MOSA: Music Motion with Semantic Annotation Dataset for Cross-Modal Music Processing

0
Sign in to get full access
Overview
- The paper introduces MOSA, a new dataset that captures the relationship between music and human motion.
- MOSA includes motion capture data, music recordings, and semantic annotations that describe the emotional and expressive qualities of the music-motion pairs.
- The dataset is designed to support cross-modal research in areas like music information retrieval, motion analysis, and multimedia understanding.
Plain English Explanation
The researchers have created a new dataset called MOSA that explores the connection between music and human movement. MOSA includes motion capture data, which records the detailed movements of people as they dance or perform to music. It also includes the actual music recordings and annotations that describe the emotional and expressive qualities of the music-motion pairings.
This dataset is designed to help researchers understand the relationship between sound and movement. For example, scientists could use MOSA to study how certain musical elements like rhythm or melody influence the way people move their bodies. Or they could investigate how different emotional expressions in music are reflected in physical movements.
The goal is to enable new types of cross-modal research that combine insights from music, motion, and semantic information. This could lead to applications like improved systems for automatically analyzing or generating human motion based on audio cues, or new interactive experiences that more closely integrate music and movement.
Technical Explanation
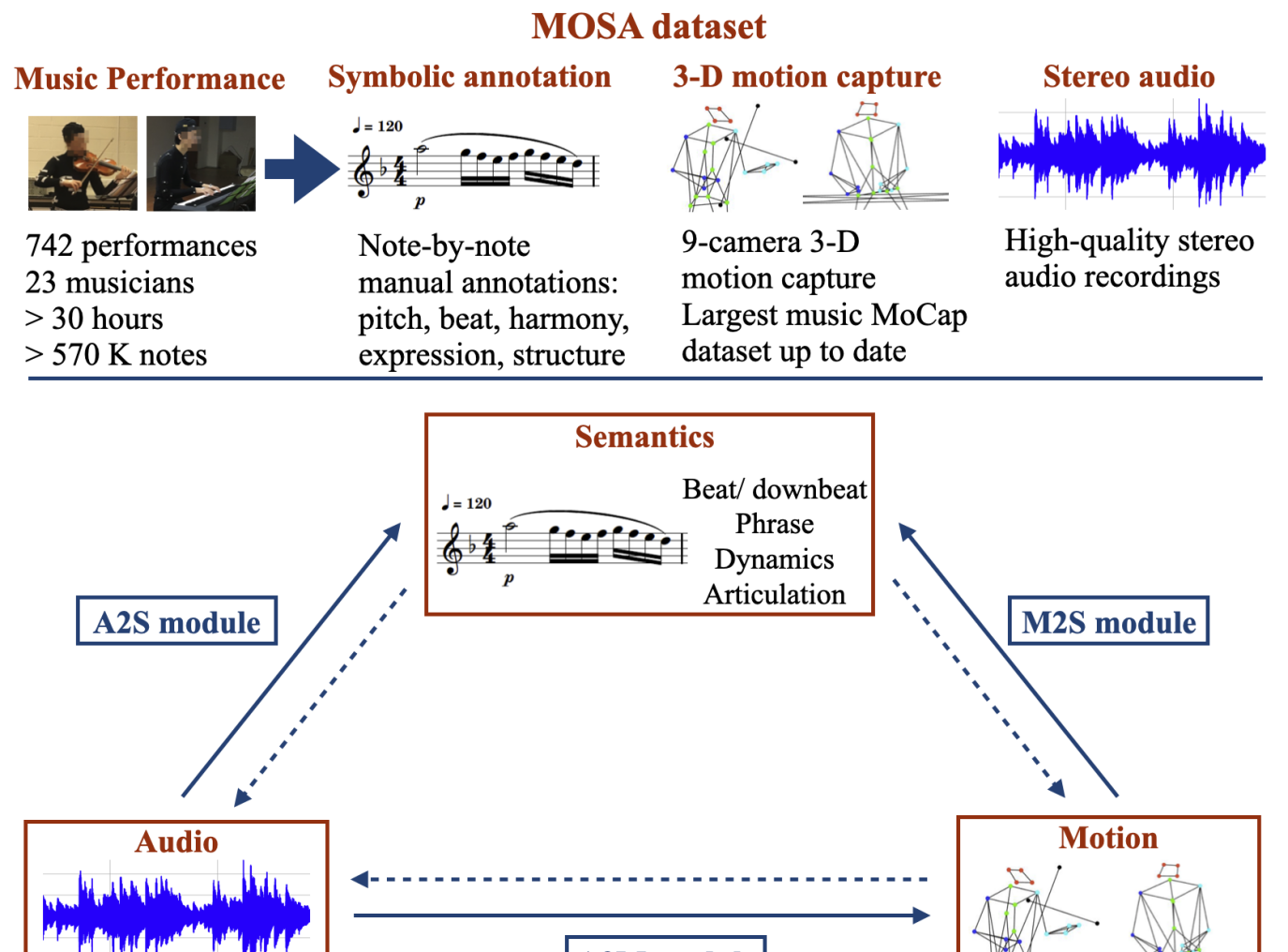
The MOSA dataset contains 3D motion capture data, corresponding music recordings, and semantic annotations that describe the expressive and emotional qualities of the music-motion pairs. The motion data was collected from professional dancers performing to a variety of musical genres, including pop, classical, and electronic. The semantic labels cover attributes like arousal, valence, and movement qualities.
The researchers designed MOSA to enable cross-modal machine learning research. By providing aligned audiovisual data with rich semantic annotations, MOSA can support the development of models that learn to understand the relationships between music, movement, and emotional expression. This could lead to breakthroughs in areas like automated choreography generation, expressive motion synthesis, and interactive music experiences.
The dataset includes a total of 33 hours of motion capture data and 8 hours of music recordings, spanning over 2,000 individual trials. The researchers conducted extensive preprocessing and cleaning to ensure high-quality, synchronized data. They also provide baseline models and performance metrics to facilitate research using the dataset.
Critical Analysis
The MOSA dataset represents a valuable contribution to the field of multimodal research. By capturing the rich interplay between music and human movement, along with detailed semantic annotations, it opens up new possibilities for computational approaches to understanding expressive audiovisual phenomena.
That said, the dataset does have some limitations. The motion capture was conducted in a controlled lab setting, which may not fully reflect the natural variability and spontaneity of real-world music and dance interactions. Additionally, the semantic labels, while comprehensive, could be subjective and may not fully capture the nuanced emotional experiences associated with the music-motion pairings.
Further research is needed to explore the generalizability of models trained on MOSA, as well as to investigate the role of individual differences, cultural contexts, and other factors that may influence the relationships between music and movement. Incorporating additional modalities, such as physiological data or first-person perspectives, could also lead to a more holistic understanding of the phenomenon.
Conclusion
The MOSA dataset provides a valuable resource for researchers interested in exploring the complex interplay between music and human motion. By combining high-quality motion capture data, music recordings, and semantic annotations, it enables new avenues of cross-modal research that could lead to advancements in areas like interactive music experiences, automated choreography generation, and expressive motion synthesis. As the field of multimodal AI continues to evolve, datasets like MOSA will play an increasingly important role in driving innovation and pushing the boundaries of what's possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MOSA: Music Motion with Semantic Annotation Dataset for Cross-Modal Music Processing
Yu-Fen Huang, Nikki Moran, Simon Coleman, Jon Kelly, Shun-Hwa Wei, Po-Yin Chen, Yun-Hsin Huang, Tsung-Ping Chen, Yu-Chia Kuo, Yu-Chi Wei, Chih-Hsuan Li, Da-Yu Huang, Hsuan-Kai Kao, Ting-Wei Lin, Li Su
In cross-modal music processing, translation between visual, auditory, and semantic content opens up new possibilities as well as challenges. The construction of such a transformative scheme depends upon a benchmark corpus with a comprehensive data infrastructure. In particular, the assembly of a large-scale cross-modal dataset presents major challenges. In this paper, we present the MOSA (Music mOtion with Semantic Annotation) dataset, which contains high quality 3-D motion capture data, aligned audio recordings, and note-by-note semantic annotations of pitch, beat, phrase, dynamic, articulation, and harmony for 742 professional music performances by 23 professional musicians, comprising more than 30 hours and 570 K notes of data. To our knowledge, this is the largest cross-modal music dataset with note-level annotations to date. To demonstrate the usage of the MOSA dataset, we present several innovative cross-modal music information retrieval (MIR) and musical content generation tasks, including the detection of beats, downbeats, phrase, and expressive contents from audio, video and motion data, and the generation of musicians' body motion from given music audio. The dataset and codes are available alongside this publication (https://github.com/yufenhuang/MOSA-Music-mOtion-and-Semantic-Annotation-dataset).
Read more6/11/2024

0
SingMOS: An extensive Open-Source Singing Voice Dataset for MOS Prediction
Yuxun Tang, Jiatong Shi, Yuning Wu, Qin Jin
In speech generation tasks, human subjective ratings, usually referred to as the opinion score, are considered the gold standard for speech quality evaluation, with the mean opinion score (MOS) serving as the primary evaluation metric. Due to the high cost of human annotation, several MOS prediction systems have emerged in the speech domain, demonstrating good performance. These MOS prediction models are trained using annotations from previous speech-related challenges. However, compared to the speech domain, the singing domain faces data scarcity and stricter copyright protections, leading to a lack of high-quality MOS-annotated datasets for singing. To address this, we propose SingMOS, a high-quality and diverse MOS dataset for singing, covering a range of Chinese and Japanese datasets. These synthesized vocals are generated using state-of-the-art models in singing synthesis, conversion, or resynthesis tasks and are rated by professional annotators alongside real vocals. Data analysis demonstrates the diversity and reliability of our dataset. Additionally, we conduct further exploration on SingMOS, providing insights for singing MOS prediction and guidance for the continued expansion of SingMOS.
Read more6/21/2024

0
VMAS: Video-to-Music Generation via Semantic Alignment in Web Music Videos
Yan-Bo Lin, Yu Tian, Linjie Yang, Gedas Bertasius, Heng Wang
We present a framework for learning to generate background music from video inputs. Unlike existing works that rely on symbolic musical annotations, which are limited in quantity and diversity, our method leverages large-scale web videos accompanied by background music. This enables our model to learn to generate realistic and diverse music. To accomplish this goal, we develop a generative video-music Transformer with a novel semantic video-music alignment scheme. Our model uses a joint autoregressive and contrastive learning objective, which encourages the generation of music aligned with high-level video content. We also introduce a novel video-beat alignment scheme to match the generated music beats with the low-level motions in the video. Lastly, to capture fine-grained visual cues in a video needed for realistic background music generation, we introduce a new temporal video encoder architecture, allowing us to efficiently process videos consisting of many densely sampled frames. We train our framework on our newly curated DISCO-MV dataset, consisting of 2.2M video-music samples, which is orders of magnitude larger than any prior datasets used for video music generation. Our method outperforms existing approaches on the DISCO-MV and MusicCaps datasets according to various music generation evaluation metrics, including human evaluation. Results are available at https://genjib.github.io/project_page/VMAs/index.html
Read more9/12/2024
⛏️
0
MUSES: The Multi-Sensor Semantic Perception Dataset for Driving under Uncertainty
Tim Brodermann, David Bruggemann, Christos Sakaridis, Kevin Ta, Odysseas Liagouris, Jason Corkill, Luc Van Gool
Achieving level-5 driving automation in autonomous vehicles necessitates a robust semantic visual perception system capable of parsing data from different sensors across diverse conditions. However, existing semantic perception datasets often lack important non-camera modalities typically used in autonomous vehicles, or they do not exploit such modalities to aid and improve semantic annotations in challenging conditions. To address this, we introduce MUSES, the MUlti-SEnsor Semantic perception dataset for driving in adverse conditions under increased uncertainty. MUSES includes synchronized multimodal recordings with 2D panoptic annotations for 2500 images captured under diverse weather and illumination. The dataset integrates a frame camera, a lidar, a radar, an event camera, and an IMU/GNSS sensor. Our new two-stage panoptic annotation protocol captures both class-level and instance-level uncertainty in the ground truth and enables the novel task of uncertainty-aware panoptic segmentation we introduce, along with standard semantic and panoptic segmentation. MUSES proves both effective for training and challenging for evaluating models under diverse visual conditions, and it opens new avenues for research in multimodal and uncertainty-aware dense semantic perception. Our dataset and benchmark are publicly available at https://muses.vision.ee.ethz.ch.
Read more7/18/2024