authors demonstrate the effectiveness of MTVs on various multimodal benchmarks, showing significant improvements over existing methods. This suggests that MTVs are a promising approach for enabling large language models to tackle a diverse set of multimodal tasks, which could be particularly useful in real-world scenarios where data is scarce.
Further research into the limitations and transferability of MTVs could help refine the approach and unlock new applications in areas such as Adapting Large Multimodal Models to Distribution Shifts. Overall, the paper presents an exciting step forward in the field of many-shot multimodal in-context learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Task Vectors Enable Many-Shot Multimodal In-Context Learning
Brandon Huang, Chancharik Mitra, Assaf Arbelle, Leonid Karlinsky, Trevor Darrell, Roei Herzig
The recent success of interleaved Large Multimodal Models (LMMs) in few-shot learning suggests that in-context learning (ICL) with many examples can be promising for learning new tasks. However, this many-shot multimodal ICL setting has one crucial problem: it is fundamentally limited by the model's context length set at pretraining. The problem is especially prominent in the multimodal domain, which processes both text and images, requiring additional tokens. This motivates the need for a multimodal method to compress many shots into fewer tokens without finetuning. In this work, we enable LMMs to perform multimodal, many-shot in-context learning by leveraging Multimodal Task Vectors (MTV)--compact implicit representations of in-context examples compressed in the model's attention heads. Specifically, we first demonstrate the existence of such MTV in LMMs and then leverage these extracted MTV to enable many-shot in-context learning for various vision-and-language tasks. Our experiments suggest that MTV can scale in performance with the number of compressed shots and generalize to similar out-of-domain tasks without additional context length for inference.
Read more6/24/2024
👀
0
Towards Multimodal In-Context Learning for Vision & Language Models
Sivan Doveh, Shaked Perek, M. Jehanzeb Mirza, Wei Lin, Amit Alfassy, Assaf Arbelle, Shimon Ullman, Leonid Karlinsky
State-of-the-art Vision-Language Models (VLMs) ground the vision and the language modality primarily via projecting the vision tokens from the encoder to language-like tokens, which are directly fed to the Large Language Model (LLM) decoder. While these models have shown unprecedented performance in many downstream zero-shot tasks (eg image captioning, question answers, etc), still little emphasis has been put on transferring one of the core LLM capability of In-Context Learning (ICL). ICL is the ability of a model to reason about a downstream task with a few examples demonstrations embedded in the prompt. In this work, through extensive evaluations, we find that the state-of-the-art VLMs somewhat lack the ability to follow ICL instructions. In particular, we discover that even models that underwent large-scale mixed modality pre-training and were implicitly guided to make use of interleaved image and text information (intended to consume helpful context from multiple images) under-perform when prompted with few-shot demonstrations (in an ICL way), likely due to their lack of direct ICL instruction tuning. To enhance the ICL abilities of the present VLM, we propose a simple yet surprisingly effective multi-turn curriculum-based learning methodology with effective data mixes, leading up to a significant 21.03% (and 11.3% on average) ICL performance boost over the strongest VLM baselines and a variety of ICL benchmarks. Furthermore, we also contribute new benchmarks for ICL evaluation in VLMs and discuss their advantages over the prior art.
Read more7/18/2024

0
Learnable In-Context Vector for Visual Question Answering
Yingzhe Peng, Chenduo Hao, Xu Yang, Jiawei Peng, Xinting Hu, Xin Geng
As language models continue to scale, Large Language Models (LLMs) have exhibited emerging capabilities in In-Context Learning (ICL), enabling them to solve language tasks by prefixing a few in-context demonstrations (ICDs) as context. Inspired by these advancements, researchers have extended these techniques to develop Large Multimodal Models (LMMs) with ICL capabilities. However, applying ICL usually faces two major challenges: 1) using more ICDs will largely increase the inference time and 2) the performance is sensitive to the selection of ICDs. These challenges are further exacerbated in LMMs due to the integration of multiple data types and the combinational complexity of multimodal ICDs. Recently, to address these challenges, some NLP studies introduce non-learnable In-Context Vectors (ICVs) which extract useful task information from ICDs into a single vector and then insert it into the LLM to help solve the corresponding task. However, although useful in simple NLP tasks, these non-learnable methods fail to handle complex multimodal tasks like Visual Question Answering (VQA). In this study, we propose textbf{Learnable ICV} (L-ICV) to distill essential task information from demonstrations, improving ICL performance in LMMs. Experiments show that L-ICV can significantly reduce computational costs while enhancing accuracy in VQA tasks compared to traditional ICL and other non-learnable ICV methods.
Read more6/21/2024
0
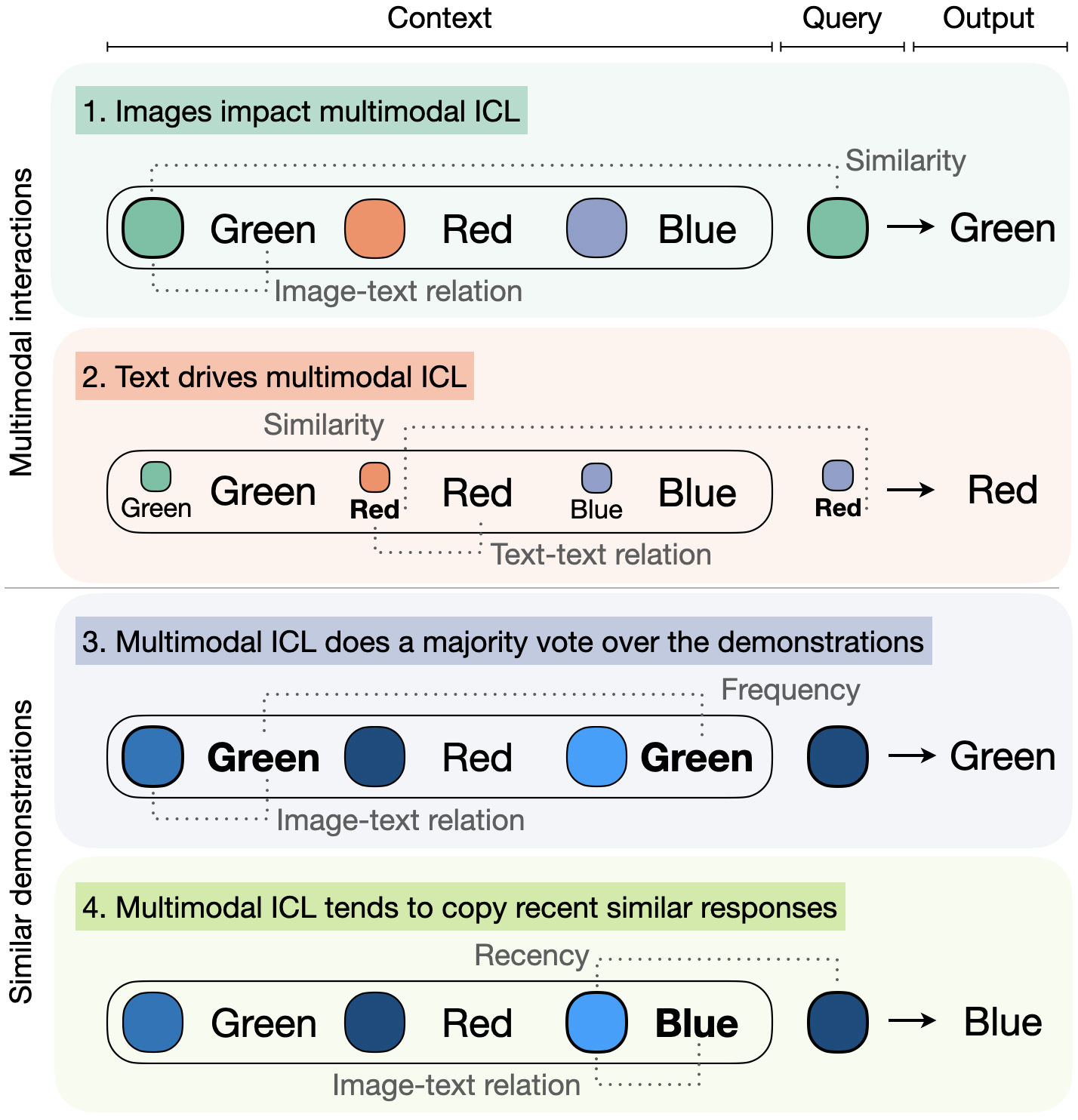
What Makes Multimodal In-Context Learning Work?
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, Benjamin Piwowarski
Large Language Models have demonstrated remarkable performance across various tasks, exhibiting the capacity to swiftly acquire new skills, such as through In-Context Learning (ICL) with minimal demonstration examples. In this work, we present a comprehensive framework for investigating Multimodal ICL (M-ICL) in the context of Large Multimodal Models. We consider the best open-source multimodal models (e.g., IDEFICS, OpenFlamingo) and a wide range of multimodal tasks. Our study unveils several noteworthy findings: (1) M-ICL primarily relies on text-driven mechanisms, showing little to no influence from the image modality. (2) When used with advanced-ICL strategy (like RICES), M-ICL is not better than a simple strategy based on majority voting over context examples. Moreover, we identify several biases and limitations of M-ICL that warrant consideration prior to deployment. Code available at https://gitlab.com/folbaeni/multimodal-icl
Read more4/26/2024