Music2Latent: Consistency Autoencoders for Latent Audio Compression

0
Sign in to get full access
Overview
- The paper presents "Music2Latent," a consistency autoencoder for latent audio compression.
- It aims to learn a compact and consistent latent representation of audio data that can be used for efficient storage and transmission.
- The model is trained to preserve the salient features of the original audio while compressing it into a low-dimensional latent space.
Plain English Explanation
The paper introduces a new machine learning model called "Music2Latent" that can take audio files, like music or speech, and compress them into a very small, efficient representation. This compressed version still captures the important information from the original audio, allowing it to be reconstructed with high quality.
The key idea is to train the model to learn a "latent space" - a compact, low-dimensional description of the audio that preserves the salient features. This latent representation can then be used for tasks like efficient storage or transmission of the audio data.
The researchers designed the model to be "consistent," meaning that small changes in the input audio result in small changes in the latent representation. This consistency property is important for many practical applications, as it allows the compressed audio to be manipulated and edited while maintaining the original character.
Overall, this work presents a promising approach for compressing and representing audio data in a way that is both efficient and preserves the essential qualities of the original signal. This could have implications for a variety of audio-based technologies, from music streaming to voice-based user interfaces.
Technical Explanation
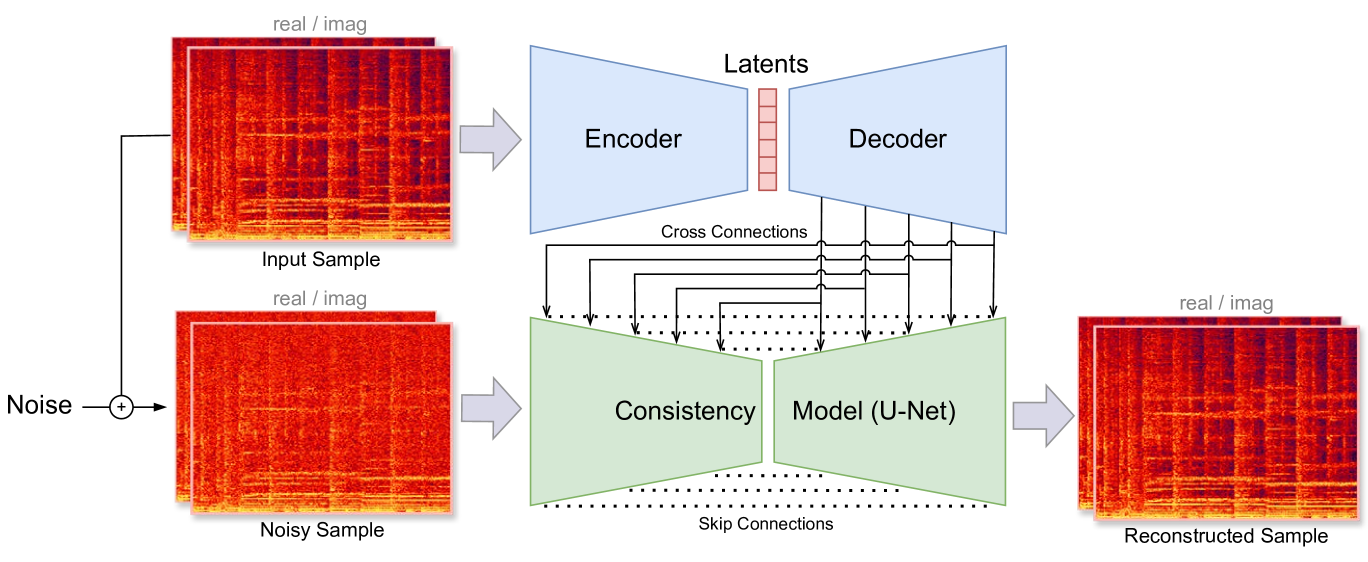
The core of the "Music2Latent" model is a consistency autoencoder architecture. An autoencoder is a type of neural network that learns to compress and then reconstruct input data, in this case, audio waveforms.
The key innovation is the consistency regularization applied during training. This encourages the model to learn a latent representation where small perturbations in the input result in small changes in the latent code. The researchers achieve this by adding a consistency loss term that penalizes large gradients of the latent code with respect to the input.
Experiments show that this consistency property leads to several benefits:
-
Compression Efficiency: The latent codes produced by Music2Latent can represent the original audio with high fidelity using far fewer dimensions than alternative approaches.
-
Stability and Robustness: The consistent latent space makes the reconstructed audio more resilient to noise or other minor distortions in the input.
-
Downstream Task Performance: The learned latent representations are shown to be effective for tasks like audio classification and generation, outperforming prior latent compression methods.
The paper provides detailed results on standard audio datasets, comparing Music2Latent to baselines like variational autoencoders and adversarial autoencoders. The consistent latent space is empirically demonstrated to provide advantages in terms of compression rate, reconstruction quality, and performance on downstream applications.
Critical Analysis
The paper makes a strong case for the effectiveness of the proposed consistency regularization approach for learning compact, high-quality latent representations of audio data. However, a few potential limitations and avenues for future work are worth considering:
-
Generalization to Diverse Audio Domains: The evaluation is focused on musical audio and speech, but it's unclear how well the approach would generalize to more diverse audio signals, such as environmental sounds or audio from videos.
-
Interpretability of Latent Representations: While the consistency property is desirable for many applications, it's not clear how interpretable or semantically meaningful the learned latent dimensions are. Exploring ways to inject more interpretability could expand the usefulness of the approach.
-
Real-Time or Streaming Capabilities: The current model operates on fixed-length audio clips, but many practical audio applications require real-time or streaming processing capabilities. Extending the approach to handle variable-length or streaming audio inputs could be a valuable direction.
-
Computational Efficiency: While the latent representations are compact, the training and inference costs of the consistency autoencoder model are not extensively discussed. Investigating ways to further optimize the computational efficiency could broaden the applicability of the technique.
Overall, the "Music2Latent" model presents a compelling approach for learning consistent, low-dimensional representations of audio data. With further exploration of the limitations and potential extensions outlined above, this work could have significant impact on a variety of audio-based technologies and applications.
Conclusion
The "Music2Latent" paper introduces a novel consistency autoencoder architecture for learning compact, high-quality latent representations of audio data. By incorporating a consistency regularization term during training, the model is able to learn a latent space where small changes in the input result in small changes in the latent code.
This consistency property provides several benefits, including improved compression efficiency, increased robustness to input perturbations, and better performance on downstream tasks like audio classification and generation. The empirical results demonstrate the effectiveness of the approach compared to prior latent compression methods.
While the paper focuses on musical audio and speech, the consistency autoencoder framework could potentially be extended to other audio domains and applications. Exploring ways to further improve the interpretability, computational efficiency, and real-time capabilities of the model could unlock even more impactful uses of this technology.
Overall, the "Music2Latent" work represents an important advance in the field of audio representation learning, with the potential to enable more efficient and robust audio-based systems across a wide range of industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Music2Latent: Consistency Autoencoders for Latent Audio Compression
Marco Pasini, Stefan Lattner, George Fazekas
Efficient audio representations in a compressed continuous latent space are critical for generative audio modeling and Music Information Retrieval (MIR) tasks. However, some existing audio autoencoders have limitations, such as multi-stage training procedures, slow iterative sampling, or low reconstruction quality. We introduce Music2Latent, an audio autoencoder that overcomes these limitations by leveraging consistency models. Music2Latent encodes samples into a compressed continuous latent space in a single end-to-end training process while enabling high-fidelity single-step reconstruction. Key innovations include conditioning the consistency model on upsampled encoder outputs at all levels through cross connections, using frequency-wise self-attention to capture long-range frequency dependencies, and employing frequency-wise learned scaling to handle varying value distributions across frequencies at different noise levels. We demonstrate that Music2Latent outperforms existing continuous audio autoencoders in sound quality and reconstruction accuracy while achieving competitive performance on downstream MIR tasks using its latent representations. To our knowledge, this represents the first successful attempt at training an end-to-end consistency autoencoder model.
Read more8/14/2024
0
Music Consistency Models
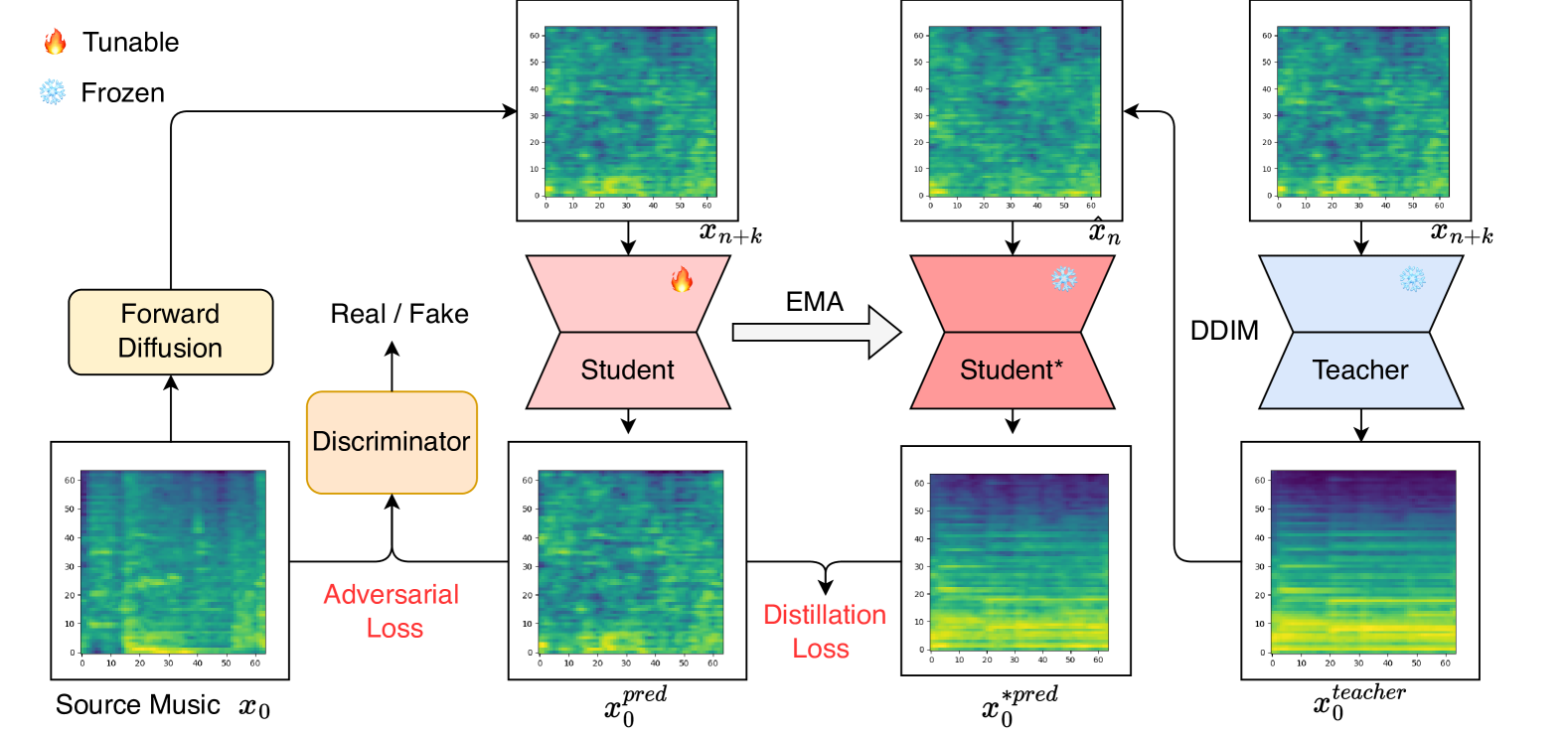
Zhengcong Fei, Mingyuan Fan, Junshi Huang
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
Read more4/23/2024

0
Combining audio control and style transfer using latent diffusion
Nils Demerl'e, Philippe Esling, Guillaume Doras, David Genova
Deep generative models are now able to synthesize high-quality audio signals, shifting the critical aspect in their development from audio quality to control capabilities. Although text-to-music generation is getting largely adopted by the general public, explicit control and example-based style transfer are more adequate modalities to capture the intents of artists and musicians. In this paper, we aim to unify explicit control and style transfer within a single model by separating local and global information to capture musical structure and timbre respectively. To do so, we leverage the capabilities of diffusion autoencoders to extract semantic features, in order to build two representation spaces. We enforce disentanglement between those spaces using an adversarial criterion and a two-stage training strategy. Our resulting model can generate audio matching a timbre target, while specifying structure either with explicit controls or through another audio example. We evaluate our model on one-shot timbre transfer and MIDI-to-audio tasks on instrumental recordings and show that we outperform existing baselines in terms of audio quality and target fidelity. Furthermore, we show that our method can generate cover versions of complete musical pieces by transferring rhythmic and melodic content to the style of a target audio in a different genre.
Read more8/2/2024
0
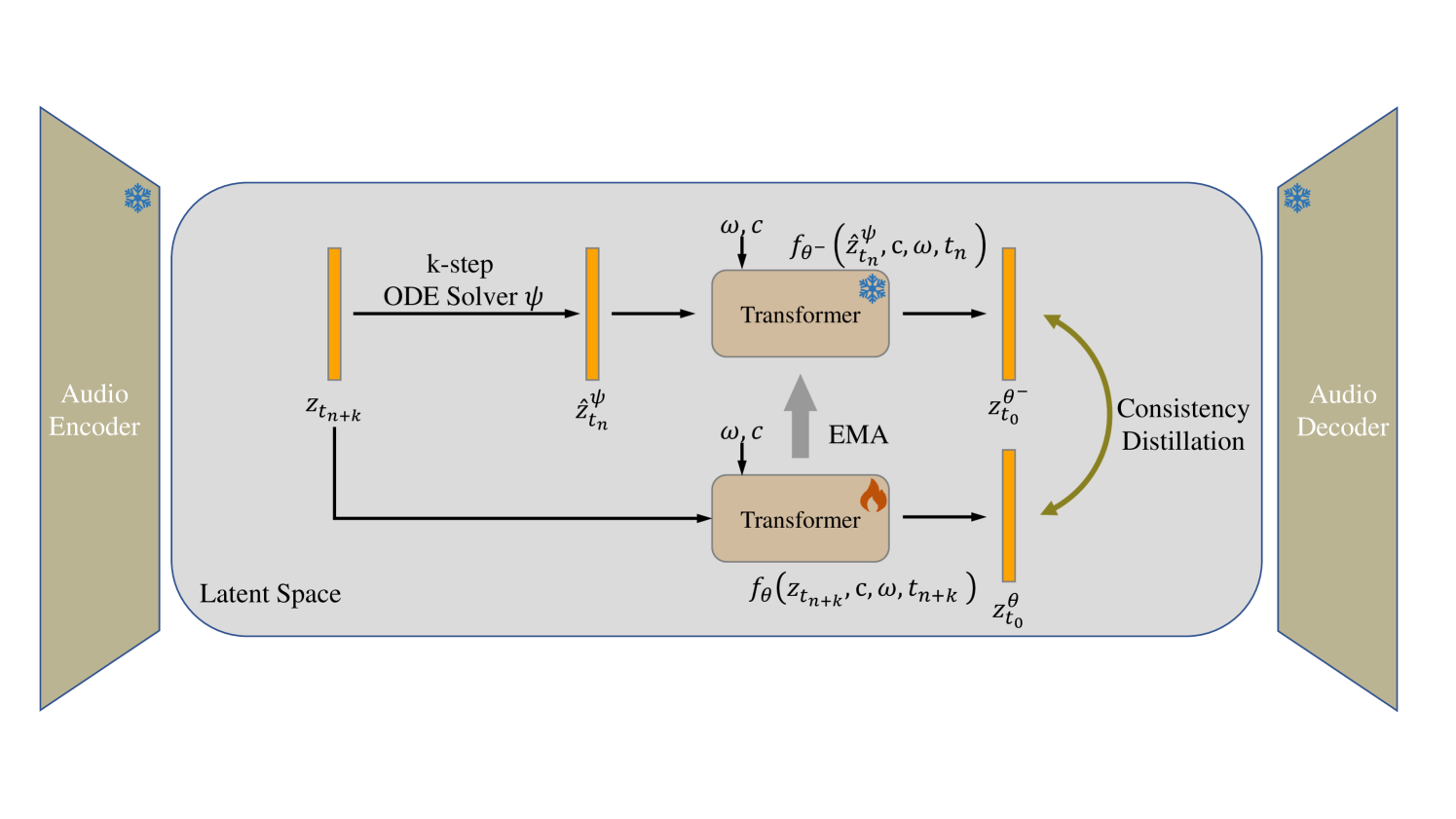
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
Read more7/10/2024