mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
2406.04215
0
0
Abstract
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
Create account to get full access
Overview
- The paper proposes a new multilingual commonsense reasoning dataset called mCSQA, created using a unified strategy that combines language models and human annotation.
- mCSQA covers 7 languages (English, Chinese, Spanish, German, French, Russian, and Arabic) and aims to enable the development of multilingual commonsense reasoning models.
- The dataset creation process involves generating commonsense questions using language models, followed by human validation and annotation to ensure quality and diversity.
Plain English Explanation
The researchers created a new dataset called mCSQA that tests a machine's ability to reason about common-sense knowledge. Common-sense knowledge refers to the basic, everyday understanding that humans take for granted, like knowing that water is wet or that the sun rises in the east.
The mCSQA dataset covers 7 different languages - English, Chinese, Spanish, German, French, Russian, and Arabic. This is important because most existing commonsense datasets are only available in English, which limits their usefulness for developing multilingual AI systems. By creating a multilingual dataset, the researchers hope to enable the development of AI models that can reason about common-sense knowledge across different languages and cultures.
The dataset was created using a combination of language models and human annotators. First, the language models were used to generate potential commonsense questions. Then, human annotators reviewed these questions, made edits to improve them, and provided annotations to indicate the correct answers. This combined approach of using both language models and humans is designed to ensure the dataset is high-quality, diverse, and representative of real-world common-sense reasoning.
Technical Explanation
The researchers developed a new multilingual dataset for commonsense reasoning called mCSQA. Commonsense reasoning refers to the ability to draw inferences about everyday situations and concepts that humans naturally understand.
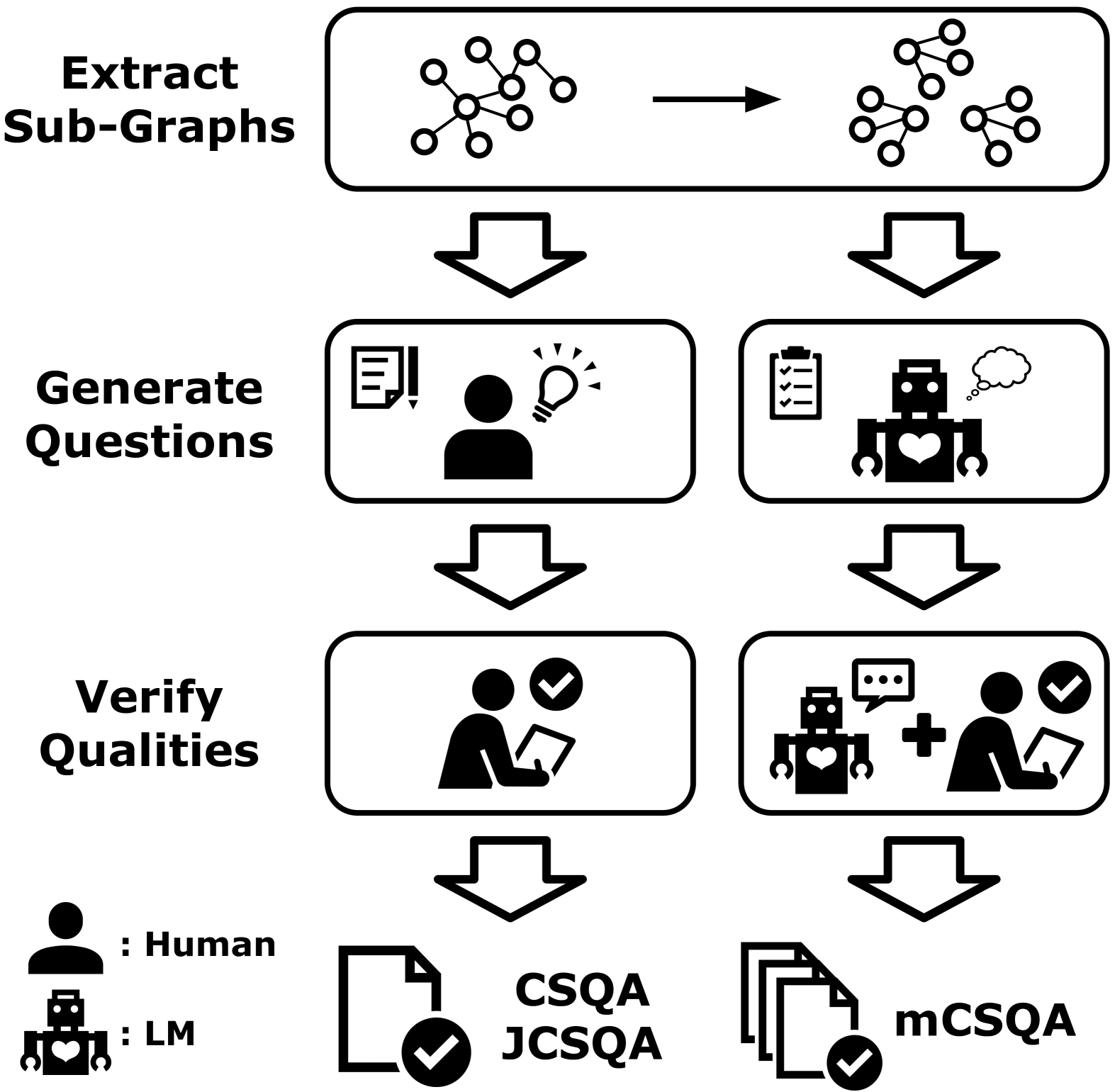
To create mCSQA, the researchers used a unified strategy that combined the capabilities of language models and human annotators. First, language models were used to generate a large pool of potential commonsense questions across the 7 target languages (English, Chinese, Spanish, German, French, Russian, and Arabic).
These generated questions were then reviewed and edited by human annotators, who ensured the questions were clear, grammatically correct, and had a single unambiguous answer. The annotators also provided labels indicating the correct answer for each question.
This hybrid approach of using both language models and human oversight was designed to produce a high-quality, diverse dataset that captures a range of commonsense reasoning abilities across multiple languages. The researchers evaluated the dataset through various metrics, including question difficulty, answer distribution, and cross-lingual performance.
Critical Analysis
The mCSQA dataset represents an important step forward in enabling multilingual commonsense reasoning research. By providing a high-quality, multilingual dataset, the researchers have addressed a key limitation of existing commonsense datasets, which have primarily been monolingual.
However, the paper does acknowledge some limitations of the dataset. First, the coverage of languages is still relatively narrow, and the dataset could be expanded to include more linguistic diversity in the future. Additionally, the dataset may not fully capture the nuances and cultural differences in how commonsense knowledge is understood across different regions and populations.
Another potential issue is the reliance on language models for the initial question generation. While the subsequent human validation and annotation process helps to ensure quality, there may still be biases or limitations inherent in the language models that could be reflected in the dataset.
Despite these caveats, the mCSQA dataset represents a valuable resource for researchers working on multilingual commonsense reasoning systems. The dataset and the unified creation strategy developed by the authors could serve as a model for the development of other multilingual NLP datasets in the future.
Conclusion
The mCSQA dataset provides a new multilingual resource for commonsense reasoning research. By combining the strengths of language models and human annotation, the researchers have created a high-quality dataset that covers 7 languages and can support the development of more robust and culturally-aware AI systems.
While the dataset has some limitations, it represents an important advancement in the field of multilingual NLP. The unified creation strategy and the resulting dataset can serve as a valuable tool for researchers working to push the boundaries of commonsense reasoning and enable AI systems that can understand and reason about the world in more human-like ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!M2QA: Multi-domain Multilingual Question Answering
Leon Englander, Hannah Sterz, Clifton Poth, Jonas Pfeiffer, Ilia Kuznetsov, Iryna Gurevych
0
0
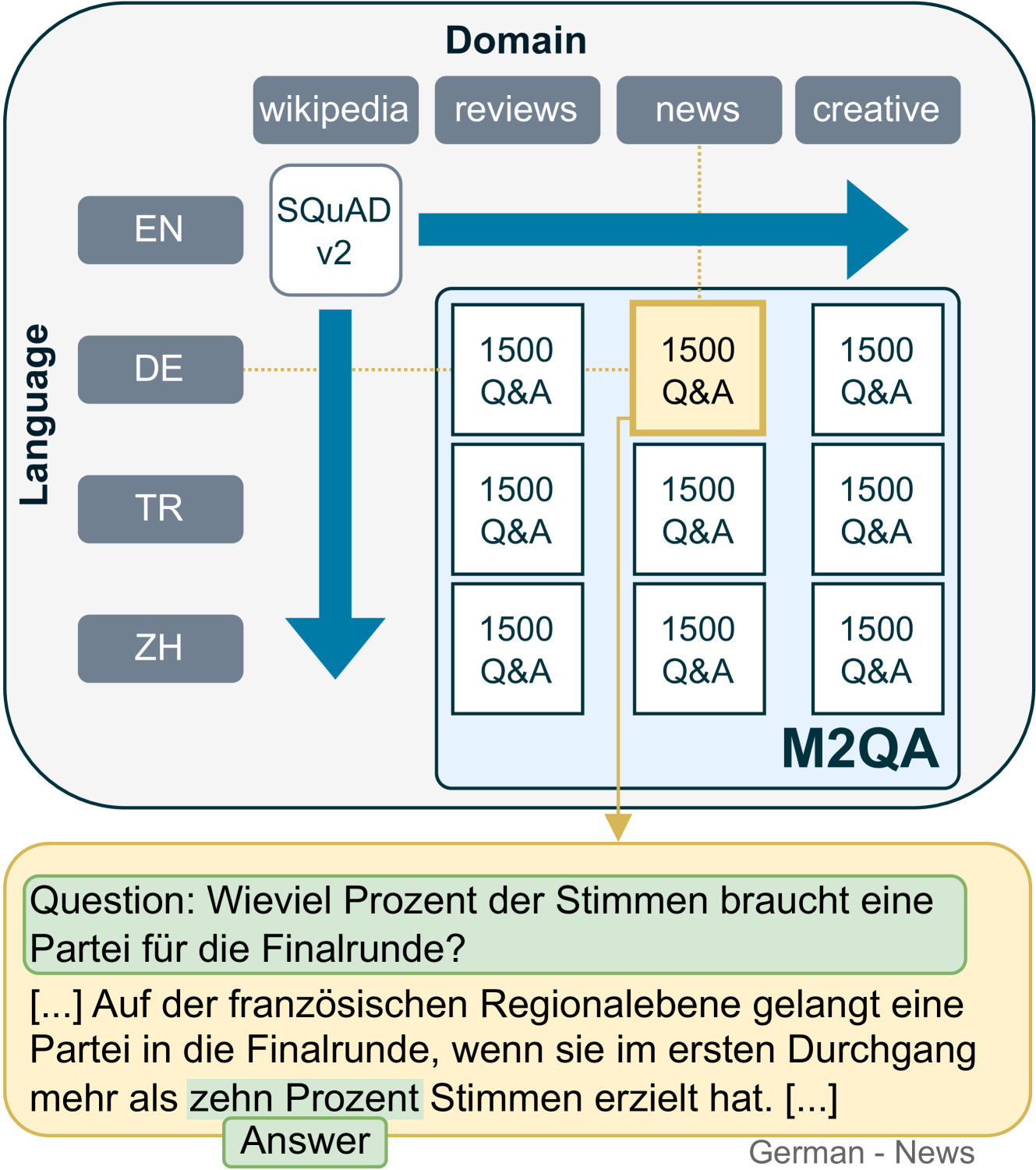
Generalization and robustness to input variation are core desiderata of machine learning research. Language varies along several axes, most importantly, language instance (e.g. French) and domain (e.g. news). While adapting NLP models to new languages within a single domain, or to new domains within a single language, is widely studied, research in joint adaptation is hampered by the lack of evaluation datasets. This prevents the transfer of NLP systems from well-resourced languages and domains to non-dominant language-domain combinations. To address this gap, we introduce M2QA, a multi-domain multilingual question answering benchmark. M2QA includes 13,500 SQuAD 2.0-style question-answer instances in German, Turkish, and Chinese for the domains of product reviews, news, and creative writing. We use M2QA to explore cross-lingual cross-domain performance of fine-tuned models and state-of-the-art LLMs and investigate modular approaches to domain and language adaptation. We witness 1) considerable performance variations across domain-language combinations within model classes and 2) considerable performance drops between source and target language-domain combinations across all model sizes. We demonstrate that M2QA is far from solved, and new methods to effectively transfer both linguistic and domain-specific information are necessary. We make M2QA publicly available at https://github.com/UKPLab/m2qa.
7/2/2024
MahaSQuAD: Bridging Linguistic Divides in Marathi Question-Answering
Ruturaj Ghatage, Aditya Kulkarni, Rajlaxmi Patil, Sharvi Endait, Raviraj Joshi
0
0
Question-answering systems have revolutionized information retrieval, but linguistic and cultural boundaries limit their widespread accessibility. This research endeavors to bridge the gap of the absence of efficient QnA datasets in low-resource languages by translating the English Question Answering Dataset (SQuAD) using a robust data curation approach. We introduce MahaSQuAD, the first-ever full SQuAD dataset for the Indic language Marathi, consisting of 118,516 training, 11,873 validation, and 11,803 test samples. We also present a gold test set of manually verified 500 examples. Challenges in maintaining context and handling linguistic nuances are addressed, ensuring accurate translations. Moreover, as a QnA dataset cannot be simply converted into any low-resource language using translation, we need a robust method to map the answer translation to its span in the translated passage. Hence, to address this challenge, we also present a generic approach for translating SQuAD into any low-resource language. Thus, we offer a scalable approach to bridge linguistic and cultural gaps present in low-resource languages, in the realm of question-answering systems. The datasets and models are shared publicly at https://github.com/l3cube-pune/MarathiNLP .
4/23/2024
💬
LibriSQA: A Novel Dataset and Framework for Spoken Question Answering with Large Language Models
Zihan Zhao, Yiyang Jiang, Heyang Liu, Yanfeng Wang, Yu Wang
0
0
While Large Language Models (LLMs) have demonstrated commendable performance across a myriad of domains and tasks, existing LLMs still exhibit a palpable deficit in handling multimodal functionalities, especially for the Spoken Question Answering (SQA) task which necessitates precise alignment and deep interaction between speech and text features. To address the SQA challenge on LLMs, we initially curated the free-form and open-ended LibriSQA dataset from Librispeech, comprising Part I with natural conversational formats and Part II encompassing multiple-choice questions followed by answers and analytical segments. Both parts collectively include 107k SQA pairs that cover various topics. Given the evident paucity of existing speech-text LLMs, we propose a lightweight, end-to-end framework to execute the SQA task on the LibriSQA, witnessing significant results. By reforming ASR into the SQA format, we further substantiate our framework's capability in handling ASR tasks. Our empirical findings bolster the LLMs' aptitude for aligning and comprehending multimodal information, paving the way for the development of universal multimodal LLMs. The dataset and demo can be found at https://github.com/ZihanZhaoSJTU/LibriSQA.
4/19/2024
↗️
UQA: Corpus for Urdu Question Answering
Samee Arif, Sualeha Farid, Awais Athar, Agha Ali Raza
0
0
This paper introduces UQA, a novel dataset for question answering and text comprehension in Urdu, a low-resource language with over 70 million native speakers. UQA is generated by translating the Stanford Question Answering Dataset (SQuAD2.0), a large-scale English QA dataset, using a technique called EATS (Enclose to Anchor, Translate, Seek), which preserves the answer spans in the translated context paragraphs. The paper describes the process of selecting and evaluating the best translation model among two candidates: Google Translator and Seamless M4T. The paper also benchmarks several state-of-the-art multilingual QA models on UQA, including mBERT, XLM-RoBERTa, and mT5, and reports promising results. For XLM-RoBERTa-XL, we have an F1 score of 85.99 and 74.56 EM. UQA is a valuable resource for developing and testing multilingual NLP systems for Urdu and for enhancing the cross-lingual transferability of existing models. Further, the paper demonstrates the effectiveness of EATS for creating high-quality datasets for other languages and domains. The UQA dataset and the code are publicly available at www.github.com/sameearif/UQA.
5/3/2024