VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
2306.08707
0
0

Abstract
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, existing diffusion-based video editing approaches lack the ability to offer precise control over generated content that maintains temporal consistency in long-term videos. On the other hand, atlas-based methods provide strong temporal consistency but are costly to edit a video and lack spatial control. In this work, we introduce VidEdit, a novel method for zero-shot text-based video editing that guarantees robust temporal and spatial consistency. In particular, we combine an atlas-based video representation with a pre-trained text-to-image diffusion model to provide a training-free and efficient video editing method, which by design fulfills temporal smoothness. To grant precise user control over generated content, we utilize conditional information extracted from off-the-shelf panoptic segmenters and edge detectors which guides the diffusion sampling process. This method ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Our quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt. Project web-page at https://videdit.github.io
Create account to get full access
Overview
- This paper introduces VidEdit, a system that enables zero-shot and spatially aware text-driven video editing.
- VidEdit allows users to modify videos by providing text descriptions, without requiring extensive training data or manual annotations.
- The system can perform various video editing tasks, such as object removal, color adjustments, and scene composition changes, based on the provided text instructions.
- VidEdit leverages a novel spatial-aware text-to-video generation approach to understand the spatial context and make targeted edits to the video.
Plain English Explanation
VidEdit is a powerful tool that lets you edit videos just by describing what you want to change in words. Typically, video editing requires lots of practice, specialized software, and manual effort to make even simple changes. VidEdit simplifies this process by letting you type out instructions, and the system will automatically make the edits for you.
For example, you could type "remove the car from the street" or "make the sky bluer," and VidEdit will analyze the video and modify it accordingly. This is possible because VidEdit has been trained on a large amount of video data and text descriptions, allowing it to understand the spatial context of the video and make targeted changes based on the provided text.
The key innovation is that VidEdit doesn't require you to have a lot of training data or manually annotate the videos beforehand. It can work with just the raw video and your text instructions, making it much more accessible and versatile than traditional video editing tools. This opens up new possibilities for quickly and easily modifying videos to fit your needs or creative vision.
Technical Explanation
VidEdit is built on a novel spatial-aware text-to-video generation approach. It consists of two main components: a text encoder and a video generator. The text encoder takes the user's text instructions as input and extracts a semantic representation that captures the desired edits. The video generator then uses this representation to modify the original video, making the requested changes while preserving the overall spatial layout and coherence of the scene.
The system is trained in a zero-shot manner, meaning it can perform video editing tasks without requiring extensive training data or manual annotations. VidEdit leverages large-scale video and text datasets to learn the associations between language and visual content, enabling it to generalize to new videos and text prompts.
The key technical insights behind VidEdit include:
- Spatial Awareness: The system understands the spatial relationships in the video, allowing it to make localized edits instead of global changes.
- Zero-shot Capability: VidEdit can perform various editing tasks without the need for task-specific training or annotations.
- Flexible Text Prompts: Users can provide a wide range of natural language instructions, and the system will interpret and apply the desired edits.
Through extensive experiments, the authors demonstrate VidEdit's ability to outperform existing text-to-video generation methods on a variety of video editing tasks, including object removal, color adjustment, and scene composition changes.
Critical Analysis
The paper presents a compelling approach to text-driven video editing, addressing several limitations of existing systems. However, there are a few potential caveats and areas for further research:
Handling Complex Scenes: While VidEdit shows promising results, it may struggle with highly complex scenes or videos with intricate spatial relationships. The authors acknowledge that the system's performance could be impacted by the complexity of the input video.
Temporal Coherence: The paper focuses on individual frame-level edits, but maintaining temporal coherence across the entire video sequence could be a challenging next step. Ensuring that edits blend seamlessly and do not introduce jarring artifacts is an important consideration.
Generalization to Diverse Domains: The evaluation in the paper is limited to a specific dataset of urban scenes. Assessing VidEdit's performance on videos from diverse domains, such as nature, sports, or artistic scenes, would help gauge its broader applicability.
User Experience and Interaction: The paper does not delve into the user experience aspects of VidEdit. Exploring intuitive interfaces and interaction paradigms for text-driven video editing could further enhance the system's accessibility and usability.
Despite these potential areas for improvement, VidEdit represents a significant step forward in democratizing video editing by leveraging natural language instructions. The spatial awareness and zero-shot capabilities are particularly noteworthy and could inspire future research in this direction.
Conclusion
VidEdit is an innovative system that enables users to edit videos simply by describing the changes they want to make in natural language. By understanding the spatial context of the video and leveraging zero-shot learning, VidEdit opens up new possibilities for accessible and expressive video editing. This technology has the potential to empower a wider range of users, from casual video creators to professional filmmakers, to efficiently modify and enhance their video content. As the field of computer vision and language understanding continues to advance, tools like VidEdit will likely become increasingly important in shaping the future of video creation and manipulation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices
Nathaniel Cohen, Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, Tomer Michaeli
0
0
Text-to-image (T2I) diffusion models achieve state-of-the-art results in image synthesis and editing. However, leveraging such pretrained models for video editing is considered a major challenge. Many existing works attempt to enforce temporal consistency in the edited video through explicit correspondence mechanisms, either in pixel space or between deep features. These methods, however, struggle with strong nonrigid motion. In this paper, we introduce a fundamentally different approach, which is based on the observation that spatiotemporal slices of natural videos exhibit similar characteristics to natural images. Thus, the same T2I diffusion model that is normally used only as a prior on video frames, can also serve as a strong prior for enhancing temporal consistency by applying it on spatiotemporal slices. Based on this observation, we present Slicedit, a method for text-based video editing that utilizes a pretrained T2I diffusion model to process both spatial and spatiotemporal slices. Our method generates videos that retain the structure and motion of the original video while adhering to the target text. Through extensive experiments, we demonstrate Slicedit's ability to edit a wide range of real-world videos, confirming its clear advantages compared to existing competing methods. Webpage: https://matankleiner.github.io/slicedit/
5/21/2024

I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
Wenqi Ouyang, Yi Dong, Lei Yang, Jianlou Si, Xingang Pan
0
0
The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
5/28/2024
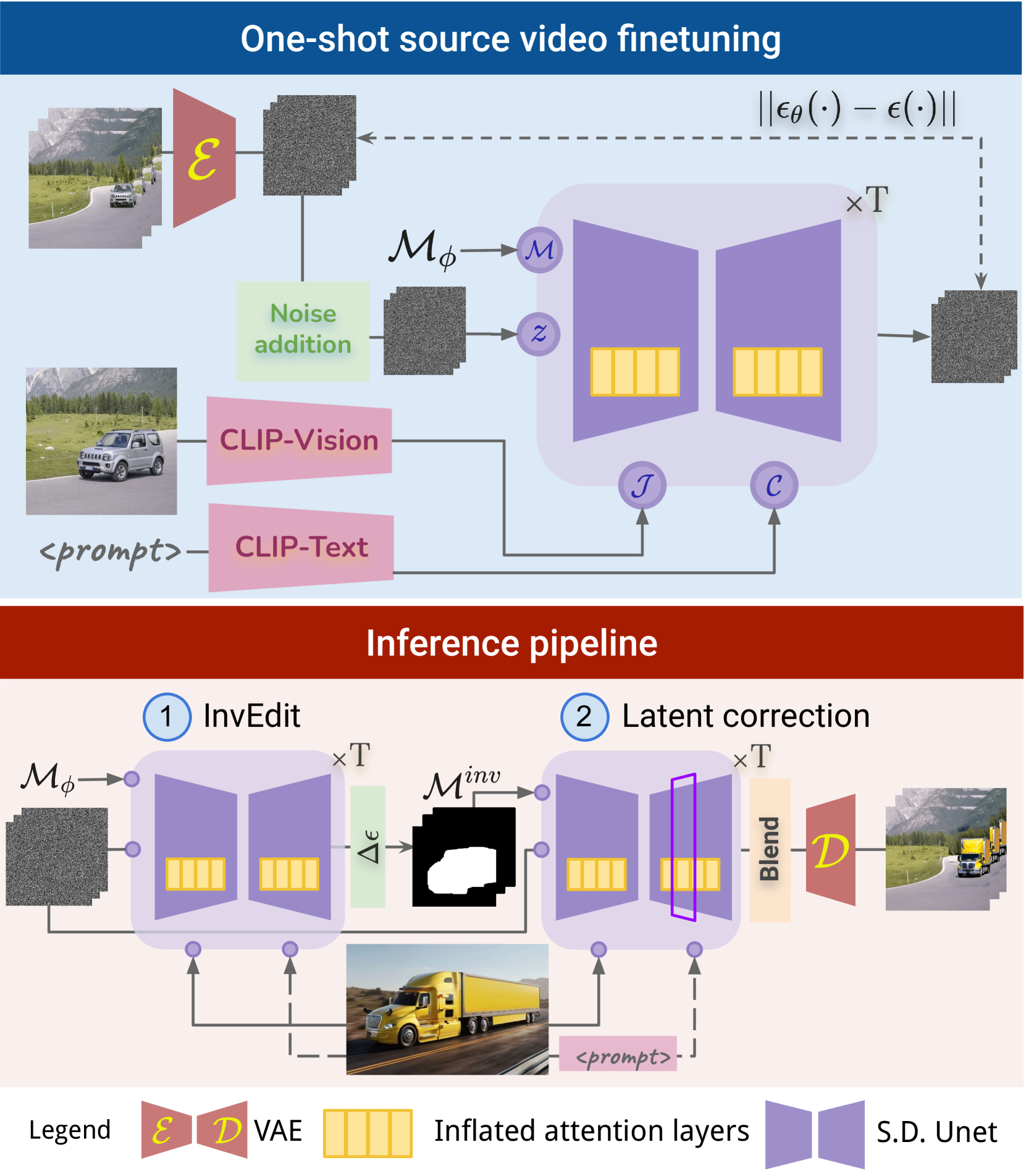
GenVideo: One-shot Target-image and Shape Aware Video Editing using T2I Diffusion Models
Sai Sree Harsha, Ambareesh Revanur, Dhwanit Agarwal, Shradha Agrawal
0
0
Video editing methods based on diffusion models that rely solely on a text prompt for the edit are hindered by the limited expressive power of text prompts. Thus, incorporating a reference target image as a visual guide becomes desirable for precise control over edit. Also, most existing methods struggle to accurately edit a video when the shape and size of the object in the target image differ from the source object. To address these challenges, we propose GenVideo for editing videos leveraging target-image aware T2I models. Our approach handles edits with target objects of varying shapes and sizes while maintaining the temporal consistency of the edit using our novel target and shape aware InvEdit masks. Further, we propose a novel target-image aware latent noise correction strategy during inference to improve the temporal consistency of the edits. Experimental analyses indicate that GenVideo can effectively handle edits with objects of varying shapes, where existing approaches fail.
4/22/2024
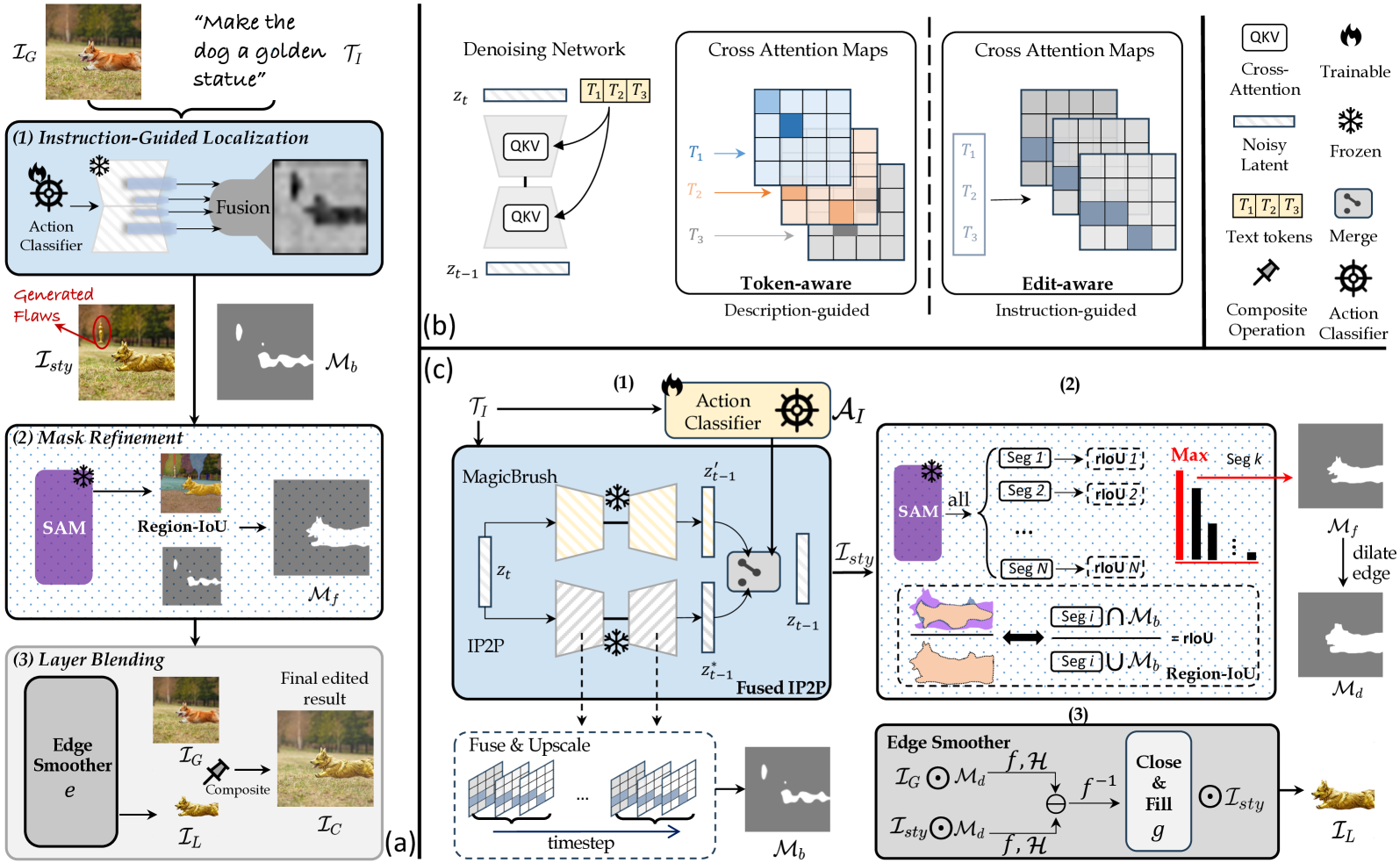
ZONE: Zero-Shot Instruction-Guided Local Editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xuhui Liu, Jiaming Liu, Li Lin, Xu Tang, Yao Hu, Jianzhuang Liu, Baochang Zhang
0
0
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., make his tie blue) into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods. Code is available at https://github.com/lsl001006/ZONE.
4/15/2024