MusicScore: A Dataset for Music Score Modeling and Generation
2406.11462
0
0

Abstract
Music scores are written representations of music and contain rich information about musical components. The visual information on music scores includes notes, rests, staff lines, clefs, dynamics, and articulations. This visual information in music scores contains more semantic information than audio and symbolic representations of music. Previous music score datasets have limited sizes and are mainly designed for optical music recognition (OMR). There is a lack of research on creating a large-scale benchmark dataset for music modeling and generation. In this work, we propose MusicScore, a large-scale music score dataset collected and processed from the International Music Score Library Project (IMSLP). MusicScore consists of image-text pairs, where the image is a page of a music score and the text is the metadata of the music. The metadata of MusicScore is extracted from the general information section of the IMSLP pages. The metadata includes rich information about the composer, instrument, piece style, and genre of the music pieces. MusicScore is curated into small, medium, and large scales of 400, 14k, and 200k image-text pairs with varying diversity, respectively. We build a score generation system based on a UNet diffusion model to generate visually readable music scores conditioned on text descriptions to benchmark the MusicScore dataset for music score generation. MusicScore is released to the public at https://huggingface.co/datasets/ZheqiDAI/MusicScore.
Create account to get full access
Overview
• This paper introduces the MusicScore dataset, a large-scale collection of musical scores and associated metadata, aimed at advancing research in music score modeling and generation.
• The dataset includes over 1 million musical scores spanning a variety of genres, along with metadata such as composer, instrumentation, and musical keys.
• The authors demonstrate the utility of the dataset by training several machine learning models for music score generation and analysis, and they discuss the potential applications and limitations of the dataset.
Plain English Explanation
The researchers have created a new dataset called MusicScore that contains a huge number of musical scores, over 1 million in total. These scores cover a wide range of musical styles and genres, and they come with additional information like who composed the music, what instruments are used, and the musical keys.
The goal of this dataset is to help researchers develop better algorithms and models for working with musical scores. For example, they might use the dataset to train machine learning models that can generate new musical scores or analyze the structure and style of existing ones.
By having access to such a large and diverse collection of musical scores, researchers can explore new approaches to music generation and analysis, which could lead to exciting advancements in areas like computer-assisted composition, music education, and music information retrieval.
Technical Explanation
The MusicScore dataset consists of over 1 million musical scores in the MusicXML format, which is a widely-used standard for representing musical notation digitally. The dataset covers a variety of musical genres, including classical, jazz, and popular music, and includes metadata such as composer, instrumentation, and musical keys.
The authors demonstrate the utility of the dataset by training several machine learning models for tasks like music score generation and analysis. For example, they train a Transformer-based model to generate new musical scores conditioned on genre and other metadata, and they train a convolutional neural network to classify musical scores by their style and composer.
The authors also discuss the potential applications of the MusicScore dataset, such as in computer-assisted composition, music education, and music information retrieval. They also acknowledge the limitations of the dataset, such as the potential for biases in the collected scores, and suggest areas for further research and development.
Critical Analysis
The MusicScore dataset represents a significant contribution to the field of music generation and analysis, as it provides researchers with a large and diverse collection of musical scores to work with.
One potential limitation of the dataset is the potential for biases in the collected scores, as the authors acknowledge. It's possible that the dataset may over-represent certain genres, composers, or styles of music, which could impact the generalizability of models trained on the data.
Additionally, the dataset does not include any audio recordings or other multimedia content associated with the musical scores. While the scores themselves are valuable, the inclusion of audio data could further enhance the dataset's utility for tasks like audio-to-score alignment or cross-modal music generation, as explored in studies like MeloFusion and MusiLingo.
Overall, the MusicScore dataset is a valuable resource for researchers working in music generation and analysis, and the authors' demonstration of its utility is promising. However, further research is needed to address the potential biases and limitations of the dataset, as well as to explore ways to integrate it with other relevant datasets, such as those focused on audio, video, and text-based music information, like NES and MOSA.
Conclusion
The MusicScore dataset represents a significant advancement in the field of music generation and analysis, providing researchers with a large and diverse collection of musical scores and associated metadata.
By training machine learning models on this dataset, researchers can explore new approaches to tasks like music score generation and analysis, which could lead to exciting advancements in areas like computer-assisted composition, music education, and music information retrieval.
While the dataset has some potential limitations, such as the possibility of biases in the collected scores, the authors' demonstration of its utility is promising, and further research is needed to address these challenges and integrate the dataset with other relevant resources in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MidiCaps -- A large-scale MIDI dataset with text captions
Jan Melechovsky, Abhinaba Roy, Dorien Herremans
0
0
Generative models guided by text prompts are increasingly becoming more popular. However, no text-to-MIDI models currently exist, mostly due to the lack of a captioned MIDI dataset. This work aims to enable research that combines LLMs with symbolic music by presenting the first large-scale MIDI dataset with text captions that is openly available: MidiCaps. MIDI (Musical Instrument Digital Interface) files are a widely used format for encoding musical information. Their structured format captures the nuances of musical composition and has practical applications by music producers, composers, musicologists, as well as performers. Inspired by recent advancements in captioning techniques applied to various domains, we present a large-scale curated dataset of over 168k MIDI files accompanied by textual descriptions. Each MIDI caption succinctly describes the musical content, encompassing tempo, chord progression, time signature, instruments present, genre and mood; thereby facilitating multi-modal exploration and analysis. The dataset contains a mix of various genres, styles, and complexities, offering a rich source for training and evaluating models for tasks such as music information retrieval, music understanding and cross-modal translation. We provide detailed statistics about the dataset and have assessed the quality of the captions in an extensive listening study. We anticipate that this resource will stimulate further research in the intersection of music and natural language processing, fostering advancements in both fields.
6/5/2024

The Music Maestro or The Musically Challenged, A Massive Music Evaluation Benchmark for Large Language Models
Jiajia Li, Lu Yang, Mingni Tang, Cong Chen, Zuchao Li, Ping Wang, Hai Zhao
0
0
Benchmark plays a pivotal role in assessing the advancements of large language models (LLMs). While numerous benchmarks have been proposed to evaluate LLMs' capabilities, there is a notable absence of a dedicated benchmark for assessing their musical abilities. To address this gap, we present ZIQI-Eval, a comprehensive and large-scale music benchmark specifically designed to evaluate the music-related capabilities of LLMs. ZIQI-Eval encompasses a wide range of questions, covering 10 major categories and 56 subcategories, resulting in over 14,000 meticulously curated data entries. By leveraging ZIQI-Eval, we conduct a comprehensive evaluation over 16 LLMs to evaluate and analyze LLMs' performance in the domain of music. Results indicate that all LLMs perform poorly on the ZIQI-Eval benchmark, suggesting significant room for improvement in their musical capabilities. With ZIQI-Eval, we aim to provide a standardized and robust evaluation framework that facilitates a comprehensive assessment of LLMs' music-related abilities. The dataset is available at GitHubfootnote{https://github.com/zcli-charlie/ZIQI-Eval} and HuggingFacefootnote{https://huggingface.co/datasets/MYTH-Lab/ZIQI-Eval}.
6/26/2024
The NES Video-Music Database: A Dataset of Symbolic Video Game Music Paired with Gameplay Videos
Igor Cardoso, Rubens O. Moraes, Lucas N. Ferreira
0
0
Neural models are one of the most popular approaches for music generation, yet there aren't standard large datasets tailored for learning music directly from game data. To address this research gap, we introduce a novel dataset named NES-VMDB, containing 98,940 gameplay videos from 389 NES games, each paired with its original soundtrack in symbolic format (MIDI). NES-VMDB is built upon the Nintendo Entertainment System Music Database (NES-MDB), encompassing 5,278 music pieces from 397 NES games. Our approach involves collecting long-play videos for 389 games of the original dataset, slicing them into 15-second-long clips, and extracting the audio from each clip. Subsequently, we apply an audio fingerprinting algorithm (similar to Shazam) to automatically identify the corresponding piece in the NES-MDB dataset. Additionally, we introduce a baseline method based on the Controllable Music Transformer to generate NES music conditioned on gameplay clips. We evaluated this approach with objective metrics, and the results showed that the conditional CMT improves musical structural quality when compared to its unconditional counterpart. Moreover, we used a neural classifier to predict the game genre of the generated pieces. Results showed that the CMT generator can learn correlations between gameplay videos and game genres, but further research has to be conducted to achieve human-level performance.
4/9/2024
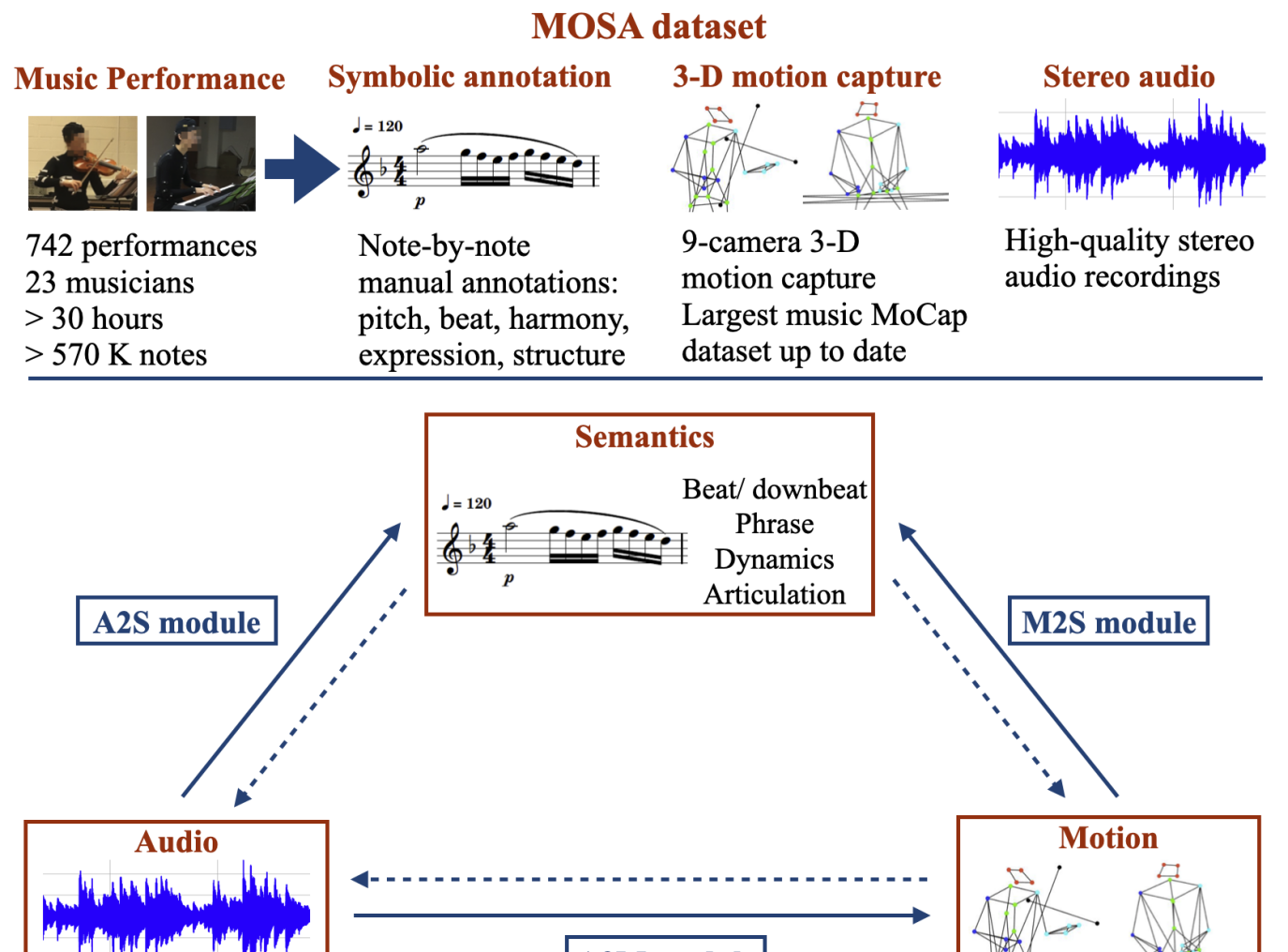
MOSA: Music Motion with Semantic Annotation Dataset for Cross-Modal Music Processing
Yu-Fen Huang, Nikki Moran, Simon Coleman, Jon Kelly, Shun-Hwa Wei, Po-Yin Chen, Yun-Hsin Huang, Tsung-Ping Chen, Yu-Chia Kuo, Yu-Chi Wei, Chih-Hsuan Li, Da-Yu Huang, Hsuan-Kai Kao, Ting-Wei Lin, Li Su
0
0
In cross-modal music processing, translation between visual, auditory, and semantic content opens up new possibilities as well as challenges. The construction of such a transformative scheme depends upon a benchmark corpus with a comprehensive data infrastructure. In particular, the assembly of a large-scale cross-modal dataset presents major challenges. In this paper, we present the MOSA (Music mOtion with Semantic Annotation) dataset, which contains high quality 3-D motion capture data, aligned audio recordings, and note-by-note semantic annotations of pitch, beat, phrase, dynamic, articulation, and harmony for 742 professional music performances by 23 professional musicians, comprising more than 30 hours and 570 K notes of data. To our knowledge, this is the largest cross-modal music dataset with note-level annotations to date. To demonstrate the usage of the MOSA dataset, we present several innovative cross-modal music information retrieval (MIR) and musical content generation tasks, including the detection of beats, downbeats, phrase, and expressive contents from audio, video and motion data, and the generation of musicians' body motion from given music audio. The dataset and codes are available alongside this publication (https://github.com/yufenhuang/MOSA-Music-mOtion-and-Semantic-Annotation-dataset).
6/11/2024