NativQA: Multilingual Culturally-Aligned Natural Query for LLMs

0

Sign in to get full access
Overview
- This paper presents NativQA, a framework for generating multilingual, culturally-aligned natural language queries for large language models (LLMs).
- The goal is to create queries that better reflect the cultural context and language patterns of diverse user populations, rather than relying on queries written from a single cultural perspective.
- The framework includes techniques for collecting and annotating natural language queries across multiple languages and cultural backgrounds.
Plain English Explanation
The researchers developed a system called NativQA to help make language models work better for people from diverse cultural backgrounds. Language models are AI systems that can understand and generate human language. However, most language models today are trained on data that reflects a limited cultural perspective, usually from English-speaking Western countries.
To address this, the NativQA framework provides a way to collect natural language queries (questions) from people across different languages and cultural contexts. This allows the creation of a more diverse dataset of queries that better represent how people from various backgrounds would naturally ask questions. By training language models on this culturally-aligned dataset, the models can learn to understand and respond to queries in a way that is more relevant and meaningful for a wider range of users.
The key innovation is the focus on capturing natural language and cultural context, rather than just translating existing queries. This helps ensure the queries reflect how people would actually ask questions in their own languages and cultural frames of reference. Overall, the goal is to make language models more inclusive and effective for global users, not just those from a Western cultural background.
Technical Explanation
The NativQA framework consists of several key components:
-
Query Collection: The researchers developed a multilingual web interface to collect natural language queries from participants across diverse cultural and linguistic backgrounds. This allowed them to gather queries phrased in the participants' own words and idioms, rather than relying on translated queries.
-
Query Annotation: Each collected query was annotated with metadata about the participant's cultural and linguistic background, as well as the intent and topic of the query. This contextual information is crucial for training language models to understand the cultural framing of the queries.
-
Query Paraphrasing: To further enrich the dataset, participants were asked to provide paraphrased versions of the queries, capturing alternative ways the same underlying intent could be expressed.
-
Multilingual Alignment: The researchers developed techniques to align the queries across languages, allowing language models to be trained on the multilingual dataset and learn cross-lingual query representations.
The resulting NativQA dataset contains over 100,000 natural language queries spanning 7 languages and a variety of cultural contexts. Experiments show that language models trained on this dataset perform better on culturally-diverse query understanding tasks compared to models trained on more limited, English-centric datasets.
Critical Analysis
The NativQA framework represents an important step towards making language models more inclusive and effective for global users. By focusing on natural language queries that reflect diverse cultural perspectives, the researchers have created a valuable dataset that can help address the cultural biases often present in language AI systems.
However, the paper does not address some potential limitations of the approach. For example, the dataset is still limited to a relatively small number of languages and cultural contexts. Expanding the coverage to a wider range of global regions and minority languages would be an important direction for future work.
Additionally, the annotation process relied on self-reported cultural background information from participants, which could be subject to biases or inconsistencies. Exploring more objective ways to capture cultural context, perhaps through computational ethnography or other methods, could further strengthen the dataset.
Despite these caveats, the NativQA framework and dataset represent a significant contribution to the field of multilingual and culturally-aware language AI. By pushing the boundaries of how we collect and model natural language queries, the researchers have laid the groundwork for more inclusive and effective language technologies that can better serve diverse global users.
Conclusion
The NativQA framework addresses a critical challenge in the development of language AI systems: ensuring they can understand and respond to queries in a way that is relevant and meaningful for users from diverse cultural backgrounds. By collecting a dataset of natural language queries that reflect the linguistic and cultural contexts of a global user population, the researchers have created a valuable resource for training more inclusive and effective language models.
While the current NativQA dataset has room for expansion and refinement, the core ideas behind the framework represent an important step forward in making language AI systems that are truly multilingual and culturally-aligned. As the field of natural language processing continues to evolve, approaches like NativQA will be essential for developing AI technologies that can serve the needs of users around the world, not just those from a limited cultural perspective.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NativQA: Multilingual Culturally-Aligned Natural Query for LLMs
Md. Arid Hasan, Maram Hasanain, Fatema Ahmad, Sahinur Rahman Laskar, Sunaya Upadhyay, Vrunda N Sukhadia, Mucahid Kutlu, Shammur Absar Chowdhury, Firoj Alam
Natural Question Answering (QA) datasets play a crucial role in developing and evaluating the capabilities of large language models (LLMs), ensuring their effective usage in real-world applications. Despite the numerous QA datasets that have been developed, there is a notable lack of region-specific datasets generated by native users in their own languages. This gap hinders the effective benchmarking of LLMs for regional and cultural specificities. In this study, we propose a scalable framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages, for LLM evaluation and tuning. Moreover, to demonstrate the efficacy of the proposed framework, we designed a multilingual natural QA dataset, MultiNativQA, consisting of ~72K QA pairs in seven languages, ranging from high to extremely low resource, based on queries from native speakers covering 18 topics. We benchmark the MultiNativQA dataset with open- and closed-source LLMs. We made both the framework NativQA and MultiNativQA dataset publicly available for the community. (https://nativqa.gitlab.io)
Read more7/16/2024
0
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
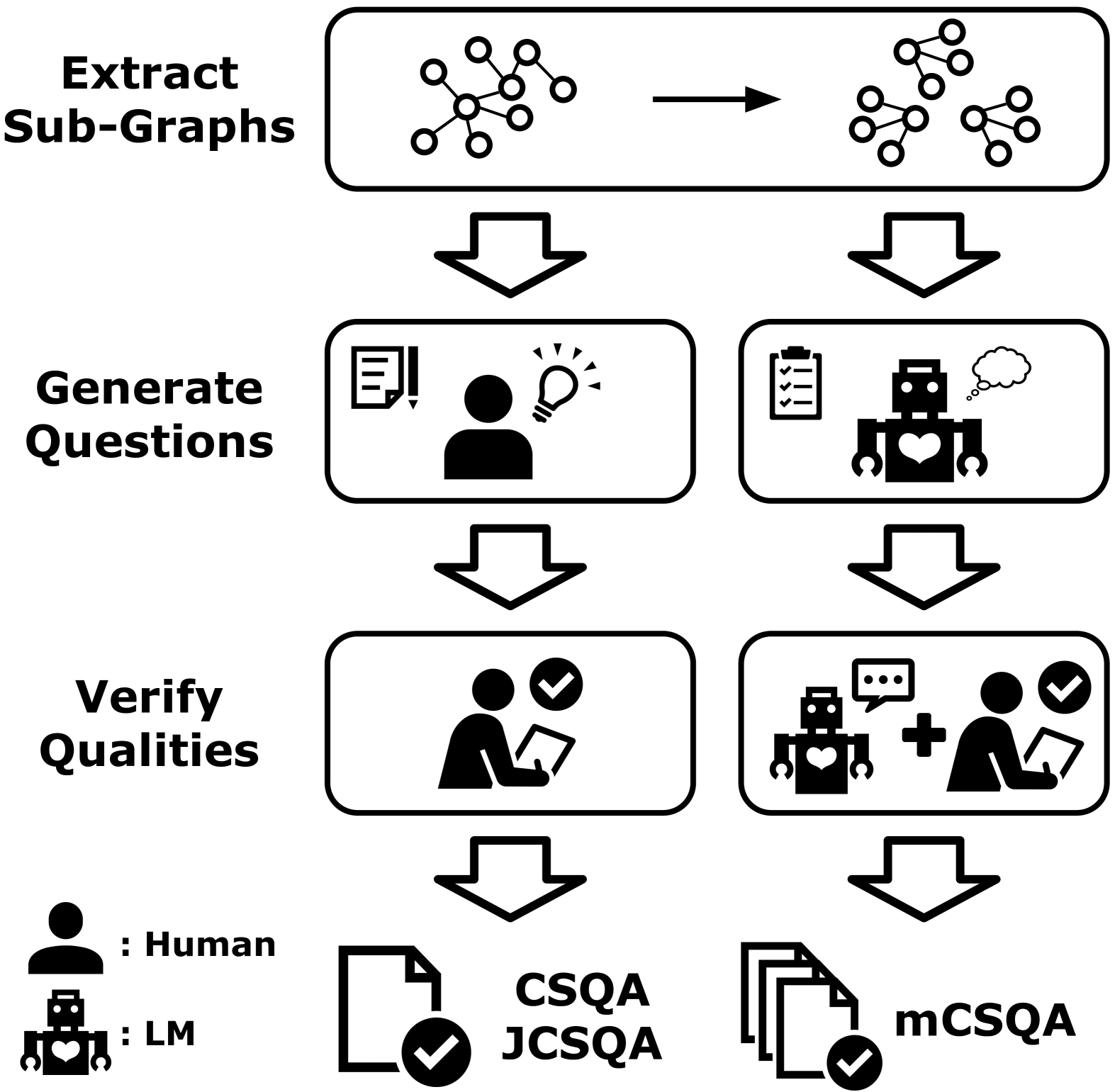
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
Read more6/7/2024
0
M2QA: Multi-domain Multilingual Question Answering
Leon Englander, Hannah Sterz, Clifton Poth, Jonas Pfeiffer, Ilia Kuznetsov, Iryna Gurevych
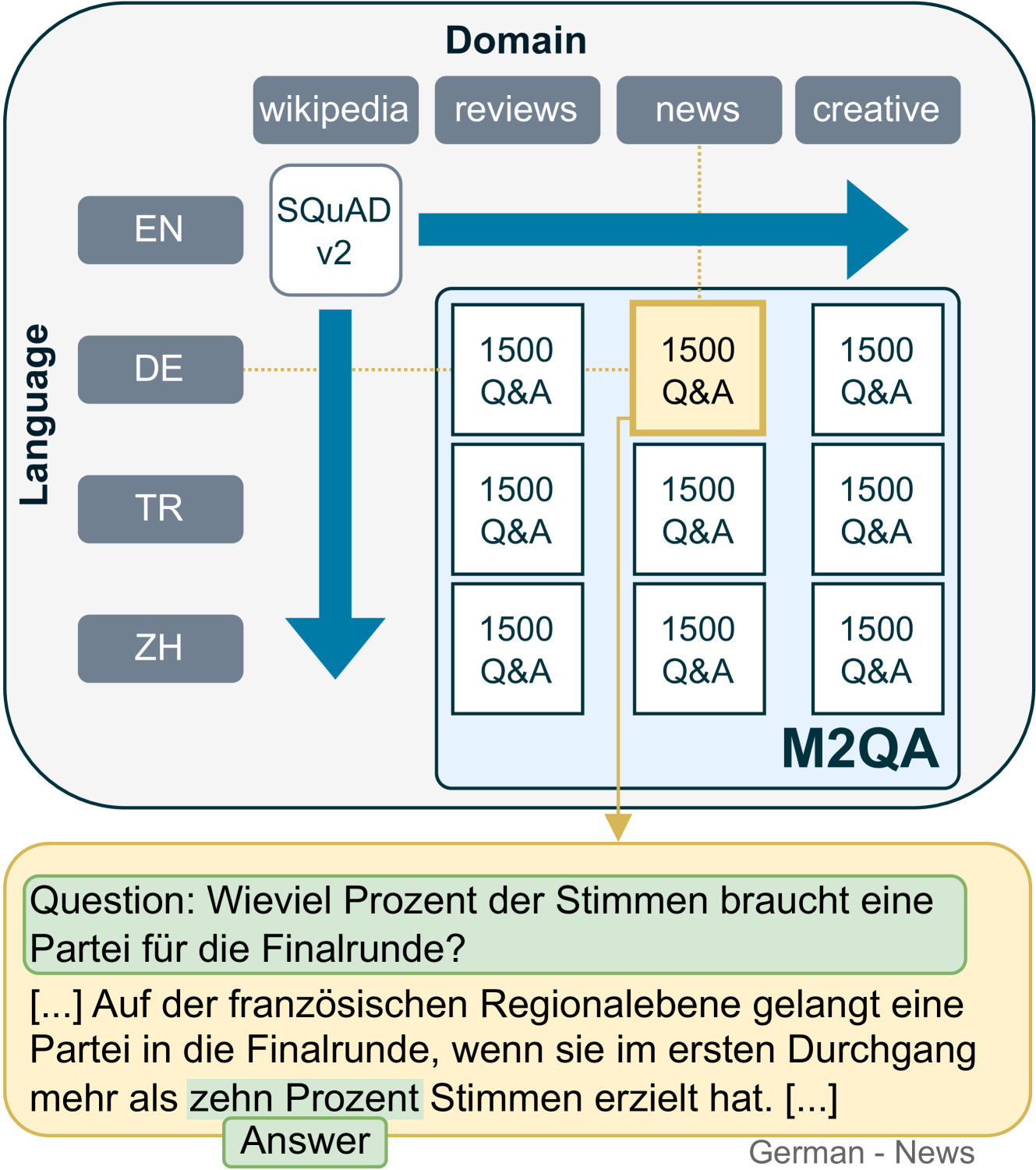
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
Read more7/2/2024

0
INDIC QA BENCHMARK: A Multilingual Benchmark to Evaluate Question Answering capability of LLMs for Indic Languages
Abhishek Kumar Singh, Rudra Murthy, Vishwajeet kumar, Jaydeep Sen, Ganesh Ramakrishnan
Large Language Models (LLMs) have demonstrated remarkable zero-shot and few-shot capabilities in unseen tasks, including context-grounded question answering (QA) in English. However, the evaluation of LLMs' capabilities in non-English languages for context-based QA is limited by the scarcity of benchmarks in non-English languages. To address this gap, we introduce Indic-QA, the largest publicly available context-grounded question-answering dataset for 11 major Indian languages from two language families. The dataset comprises both extractive and abstractive question-answering tasks and includes existing datasets as well as English QA datasets translated into Indian languages. Additionally, we generate a synthetic dataset using the Gemini model to create question-answer pairs given a passage, which is then manually verified for quality assurance. We evaluate various multilingual Large Language Models and their instruction-fine-tuned variants on the benchmark and observe that their performance is subpar, particularly for low-resource languages. We hope that the release of this dataset will stimulate further research on the question-answering abilities of LLMs for low-resource languages.
Read more7/19/2024